Clear Sky Science · es
Procesamiento de la información de las inscripciones oraculares: una revisión completa
Huesos antiguos, preguntas modernas
Hace más de 3.000 años, adivinos en China grababan preguntas dirigidas a sus gobernantes en caparazones de tortuga y huesos de buey, y luego los fracturaban con calor para leer los presagios. Estas inscripciones oraculares son la escritura china más antigua conocida y una rara ventana a la política, la religión y la vida cotidiana de la Edad del Bronce. Hoy, sin embargo, los huesos están muy fragmentados, la escritura es difícil de leer y muchos signos siguen sin descifrarse. Este artículo explica cómo nuevas oleadas de inteligencia artificial están transformando la manera en que los estudiosos limpian, reconstruyen, leen e interpretan estos frágiles vestigios del pasado, y qué desafíos aún quedan por delante.
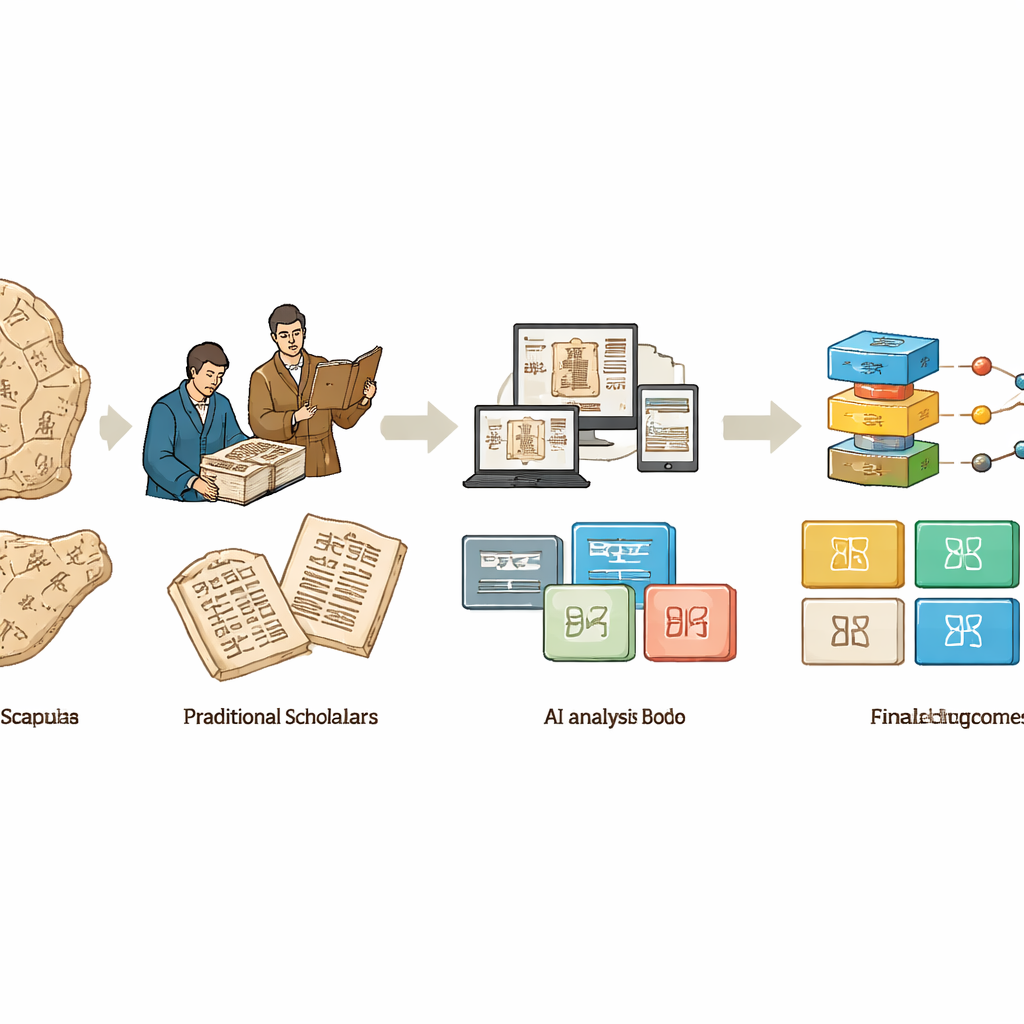
De la mano y el ojo al silicio y el código
Durante la mayor parte del siglo pasado, los huesos oraculares solo podían ser estudiados por un reducido círculo de expertos que examinaban minuciosamente frottages, calcos y fotografías. Collacionaban voluminosos catálogos impresos, proponían lecturas de caracteres individuales y debatían cómo debían fecharse y agruparse las inscripciones. Este trabajo cimentó los fundamentos del campo, pero era lento, difícil de reproducir y dependía en gran medida de la memoria y el juicio personal de cada estudioso. Con la llegada de los ordenadores, los investigadores empezaron a digitalizar los frottages y a aplicar trucos básicos de procesamiento de imágenes como el aumento de contraste y la detección de bordes. Estas primeras herramientas facilitaron la visualización y el intercambio de los huesos, pero trataron los caracteres como meras formas, no como escritura con significado.
El aprendizaje profundo entra en los archivos
El auge del aprendizaje profundo cambió el panorama. Redes neuronales convolucionales y transformadores, afinados inicialmente con fotografías cotidianas, fueron reentrenados para detectar caracteres en frottages ruidosos, clasificarlos en categorías e incluso ayudar a emparejar fragmentos rotos que antes pertenecían al mismo hueso. Para alimentar estos modelos necesitados de datos, los equipos compilaron docenas de conjuntos de datos especializados: algunos se centraron en identificar cada carácter en un frottage, otros en clasificar glifos recortados, vincular radicales y componentes, o emparejar formas antiguas con escrituras posteriores. Pero los datos reflejan la realidad histórica: unos pocos caracteres comunes aparecen miles de veces, mientras que muchos signos raros o sin descifrar aparecen solo una vez. Los investigadores responden con ingeniosas técnicas de aumento de datos, modelos generativos que sintetizan nuevos ejemplos y esquemas de entrenamiento diseñados para reconocer caracteres a partir de unas pocas —o ninguna— muestras conocidas.
Enseñar a las máquinas a unir visión y significado
En la fase más reciente, se están adaptando al corpus de huesos oraculares grandes modelos multimodales que combinan visión y lenguaje. En lugar de limitarse a detectar dónde están los caracteres, estos sistemas intentan conectar la apariencia de un glifo con lo que podría significar, de manera similar a como lo hace un paleógrafo humano. Nuevos puntos de referencia ponen a prueba si tales modelos pueden reconocer caracteres, recomponer fragmentos, recuperar inscripciones similares y sugerir lecturas plausibles. Algunos marcos intentan mapear signos antiguos directamente sobre caracteres chinos modernos, trazando la evolución visual a lo largo de siglos; otros vinculan signos pictóricos con imágenes de objetos reales; y otros intentan explicaciones textuales completas de lo que podría decir una línea de adivinación. Sistemas al estilo agente van más allá orquestando múltiples herramientas y bases de datos, ayudando a los usuarios a buscar entre imágenes, transcripciones y notas académicas en un solo flujo de trabajo.
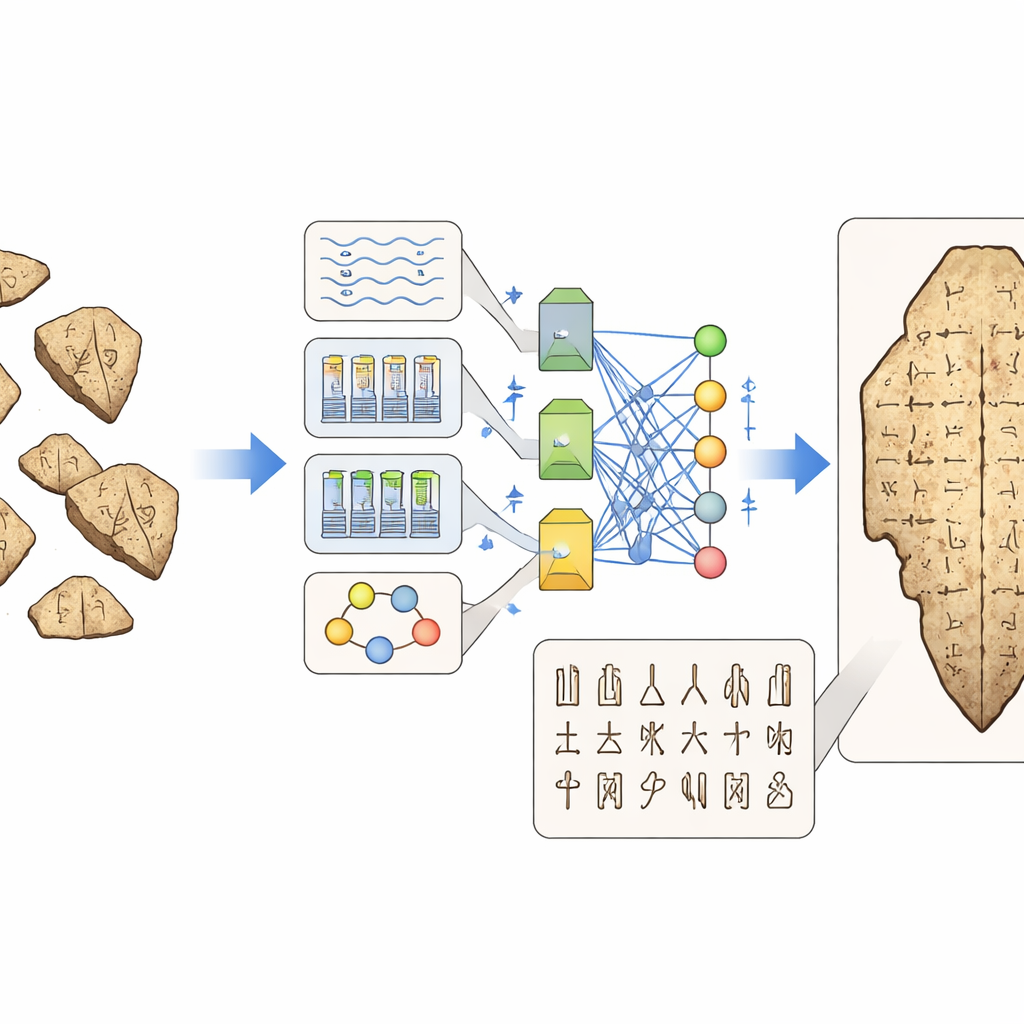
Datos, evaluación y el rompecabezas de la historia fragmentada
A pesar del rápido progreso, la revisión subraya obstáculos persistentes. Muchas de las mejores colecciones de imágenes y escaneos 3D están en museos o archivos privados y no son accesibles públicamente, lo que dificulta comparar métodos con justicia o entrenar modelos verdaderamente generales. Incluso los conjuntos de datos públicos suelen presentar distribuciones de clases de cola larga, etiquetas inconsistentes o baja calidad de imagen. Las métricas de rendimiento estándar, tomadas de detección de objetos o reconocimiento de escritura, pueden no captar lo que realmente importa a los historiadores —por ejemplo, si un modelo confunde dos variantes aceptadas de un mismo carácter, o si la lectura propuesta respeta la composición de un signo a partir de sus partes—. La evaluación humana está igualmente fragmentada: diferentes estudios reclutan distintos tipos de expertos, formulan preguntas distintas y rara vez informan con suficiente detalle para que otros reproduzcan sus pruebas.
Donde la escritura antigua se encuentra con la IA del futuro
Para avanzar, los autores abogan por conjuntos de datos más ricos y mejor documentados; métodos de evaluación que recompensen la comprensión estructural y semántica, no solo las coincidencias a nivel de píxel; y una colaboración más estrecha entre tecnólogos y especialistas en escritura china antigua. Visualizan generadores de texto a imagen capaces de producir caracteres con estilo oracular realistas a partir de descripciones, modelos fundamentales entrenados específicamente en escrituras antiguas, sistemas multiagente que debatan y refinen lecturas en competencia, e incluso reconstrucciones 3D que restauren la forma original de los huesos fragmentados. En términos sencillos, la conclusión del artículo es que la IA no “resolverá” por sí sola las inscripciones oraculares, pero puede convertirse en una pareja poderosa: amplificando la visión experta, haciendo que vastos archivos sean buscables y abriendo las voces de la Edad del Bronce a un público mucho más amplio.
Cita: Chen, Z., Hua, W., Li, J. et al. Oracle bone inscriptions information processing: a comprehensive survey. npj Herit. Sci. 14, 220 (2026). https://doi.org/10.1038/s40494-026-02511-w
Palabras clave: inscripciones oraculares, escritura china antigua, humanidades digitales, inteligencia artificial, modelos multimodales