Clear Sky Science · tr
Kullanıcı davranışı ataleti esaslı uzamsal-zamansal bir sonraki POI öneri modeli
Neden favori mekanlarınız sürekli ön plana çıkıyor
Harita veya inceleme uygulamalarını kullanan herkes, aynı kafelerin, spor salonlarının veya parkların önerilerinin sessizce üstte belirdiğini görmüştür. Bu makale, günlük alışkanlıklarımızın bu önerileri neden şaşırtıcı derecede öngörülebilir kıldığına ve daha akıllı matematiğin dağınık check-in verilerini daha yararlı, daha az rastgele sonraki yer önerilerine nasıl dönüştürebileceğine ışık tutuyor.
Gittiğimiz yerlerin arkasındaki alışkanlıklar
Yazarlar basit bir gözlemle başlıyor: insanlar nadiren bir sonraki duraklarını rastgele seçer. Günlük yaşam yemek, işe gidip gelme, dinlenme veya dışarı çıkma gibi amaçlarla yönlendirilir. Zaman içinde, aynı amaç için benzer yerlere tekrarlanan gidişler yazarların davranış ataleti dediği, tanıdık noktalara doğru varsayılan bir çekim oluşturur. Aynı zamanda, gerçek hayat düzensizdir. Günün saati, mesafe ve yeni bir yer deneme isteği insanları alışılmış seçimlerinden uzaklaştırabilir; bunlar bu ataletin karşı koyduğu dirençler olarak iş görür. Zorluk, bir öneri sisteminin kullanıcının bir sonraki durağını daha güvenilir biçimde tahmin edebilmesi için her iki eğilimi de yakalamaktır.
Günlük amaçlara göre mekanları sıralamak
Engellerden biri, popüler konum tabanlı uygulamaların bile tek tek kişiler için çok seyrek veri içermesidir; her kullanıcı mevcut mekanların yalnızca çok küçük bir kısmını ziyaret eder. Bu sorunu hafifletmek için araştırmacılar ilgi noktalarını dört geniş, sezgisel amaca göre grupluyor: yeme-içme, ulaşım ve konaklama, eğlence ve dışarı çıkma, ve açık hava etkinlikleri. Tek bir mekan birden fazla role hizmet ediyorsa, örneğin bar olup aynı zamanda restoran olan bir yer, birden fazla gruba girebilir. Her kullanıcının geçmişinden ham koordinatlar yerine amaçların bir zaman çizelgesi oluşturuluyor. Basit zaman serisi teknikleri bir kullanıcının hangi amacı ne zaman takip etme olasılığının yüksek olduğunu tahmin ediyor; bu da ayrıntılı puanlama yapılmadan önce aday mekan kümesini keskin biçimde daraltıyor. 
Mesafe ve alışkanlık gücünü birleştirmek
Kullanıcının muhtemel amacını tahmin ettikten sonra model coğrafyaya ve alışılagelmiş davranışa yönelir. İnsanlar genellikle ev veya ofis gibi anahtar konumların merkez görevi gördüğü birkaç tanıdık bölgede hareket etme eğilimindedir. Geçmiş check-in’leri kullanarak, sistem bu merkezlerin nerede olduğunu ve her yakın mekânın ne sıklıkta ziyaret edildiğini öğrenir. Kullanıcının sık kullandığı noktalara daha yakın olan yerler doğal olarak avantaj elde eder; bu, daha uzaklara seyahat etmek için gereken ek çabayı yansıtır. Aynı zamanda model, bir kişinin aynı mekâna ne kadar düzenli döndüğüne ve ziyaretler arasındaki boşlukların genellikle ne kadar uzun olduğuna bakarak davranış ataleti ölçer. Ayrıca bir kişinin aynı amaç için kaç farklı mekân denediğini de dikkate alır: her zaman aynı restoranda yiyen bir alışkanlık sahibi ile sürekli deney yapan biri farklı davranır; her ikisi de sık dışarıda yemek yiyor olsa bile.
Konfor bölgeleri ile merakı dengelemek
Yaklaşımın özü, atalet ve direnci rekabet eden kuvvetler olarak ele almaktır. Bir kullanıcı sıkça ve düzenli zaman aralıklarıyla bir yere geri dönüyorsa model oraya güçlü bir çekim olduğunu varsayar; özellikle de bir sonraki tahmini ziyaret zaman aralığı yaklaşıyorsa. Nadiren ziyaret edilen mekânlar için sistem, bunların kullanıcının mevcut konumuna yakın olup olmadığına ve kullanıcının keşfetmeyi sevdiği daha geniş bir kategori içinde bulunup bulunmadığına bakar. Bu, yalnızca bariz düzenli uğrakları önermekle kalmayıp aynı zamanda tanıdık mahallelerde makul yeni seçenekleri de önermeyi mümkün kılar. Her aday mekan için nihai puan üç bileşenin karışımıdır: tahmin edilen amaç, coğrafi yakınlık ve öğrenilmiş davranış ataleti ile direnç arasındaki güç dengesi. 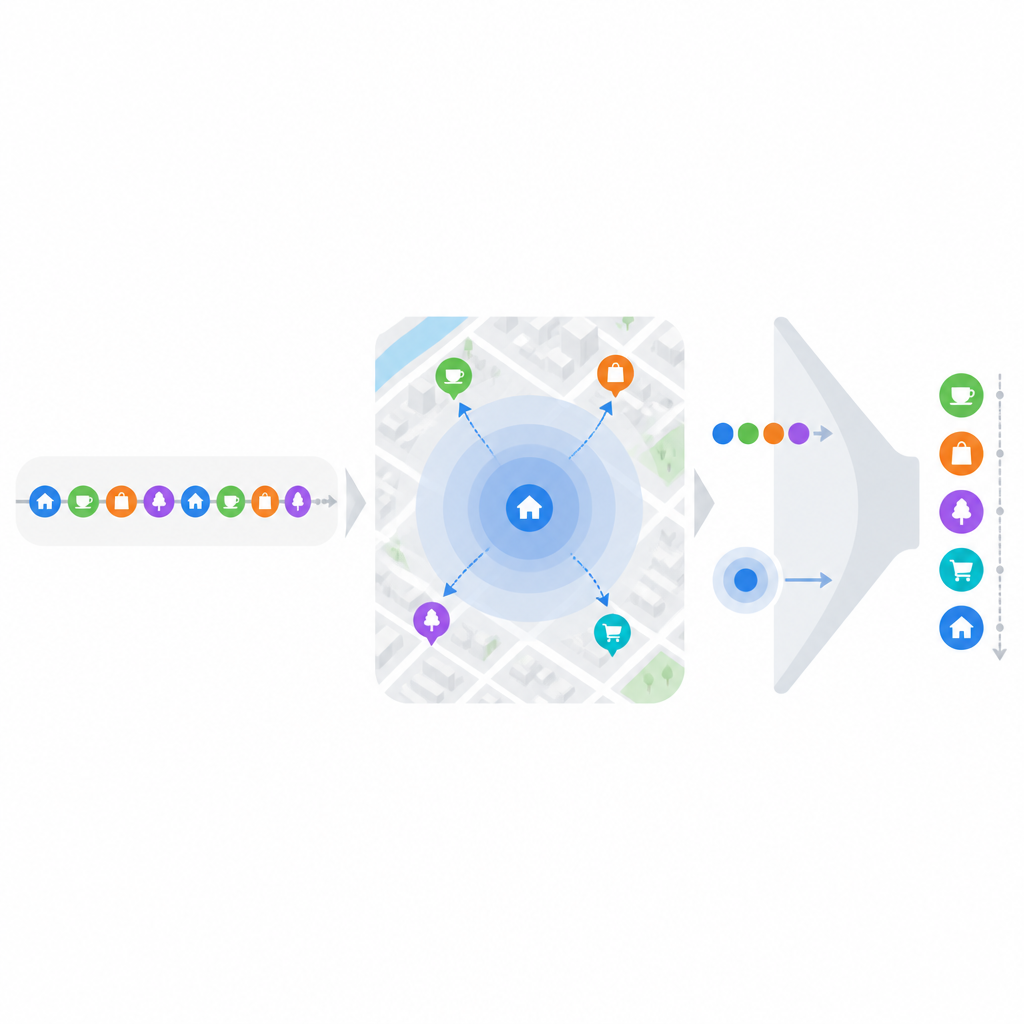
Bu daha akıllı tahminler gerçekten işe yarıyor mu
Yöntemlerini test etmek için yazarlar modeli New York ve Tokyo’dan yaklaşık bir yıllık gerçek dünyaya ait check-in verilerine uyguladı. Sosyal ağlara dayanan teknikler, derin öğrenme ve ayrıntılı sıra modellemeyi içeren uzun bir mevcut yöntem listesiyle karşılaştırdılar. Her iki şehirde de davranış ataleti esaslı modelleri, geri çağırma (recall) için yaklaşık yüzde 15’e kadar ve MAP olarak adlandırılan sıralama ölçütü için yüzde 20’ye varan iyileşmeler sağladı. Basitçe söylemek gerekirse, sistem sadece doğru sonraki mekanı daha sık bulmakla kalmıyor, aynı zamanda onu önerilen listede daha üst sıralara yerleştirme eğiliminde oluyor; kullanıcıların fark etme olasılığının daha yüksek olduğu yerde.
Gelecekteki öneriler için anlamı
Günlük kullanıcılar için çıkarım, daha iyi önerilerin neden, nerede ve ne zaman gittiğimizi anlamaktan geldiğidir, sadece nerede ve ne zaman bilgisiyle sınırlı kalmamak. İnsanların amaç, alışkanlık ve keşfetme dürtüleri tarafından şekillendirilen gevşek rutinleri takip ettiğini kabul ederek, bu model sezgisel ve zamanında hissettiren sonraki durakları önermenin bir yolunu sunuyor. Yazarlar, gelecek çalışmaların daha fazla veri geldikçe atalet ve direnç arasındaki dengeyi uyarlayabileceğini ve bunu modern derin öğrenme ile eşleştirerek konum tabanlı hizmetlere hem konfor bölgelerinin hem de merakın daha insancıl bir hissini kazandırabileceğini öne sürüyor.
Atıf: Zhang, K., Chu, D., Tu, Z. et al. A user behavior inertia based spatio temporal next POI recommendation model. Sci Rep 16, 15784 (2026). https://doi.org/10.1038/s41598-026-42191-x
Anahtar kelimeler: sıradaki POI önerisi, kullanıcı davranışı ataleti, konum tabanlı servisler, uzamsal-zamansal modelleme, hareketlilik desenleri