Clear Sky Science · tr
Dağılım kayması altında yoğun bakım ünitelerinde derin öğrenme sepsis tahmin modellerinin değerlendirilmesi: çok merkezli retrospektif kohort çalışması
Enfeksiyon için erken uyarının önemi
Sepsis, enfeksiyona karşı hızla ilerleyen ve hayatı tehdit eden bir tepki olup yoğun bakım ünitelerinde önde gelen ölüm nedenlerinden biridir. Hastaneler, sepsisin doktorlar tarafından açıkça görülmesinden saatler önce monitörler ve laboratuvar testlerindeki ince uyarı işaretlerini tespit etmek için yapay zekaya yöneliyor. Ancak bir sorun var: bir hastanede iyi çalışan bir algoritma, hastalar, ekipman ve kayıt tutma uygulamaları yerden yere farklı olduğundan başka bir hastanede başarısız olabiliyor. Bu çalışma, gerçek dünya bakımına yönelik pratik bir soru soruyor: bu farklılıklar varken bir sepsis tahmin modelini yeni bir yoğun bakım ünitesine taşıdığınızda modeli yeniden kullanmanın veya uyarlamanın en akıllıca yolu nedir?
Hastane verileri nasıl sessizce değişebilir
Araştırmacılar, yoğun bakım verilerinin hastaneler arasında ne kadar farklı görünebileceğini göstererek başladılar. Aynı hayati bulguları ve laboratuvar sonuçlarını zaman içinde izlemek üzere özenle uyumlaştırılmış ABD ve İsviçre’den üç büyük yoğun bakım veri tabanını karşılaştırdılar. Bu uyumlaştırmadan sonra bile, kan basıncı, oksijen düzeyleri ve belirli kan sayımları gibi 48 ölçülen işaretten birçoğu sahalar arasında belirgin şekilde farklı desenler gösteriyordu. İstatistiksel testler, her hastane çifti için onlarca değişkenin farklı dağılımlar izlediğini ve bazı özelliklerin her veri kümesinde benzersiz davrandığını ortaya koydu. Genel hatlarıyla, iki Amerikan veri kümesi birbirine İsviçre verisinden daha çok benziyordu; bu da ulusal uygulama alışkanlıkları ve ölçüm yöntemlerinin algoritmaların yorumlaması gereken veride bir parmak izi bıraktığını vurguluyor.
Çok sayıda yoğun bakım ünitesinde yapay zekanın test edilmesi
Bu farklılıklar belirlendikten sonra ekip, sepsisi resmi tanıdan yaklaşık altı saat önce tahmin etmek için üç tür derin öğrenme modeli eğitti. Ardından bir modelin bir yoğun bakımda eğitilip başka birinde doğrudan kullanıldığında ne olduğunu test ettiler. Genel olarak, modeller makul derecede iyi transfer oldu; özellikle hedef yoğun bakım ünitesinin kendi başına çok az verisi olduğunda. Örneğin, yerel kayıtların sadece küçük bir kısmı mevcut olduğunda, başka bir yerde önceden eğitilmiş bir modeli kullanmak, sıfırdan yeni bir model eğitmekten daha iyi performans gösterdi. Konvolüsyonel sinir ağları sahalar arasında en kararlı olanlardı. Daha fazla yerel veri eklendikçe performans istikrarlı şekilde yükseldi ve sonunda düzleşti; bazı hastaneler (özellikle büyük Amerikan çok merkezli veri kümesi) diğerlerinden daha kolay modellenebiliyordu.
Bir modeli taşımak için farklı yollar denemek
Sonra yazarlar, bir hastane kademeli olarak kendi verilerini biriktirirken bu modelleri dağıtmak için pratik stratejileri karşılaştırdı. Beş seçeneği incelediler: orijinal modeli olduğu gibi yeniden kullanmak; sadece son katmanlarını ince ayar yapmak; yerel verilerle tüm katmanlarını tamamen yeniden eğitmek; yalnızca yerel verilerle tamamen yeni bir model eğitmek; ve kaynak ile hedef hastanelerin iç özelliklerini hizalamaya zorlayan iki tür "alan uyarlaması". Hedef hastaneleri küçük, orta ve büyük veri rejimlerinde gruplayıp karşılaştırmayı birkaç kaynak–hedef çifti ve model türü arasında tekrarladılar. Bu sistematik yaklaşım, birkaç olguya sahip küçük kırsal bir yoğun bakımdan on binlerce yatışı havuzlayan ulusal bir ağa kadar gerçek dünya yaygınlaştırmalarını taklit etti.
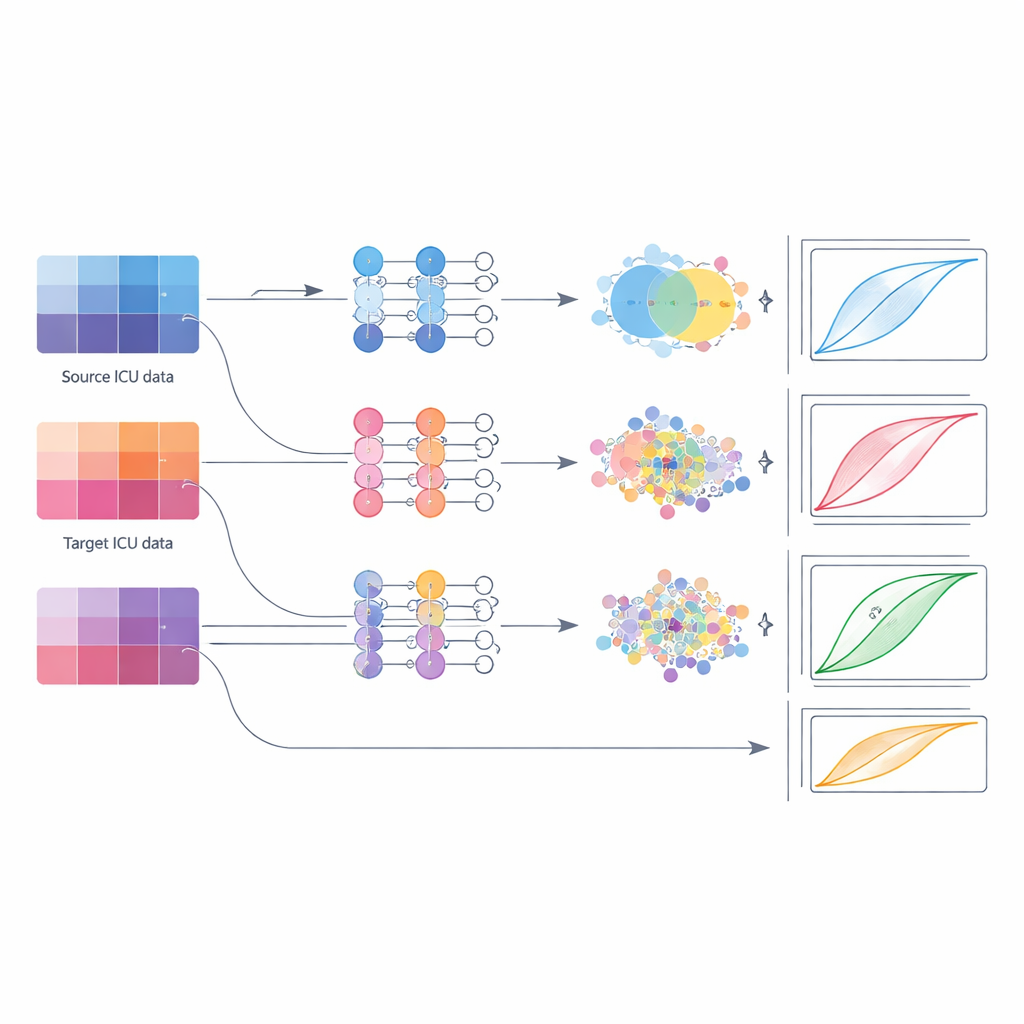
Farklı veri ölçeklerinde en iyi ne işe yarar
Sonuçlar, basit ince ayara dayanma alışkanlığını sorgulatıyor. Koşulların çoğunda, ince ayar genellikle diğer yöntemlerin gerisinde kaldı. Hedef yoğun bakımda sadece az sayıda olgu olduğunda en iyi seçenek, dışarıdaki modelden başlamak ve ardından tüm katmanlarını yerel veride yeniden eğitmektir; kaynak ve hedef veriyi tek bir eğitim havuzunda birleştirmek (fizyon) ikinci en iyi seçenektir. Orta büyüklükteki veri kümeleri için, modelin her iki hastanenin özellik desenlerinin daha iyi örtüşmesini sağlamak üzere itildiği alan uyarlaması yöntemleri en güvenilir kazanımları verdi; ayırma (discriminasyon) ölçütlerini artırırken değişkenliği düşük tuttu. Hedef yoğun bakım büyük bir veri kümesi oluşturduğunda ise, tamamen veya büyük oranda o yerel verilerle eğitilmiş modeller bazen ek füzyonla birlikte, transfer tabanlı tüm yaklaşımları yakaladı veya geride bıraktı.
Hasta bakımı için anlamı
Uzman olmayanlar için ana mesaj, hastaneler arasında sepsis için yapay zekayı dağıtmanın tek beden herkese uyar bir yolu olmadığıdır. Her yoğun bakımın kendi "veri aksanı" olduğundan, bir modeli olduğu gibi içeri aktarmak ve son katmanını hafifçe ayarlamak—sık kullanılan bir kestirme—performansı düşürebilir veya klinisyenleri yanıltabilir. Bunun yerine çalışma basit bir yol haritası öneriyor: veri çok kısıtlıysa dışsal bir modelden başlayıp onu kapsamlı şekilde yeniden eğitin; daha fazla yerel vaka biriktikçe, hastaneler arasındaki farklılıklara saygı gösteren alan farkındalıklı eğitime geçin; ve büyük yerel veri kümeleri mevcut olduğunda önceliği esas olarak o yerel deneyime dayanan modellere verin. Bu ilkeleri takip etmek, hastanelerin sepsis tahmin araçlarını daha hızlı çevrimiçi hale getirmesine yardımcı olurken uyarıların daha güvenilir ve kendi hastalarına daha iyi uyarlanmış olmasını sağlayabilir.
Atıf: Tranchellini, F., Farag, Y., Jutzeler, C. et al. Evaluating deep learning sepsis prediction models in ICUs under distribution shift: a multi-centre retrospective cohort study. npj Digit. Med. 9, 306 (2026). https://doi.org/10.1038/s41746-026-02364-4
Anahtar kelimeler: sepsis tahmini, yoğun bakım, derin öğrenme, alan uyarlaması, dağılım kayması