Clear Sky Science · pl
Ocena modeli głębokiego uczenia przewidujących sepsę na OIOM-ach przy zmianie rozkładu danych: wieloośrodkowe retrospektywne badanie kohortowe
Dlaczego wczesne ostrzeganie przed zakażeniem jest istotne
Sepsa to gwałtowna, zagrażająca życiu reakcja na zakażenie i jedna z głównych przyczyn zgonów na oddziałach intensywnej terapii. Szpitale sięgają po sztuczną inteligencję, by wychwycić subtelne sygnały w monitorach i wynikach badań godzinami przed tym, gdy sepsa stanie się oczywista dla lekarzy. Jest jednak problem: algorytm działający dobrze w jednym szpitalu często zawodzi w innym, ponieważ pacjenci, sprzęt i sposób prowadzenia dokumentacji różnią się w zależności od miejsca. To badanie stawia praktyczne pytanie ważne dla opieki klinicznej: biorąc pod uwagę te różnice, jaki jest najrozsądniejszy sposób ponownego użycia lub adaptacji modelu przewidującego sepsę po przeniesieniu go do nowego OIOM-u?
Jak dane szpitalne mogą się po cichu zmieniać
Badacze zaczęli od pokazania, jak bardzo dane z intensywnej opieki mogą się różnić między szpitalami. Porównali trzy duże bazy danych z OIOM-ów ze Stanów Zjednoczonych i Szwajcarii, wszystkie starannie zharmonizowane, aby śledzić te same parametry życiowe i wyniki badań laboratoryjnych w czasie. Nawet po tej harmonizacji wiele z 48 mierzonych sygnałów — takich jak ciśnienie krwi, poziom tlenu czy niektóre parametry morfologii krwi — miało wyraźnie różne wzorce między ośrodkami. Testy statystyczne wykazały, że w każdej parze szpitali dziesiątki zmiennych miały odrębne rozkłady, a niektóre cechy zachowywały się unikalnie w danym zbiorze danych. W dużym uproszczeniu, dwa amerykańskie zbiory przypominały się bardziej nawzajem niż którykolwiek z nich przypominał ten szwajcarski, co podkreśla, że krajowe praktyki i zwyczaje pomiarowe odciskają na danych specyficzne cechy, które algorytmy muszą uwzględnić.
Testowanie SI w wielu oddziałach intensywnej terapii
Po ustaleniu tych różnic zespół wytrenował trzy typy modeli głębokiego uczenia do przewidywania sepsy około sześć godzin przed formalną diagnozą. Następnie sprawdzili, co się dzieje, gdy model wytrenowany w jednym OIOM-ie jest używany bezpośrednio w innym. Ogólnie modele przenosiły się stosunkowo dobrze, szczególnie gdy docelowy OIOM dysponował bardzo niewielką ilością własnych danych. Na przykład przy dostępności jedynie niewielkiej części lokalnych zapisów użycie modelu wstępnie wytrenowanego w innym ośrodku przeważnie przewyższało trenowanie nowego modelu od zera. Splotowe sieci neuronowe okazały się najbardziej stabilne między ośrodkami. W miarę dodawania większej liczby lokalnych danych wydajność systematycznie rosła i w końcu się stabilizowała, przy czym niektóre szpitale (w szczególności duży amerykański zbiór wieloośrodkowy) były łatwiejsze do modelowania niż inne.
Próbowanie różnych sposobów przenoszenia modelu
Następnie autorzy porównali praktyczne strategie wdrażania tych modeli, gdy szpital stopniowo gromadzi własne dane. Zbadali pięć opcji: po prostu ponowne wykorzystanie oryginalnego modelu bez zmian; dostrajanie tylko jego ostatnich warstw; pełne przeuczenie wszystkich warstw na danych lokalnych; wytrenowanie całkowicie nowego modelu wyłącznie na danych lokalnych; oraz dwie formy „adaptacji domeny”, które explicite powodują, że wewnętrzne cechy modelu ze szpitali źródłowych i docelowych stają się bardziej zbliżone. Podzielili szpitale docelowe na rejony z małą, średnią i dużą ilością danych i powtórzyli porównanie dla kilku par źródło–cel oraz typów modeli. To systematyczne podejście imitowało rzeczywiste wdrożenia — od małego wiejskiego OIOM-u z garstką przypadków po krajową sieć gromadzącą dziesiątki tysięcy pobytów.
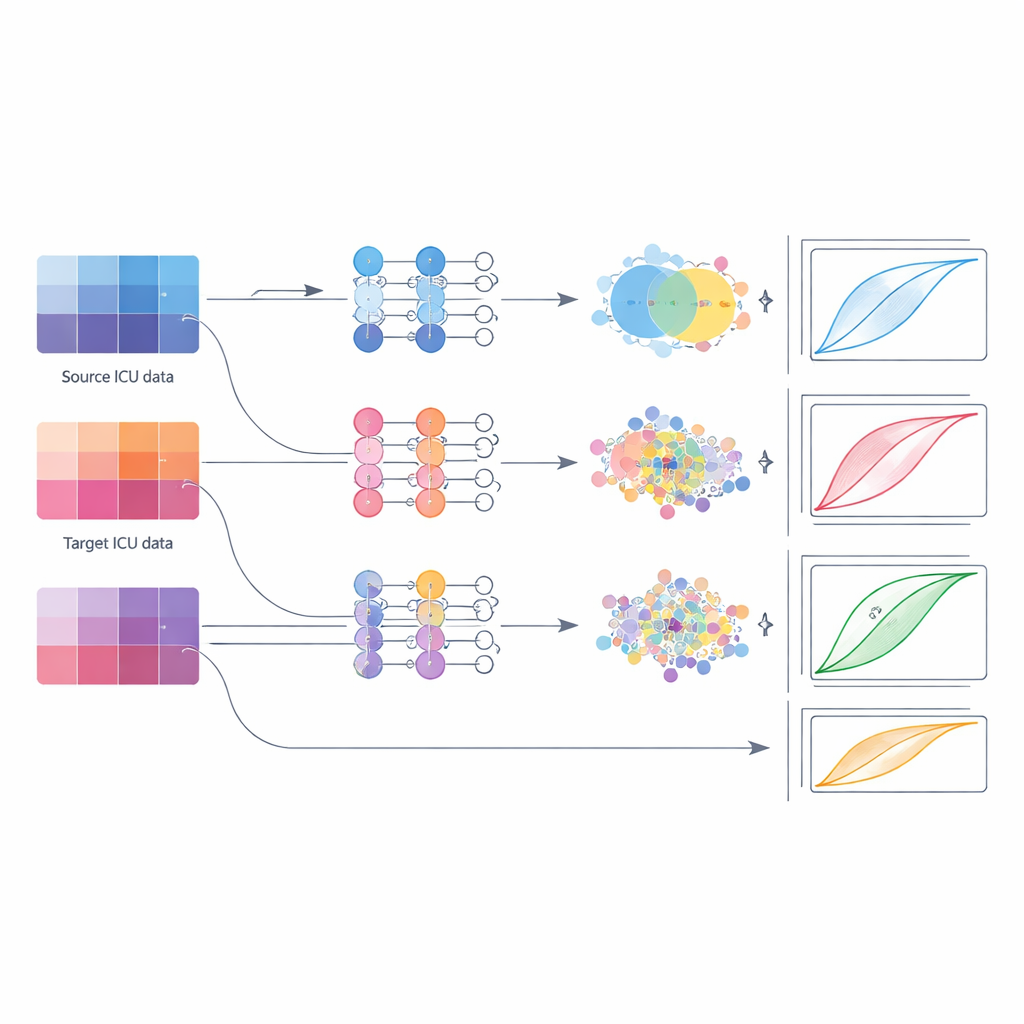
Co działa najlepiej przy różnych skalach danych
Wyniki kwestionują powszechny zwyczaj polegania na prostym dostrajaniu. W różnych warunkach fine-tuning zwykle ustępował miejsca innym metodom. Gdy docelowy OIOM miał tylko niewielką liczbę przypadków, najlepszą opcją było zainicjowanie modelu modelem z zewnątrz, a następnie ponowne wytrenowanie wszystkich jego warstw na lokalnych danych; łączenie danych źródłowych i docelowych w jedno środowisko treningowe (fusion) było bliskim drugim wyborem. Dla zbiorów o średniej wielkości metody adaptacji domeny — techniki, które zbliżają wzorce cech z obu szpitali — przynosiły najbardziej wiarygodne korzyści, poprawiając miary rozróżniania przy zachowaniu niskiej zmienności. Gdy docelowy OIOM zgromadził duży zbiór danych, modele wytrenowane w całości lub w dużej mierze na tych lokalnych danych, czasem z dodatkowym fusion, dorównywały lub przewyższały wszystkie podejścia oparte na transferze.
Co to oznacza dla opieki nad pacjentem
Dla osób niebędących specjalistami kluczowe przesłanie jest takie, że nie istnieje uniwersalne rozwiązanie wdrożenia SI dla sepsy w różnych szpitalach. Ponieważ każdy OIOM ma swój własny „akcent danych”, proste zaimportowanie modelu i dostrojenie jego ostatniej warstwy — powszechny skrót — może pozostawić wydajność niewykorzystaną lub nawet wprowadzić w błąd klinicystów. Zamiast tego badanie sugeruje prosty plan działania: w bardzo ubogich danych ustawieniach rozpocząć od zewnętrznego modelu i gruntownie go przeuczyć; w miarę gromadzenia lokalnych przypadków przejść do treningu uwzględniającego różnice między szpitalami; a gdy istnieją duże lokalne zbiory danych, priorytetowo traktować modele budowane głównie na tym lokalnym doświadczeniu. Stosowanie tych zasad może pomóc szpitalom szybciej uruchomić narzędzia do przewidywania sepsy, jednocześnie utrzymując ostrzeżenia bardziej wiarygodne i lepiej dopasowane do ich własnych pacjentów.
Cytowanie: Tranchellini, F., Farag, Y., Jutzeler, C. et al. Evaluating deep learning sepsis prediction models in ICUs under distribution shift: a multi-centre retrospective cohort study. npj Digit. Med. 9, 306 (2026). https://doi.org/10.1038/s41746-026-02364-4
Słowa kluczowe: predykcja sepsy, intensywna opieka, głębokie uczenie, adaptacja domeny, zmiana rozkładu