Clear Sky Science · ru
Оценка моделей глубокого обучения для прогнозирования сепсиса в ОРИТ при сдвиге распределения: многоцентровое ретроспективное когортное исследование
Почему важно раннее предупреждение об инфекции
Сепсис — это быстро развивающаяся, угрожающая жизни реакция на инфекцию и одна из ведущих причин смертности в отделениях интенсивной терапии. Больницы обращаются к искусственному интеллекту, чтобы выявлять тонкие признаки на мониторах и в лабораторных тестах за часы до того, как сепсис станет очевиден врачам. Но есть загвоздка: алгоритм, хорошо работающий в одной больнице, часто дает сбои в другой, потому что пациенты, оборудование и ведение записей различаются. В этом исследовании поставлен практический вопрос для повседневной помощи: учитывая эти различия, какой самый разумный способ повторно использовать или адаптировать модель прогнозирования сепсиса при переходе в новую палату интенсивной терапии?
Как данные больницы могут незаметно меняться
Исследователи начали с демонстрации того, насколько по-разному могут выглядеть данные интенсивной терапии в разных больницах. Они сравнили три большие базы данных ИТ-отделений из США и Швейцарии, все тщательно гармонизированные для отслеживания одинаковых жизненных показателей и результатов лабораторий во времени. Даже после такой гармонизации многие из 48 измеряемых сигналов — такие как артериальное давление, уровень кислорода и некоторые показатели крови — имели заметно разные паттерны между площадками. Статистические тесты показали, что в каждой паре больниц десятки переменных следуют различным распределениям, а некоторые признаки вели себя уникально в каждом наборе данных. В общих чертах два американских набора данных были более похожи друг на друга, чем на швейцарский, что подчеркивает: национальные практики и привычки измерений оставляют отпечаток в данных, который алгоритмы должны учитывать.
Тестирование ИИ в нескольких отделениях интенсивной терапии
Имея эти различия в виду, команда обучила три типа моделей глубокого обучения предсказывать сепсис примерно за шесть часов до официальной диагностики. Затем они проверили, что происходит, когда модель, обученная в одной ИТ-палате, применяется напрямую в другой. В целом модели переносились достаточно хорошо, особенно когда в целевой ИТ-палате было очень мало собственных данных. Например, при наличии лишь небольшой доли локальных записей использование предобученной модели из другого места опережало обучение новой модели с нуля. Сверточные нейронные сети оказались наиболее стабильными между площадками. С по мере добавления локальных данных производительность стабильно росла и в итоге выравнивалась; некоторые больницы (особенно крупный американский многоцентровый набор) моделировались легче, чем другие.
Попытки разных способов переноса модели
Далее авторы сравнили практические стратегии развертывания этих моделей по мере того, как больница постепенно накапливает собственные данные. Они рассмотрели пять вариантов: простое повторное использование оригинальной модели «как есть»; дообучение только её последних слоев; полная дообучка всех слоев на локальных данных; обучение совершенно новой модели лишь на локальных данных; и два варианта «адаптации домена», которые явно приводят внутренние признаки модели из источника и цели к большему совпадению. Они сгруппировали целевые больницы по режимам с малым, средним и большим объёмом данных и повторили сравнение для нескольких пар источник–цель и типов моделей. Этот системный подход имитировал реальное развертывание — от небольшой сельской ИТ-палаты с горсткой случаев до национальной сети, объединяющей десятки тысяч госпитализаций.
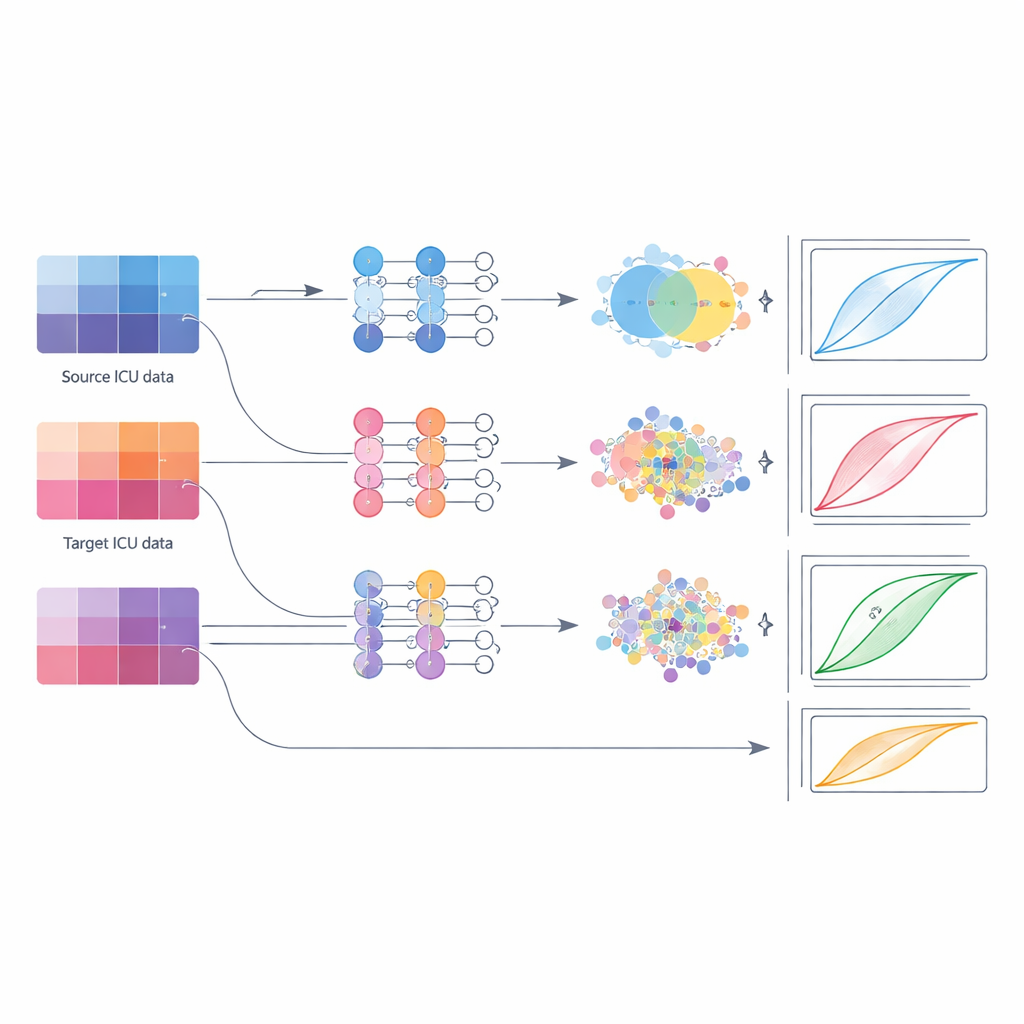
Что работает лучше при разных объёмах данных
Результаты ставят под сомнение привычку полагаться на простое дообучение. Во всех условиях дообучение обычно отставало от других методов. Когда в целевой ИТ-палате было лишь немного случаев, лучшим вариантом было инициализировать модель внешней версией, а затем полностью дообучить все её слои на локальных данных; объединение данных источника и цели в единый пул для обучения (fusion) занимало близкое второе место. Для наборов среднего объёма методы адаптации домена — то есть техники, которые подтягивают характеристики так, чтобы паттерны признаков из обеих больниц перекрывались сильнее — давали наиболее надежные улучшения, повышая метрики дискриминации и снижая вариативность. Как только в целевой ИТ-палате накопился большой набор данных, модели, обученные полностью или преимущественно на этих локальных данных, иногда с дополнительной фузией, сравнялись или превзошли все подходы, основанные на переносе.
Что это означает для ухода за пациентами
Главное сообщение для неспециалистов: нет универсального способа развертывания ИИ для сепсиса в разных больницах. Поскольку у каждой ИТ-палаты свой «акцент» в данных, простая импортная модель с дообучением только последнего слоя — распространённый короткий путь — может оставить производительность на столе или даже ввести клиницистов в заблуждение. Вместо этого исследование предлагает простую практическую схему: в условиях крайней нехватки данных начинать с внешней модели и тщательно её дообучивать; по мере накопления локальных случаев переходить к методам, учитывающим различия между больницами; а при наличии больших локальных наборов данных отдавать приоритет моделям, в основном построенным на местном опыте. Следование этим принципам поможет больницам быстрее вводить инструменты прогнозирования сепсиса в эксплуатацию, делая их предупреждения более надёжными и лучше адаптированными к собственным пациентам.
Цитирование: Tranchellini, F., Farag, Y., Jutzeler, C. et al. Evaluating deep learning sepsis prediction models in ICUs under distribution shift: a multi-centre retrospective cohort study. npj Digit. Med. 9, 306 (2026). https://doi.org/10.1038/s41746-026-02364-4
Ключевые слова: прогнозирование сепсиса, реанимация, глубокое обучение, адаптация домена, сдвиг распределения