Clear Sky Science · en
Evaluating deep learning sepsis prediction models in ICUs under distribution shift: a multi-centre retrospective cohort study
Why early warning for infection matters
Sepsis is a fast-moving, life-threatening reaction to infection and one of the leading killers in intensive care units. Hospitals are turning to artificial intelligence to spot subtle warning signs in monitors and lab tests hours before sepsis becomes obvious to doctors. But there is a catch: an algorithm that works well in one hospital often stumbles in another, because patients, equipment, and record-keeping differ from place to place. This study asks a practical question for real-world care: given those differences, what is the smartest way to reuse or adapt a sepsis prediction model when you bring it to a new ICU?
How hospital data can quietly change
The researchers began by showing just how different intensive care data can look across hospitals. They compared three large ICU databases from the United States and Switzerland, all carefully harmonized to track the same vital signs and lab results over time. Even after this harmonization, many of the 48 measured signals—such as blood pressure, oxygen levels, and certain blood counts—had noticeably different patterns between sites. Statistical tests revealed that in every pair of hospitals, dozens of variables followed distinct distributions, and some features behaved uniquely in each dataset. In broad strokes, the two American datasets resembled each other more than either resembled the Swiss one, underlining that national practice patterns and measurement habits leave a fingerprint on the data that algorithms must interpret.
Testing AI across multiple intensive care units
With those differences established, the team trained three types of deep learning models to predict sepsis about six hours before it was formally diagnosed. They then tested what happens when a model trained in one ICU is used directly in another. Overall, models transferred reasonably well, especially when the target ICU had very little data of its own. For example, when only a small fraction of local records was available, using a model pre-trained elsewhere beat training a new model from scratch. Convolutional neural networks were the most stable across sites. As more local data were added, performance steadily rose and eventually leveled off, with some hospitals (particularly the large American multi-center dataset) easier to model than others.
Trying different ways to move a model
Next, the authors compared practical strategies for deploying these models when a hospital gradually accumulates its own data. They examined five options: simply reusing the original model as-is; fine-tuning only its last layers; fully retraining all its layers using local data; training a completely new model on the local data alone; and two forms of "domain adaptation" that explicitly push the model’s internal features from source and target hospitals to align. They grouped target hospitals into small, medium, and large data regimes and repeated the comparison across several source–target pairs and model types. This systematic approach mimicked real-world rollouts, from a small rural ICU with a handful of cases to a national network pooling tens of thousands of stays.
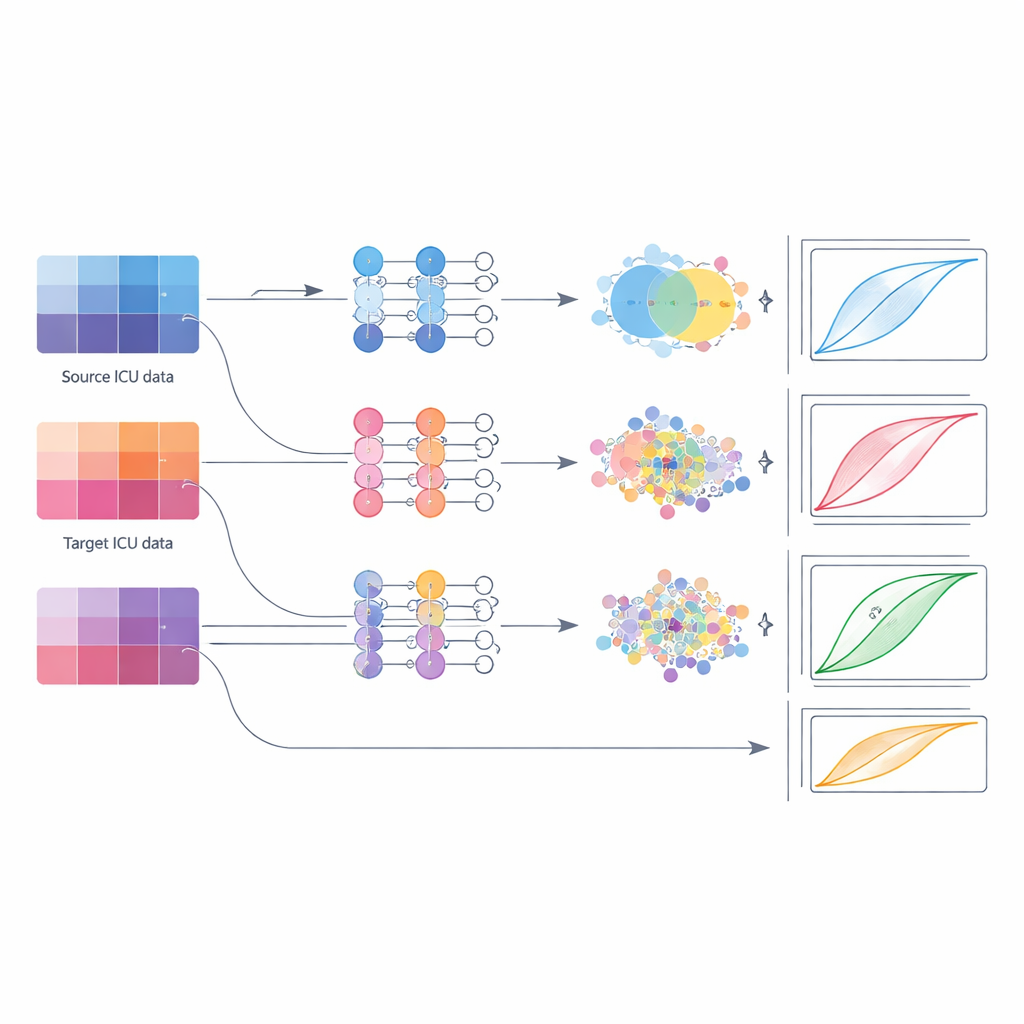
What works best at different data scales
The results challenge the common habit of relying on simple fine-tuning. Across conditions, fine-tuning usually lagged behind other methods. When the target ICU had only a small number of cases, the best option was to initialize from the outside model and then retrain all of its layers on the local data; combining source and target data into a single training pool (fusion) was a close second. For medium-sized datasets, domain adaptation methods—here, techniques that nudge the model so that feature patterns from both hospitals overlap more closely—gave the most reliable gains, boosting discrimination metrics while keeping variability low. Once the target ICU amassed a large dataset, models trained fully or largely on that local data, sometimes with additional fusion, matched or beat all transfer-based approaches.
What this means for patient care
For non-specialists, the key message is that there is no one-size-fits-all way to deploy AI for sepsis across hospitals. Because each ICU has its own "data accent," simply importing a model and nudging its final layer—a common shortcut—may leave performance on the table or even mislead clinicians. Instead, the study suggests a simple playbook: in very data-poor settings, start from an external model and retrain it thoroughly; as more local cases accumulate, switch to domain-aware training that respects differences between hospitals; and when large local datasets exist, prioritize models built mainly on that local experience. Following these principles can help hospitals bring sepsis prediction tools online sooner, while keeping their alerts more trustworthy and better tailored to their own patients.
Citation: Tranchellini, F., Farag, Y., Jutzeler, C. et al. Evaluating deep learning sepsis prediction models in ICUs under distribution shift: a multi-centre retrospective cohort study. npj Digit. Med. 9, 306 (2026). https://doi.org/10.1038/s41746-026-02364-4
Keywords: sepsis prediction, intensive care, deep learning, domain adaptation, distribution shift