Clear Sky Science · pl
Model spatio-temporalny rekomendujący następne miejsca na podstawie bezwładności zachowań użytkowników
Dlaczego twoje ulubione miejsca ciągle się pojawiają
Każdy, kto korzysta z map lub aplikacji z recenzjami, widział te same kawiarnie, siłownie czy parki, które cicho zdobywają najwyższe miejsca w sugestiach. Artykuł bada, dlaczego nasze codzienne nawyki czynią te rekomendacje zaskakująco przewidywalnymi i jak lepsza matematyka może przekształcić rozproszone dane o check-inach w bardziej pomocne, mniej losowe propozycje następnych miejsc.
Nawyki stojące za tym, gdzie chodzimy
Autorzy wychodzą od prostego spostrzeżenia: ludzie rzadko wybierają swoje następne miejsce przypadkowo. Codzienne życie napędzane jest celami takimi jak jedzenie, dojazdy, relaks czy wyjścia. Z czasem powtarzalne chodzenie w podobne miejsca w tym samym celu tworzy to, co autorzy nazywają bezwładnością zachowania — swego rodzaju domyślny pociąg ku znanym miejscom. Równocześnie życie jest nieuporządkowane. Pora dnia, odległość i chęć wypróbowania czegoś nowego mogą odciągać od zwyczajowych wyborów, działając jako opór wobec tej bezwładności. Wyzwanie polega na uchwyceniu obu tendencji, aby system rekomendujący mógł bardziej niezawodnie odgadnąć następny przystanek użytkownika.
Sortowanie miejsc według codziennego celu
Jedną przeszkodą jest to, że nawet popularne aplikacje lokalizacyjne mają bardzo rzadkie dane dla pojedynczej osoby; każdy użytkownik odwiedza tylko maleńką część wszystkich dostępnych miejsc. Aby złagodzić ten problem, badacze grupują punkty zainteresowania w cztery szerokie, intuicyjne cele: jedzenie i picie, transport i zakwaterowanie, rozrywka i wyjścia oraz aktywności na świeżym powietrzu. Jedno miejsce może należeć do więcej niż jednej grupy, jeśli pełni wiele ról, jak bar będący jednocześnie restauracją. Z historii każdego użytkownika budują następnie oś czasu celów zamiast surowych współrzędnych. Proste techniki szeregów czasowych estymują, kiedy użytkownik najprawdopodobniej będzie realizować dany cel, co wyraźnie zawęża zestaw kandydatów przed przeprowadzeniem bardziej szczegółowego punktowania. 
Łączenie odległości i siły nawyku
Po przewidzeniu prawdopodobnego celu użytkownika model przechodzi do geografii i nawyku. Ludzie mają tendencję do poruszania się w kilku znanych strefach, gdzie kluczowe lokalizacje, jak dom czy biuro, działają jako centra. Wykorzystując przeszłe check-iny, system uczy się, gdzie te centra się znajdują i jak często odwiedzane są pobliskie miejsca. Miejsca bliższe częstym przystankom użytkownika otrzymują naturalny bonus, odzwierciedlający dodatkowy wysiłek wymagany na dalszy dojazd. Jednocześnie model mierzy bezwładność zachowania, analizując, jak regularnie ktoś wraca do tego samego miejsca i jak długie są zwykle przerwy między wizytami. Bierze też pod uwagę, ile różnych miejsc dana osoba wypróbowuje dla tego samego celu: osoba o silnych nawykach, która zawsze jada w tej samej restauracji, zachowuje się inaczej niż ktoś, kto ciągle eksperymentuje, nawet jeśli obie osoby często jedzą poza domem.
Równoważenie stref komfortu z ciekawością
Sercem podejścia jest traktowanie bezwładności i oporu jako sił konkurujących. Jeśli użytkownik często wraca do miejsca w regularnych odstępach czasu, model zakłada silny pociąg, by tam wrócił, szczególnie gdy zbliża się przewidywany okres następnej wizyty. W przypadku rzadko odwiedzanych miejsc system sprawdza, czy są blisko aktualnej pozycji użytkownika i czy należą do szerszej kategorii, którą użytkownik lubi eksplorować. Dzięki temu można rekomendować nie tylko oczywiste, regularne przystanki, ale też prawdopodobne nowe wybory w znanych sąsiedztwach. Końcowy wynik dla każdego kandydata łączy trzy składniki: przewidywany cel, bliskość geograficzną oraz wyuczoną siłę bezwładności zachowania wobec oporu. 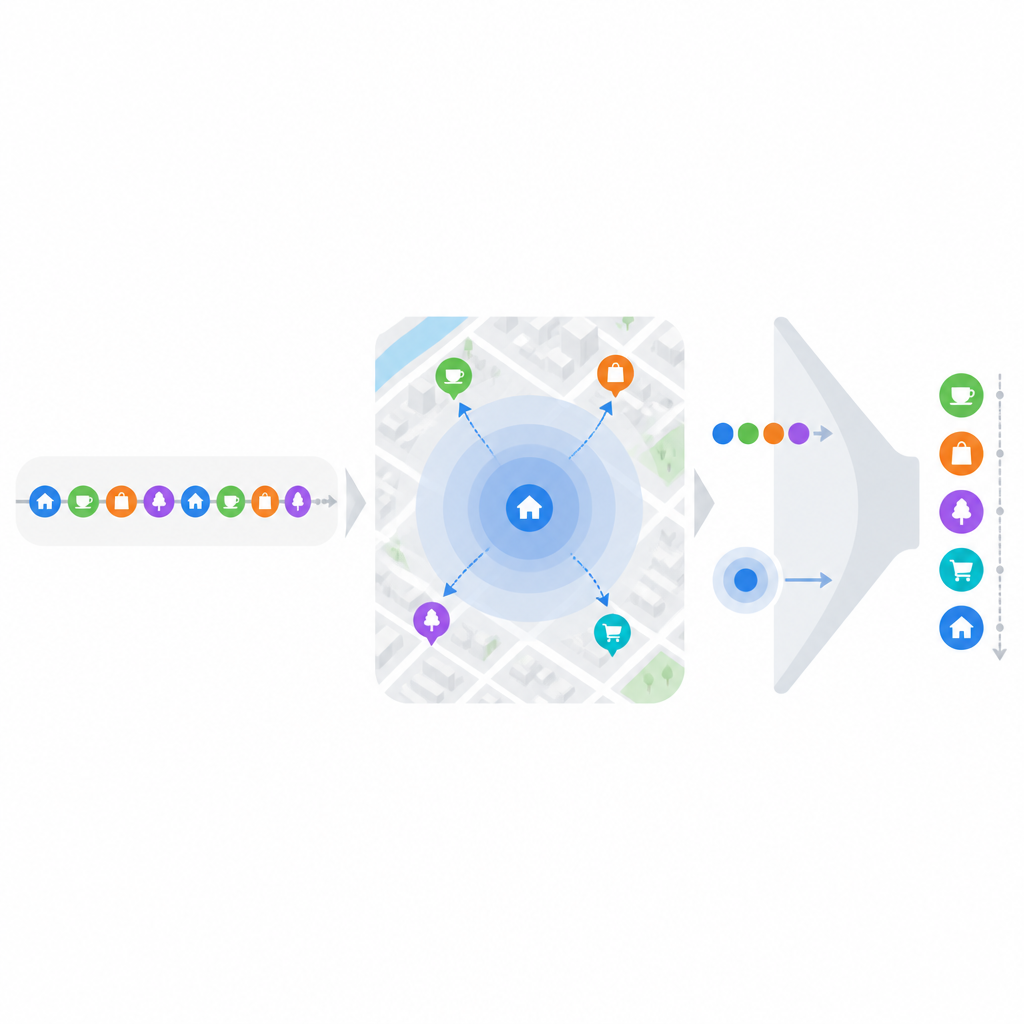
Czy te sprytniejsze zgadywanki naprawdę działają?
Aby przetestować swoją metodę, autorzy zastosowali ją do prawie rocznych danych z rzeczywistych check-inów z Nowego Jorku i Tokio. Porównali swój model z długą listą istniejących podejść, w tym technikami opartymi na sieciach społecznościowych, głębokim uczeniu i szczegółowym modelowaniu sekwencji. W obu miastach ich model oparty na bezwładności zachowania poprawił kluczowe miary dokładności nawet o około 15 procent dla recall i 20 procent dla miary rankingowej zwanej MAP. Mówiąc prościej, system nie tylko częściej znajduje prawidłowe następne miejsce, ale też zwykle umieszcza je wyżej na liście sugestii, gdzie użytkownik ma większą szansę je zauważyć.
Co to oznacza dla przyszłych rekomendacji
Dla codziennych użytkowników wniosek jest taki, że lepsze rekomendacje wynikają ze zrozumienia, dlaczego chodzimy w dane miejsca, nie tylko gdzie i kiedy. Rozpoznając, że ludzie podążają za luźnymi rutynami ukształtowanymi przez cel, nawyk i drobne bodźce do eksploracji, model oferuje sposób sugerowania następnych przystanków, które wydają się intuicyjne i na czasie. Autorzy sugerują, że przyszłe prace mogłyby adaptować równowagę między bezwładnością a oporem w miarę napływu kolejnych danych i łączyć to z nowoczesnym głębokim uczeniem, dając usługom lokalizacyjnym bardziej ludzki wymiar zarówno stref komfortu, jak i ciekawości.
Cytowanie: Zhang, K., Chu, D., Tu, Z. et al. A user behavior inertia based spatio temporal next POI recommendation model. Sci Rep 16, 15784 (2026). https://doi.org/10.1038/s41598-026-42191-x
Słowa kluczowe: rekomendacja następnego POI, bezwładność zachowań użytkownika, usługi lokalizacyjne, modelowanie przestrzenno‑czasowe, wzorce mobilności