Clear Sky Science · nl
Een op gebruikersgedragsinertie gebaseerd spatio-temporaal model voor aanbeveling van het volgende POI
Waarom je favoriete plekken steeds terugkomen
Iemand die kaart- of beoordelingsapps gebruikt, ziet steevast dezelfde cafés, sportscholen of parken naar de top van de suggesties stijgen. Dit artikel onderzoekt waarom onze dagelijkse gewoonten die aanbevelingen verrassend voorspelbaar maken en hoe slimmere wiskunde verspreide check-in data kan omzetten in behulpzamere, minder willekeurige voorstellen voor de volgende locatie.
De gewoonten achter waar we naartoe gaan
De auteurs beginnen bij een simpele observatie: mensen kiezen zelden willekeurig hun volgende bestemming. Het dagelijks leven wordt gestuurd door doelen zoals eten, woon-werkverkeer, ontspanning of uitgaan. Door herhaaldelijk naar vergelijkbare plekken te gaan voor hetzelfde doel ontstaat wat de auteurs gedragsinertie noemen, een soort standaard aantrekkingskracht naar vertrouwde plekken. Tegelijk is het echte leven rommelig. Tijdstip, afstand en de drang iets nieuws te proberen kunnen mensen van hun gebruikelijke keuzes afduwen en werken als weerstand tegen die inertie. De uitdaging is beide neigingen vast te leggen zodat een aanbevelingssysteem betrouwbaarder kan raden wat iemands volgende stop wordt.
Plekken sorteren op dagelijks doel
Een obstakel is dat zelfs populaire locatiegebaseerde apps voor een individu zeer schaarse data hebben; elke gebruiker bezoekt maar een klein deel van alle beschikbare locaties. Om dit probleem te verzachten groeperen de onderzoekers punten van interesse in vier brede, intuïtieve doelen: eten en drinken, vervoer en accommodatie, uitgaan en entertainment, en buitenactiviteiten. Een locatie kan in meer dan één groep vallen als hij meerdere functies vervult, zoals een bar die ook een restaurant is. Uit de geschiedenis van elke gebruiker bouwen ze vervolgens een tijdlijn van doelen in plaats van ruwe coördinaten. Eenvoudige tijdreeks-technieken schatten wanneer een gebruiker het meest waarschijnlijk elk doel als volgende nastreeft, wat de set van kandidaatlocaties sterk verkleint voordat er fijnmazige scores worden berekend. 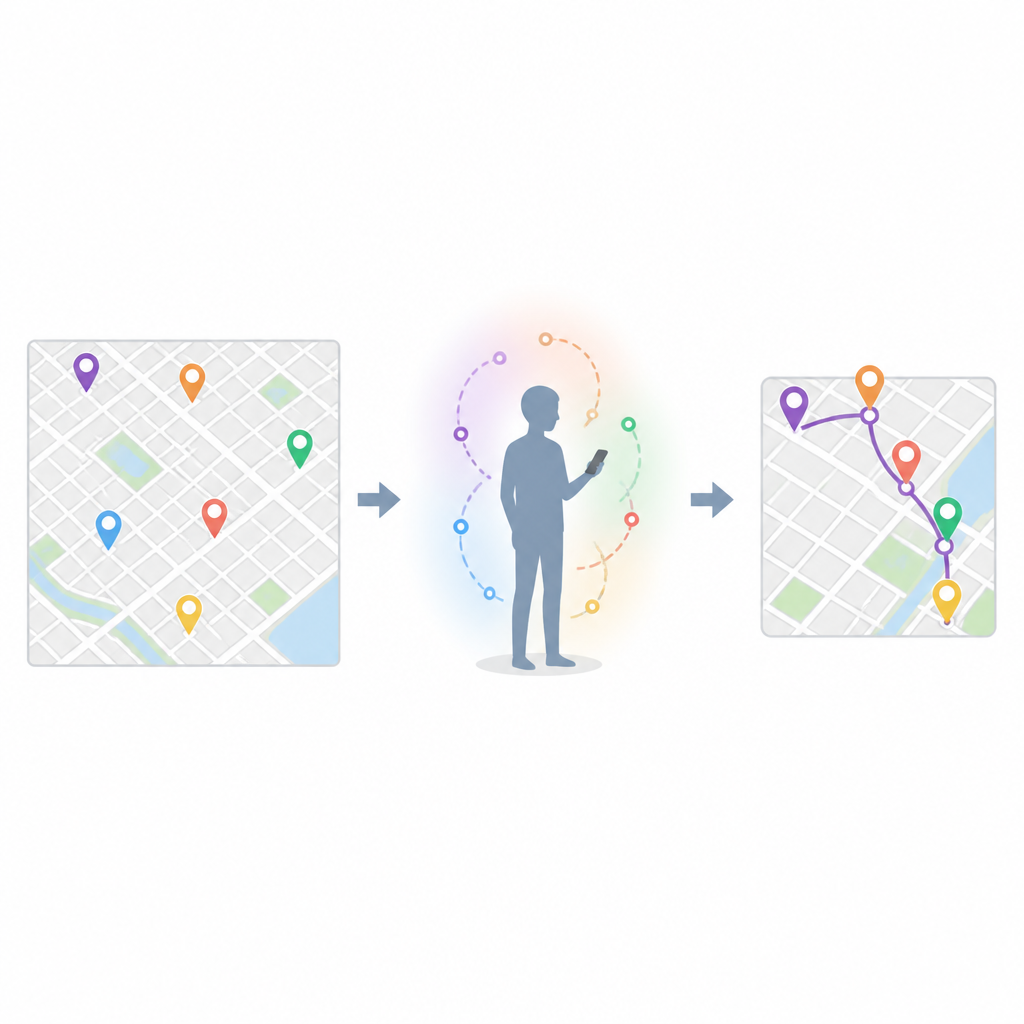
Afstand en gewoonte-sterkte combineren
Nadat het waarschijnlijke doel van de gebruiker is geraden, richt het model zich op geografie en gewoonte. Mensen bewegen zich vaak binnen een paar vertrouwde zones waar kernlocaties, zoals huis of kantoor, als centra fungeren. Met behulp van eerdere check-ins leert het systeem waar deze centra liggen en hoe vaak elke nabijgelegen plek is bezocht. Plekken dichter bij iemands frequente stops krijgen een natuurlijke boost, wat de extra inspanning weerspiegelt die nodig is om verder te reizen. Tegelijk meet het model gedragsinertie door te kijken hoe regelmatig iemand naar dezelfde locatie terugkeert en hoe lang de intervallen tussen bezoeken gewoonlijk zijn. Het houdt ook rekening met hoeveel verschillende locaties iemand uitprobeert voor hetzelfde doel: een gewoontedier dat altijd in hetzelfde restaurant eet, gedraagt zich anders dan iemand die voortdurend experimenteert, zelfs als beiden vaak uit eten gaan.
Comfortzones in balans met nieuwsgierigheid
De kern van de aanpak is inertie en weerstand te behandelen als concurrerende krachten. Als een gebruiker vaak naar een plek terugkeert met consistente tijdsintervallen, neemt het model een sterke aantrekkingskracht aan om daar terug te gaan, vooral wanneer het volgende voorspelde bezoekvenster nadert. Voor zelden bezochte plekken controleert het systeem of ze dicht bij de huidige positie van de gebruiker liggen en of ze binnen een bredere categorie vallen die de gebruiker graag verkent. Dit maakt het mogelijk niet alleen de voor de hand liggende vaste favorieten aan te bevelen, maar ook plausibele nieuwe keuzes in vertrouwde buurten. De eindscore voor elke kandidaatlocatie mengt drie ingrediënten: het voorspelde doel, geografische nabijheid en de aangeleerde sterkte van gedragsinertie versus weerstand. 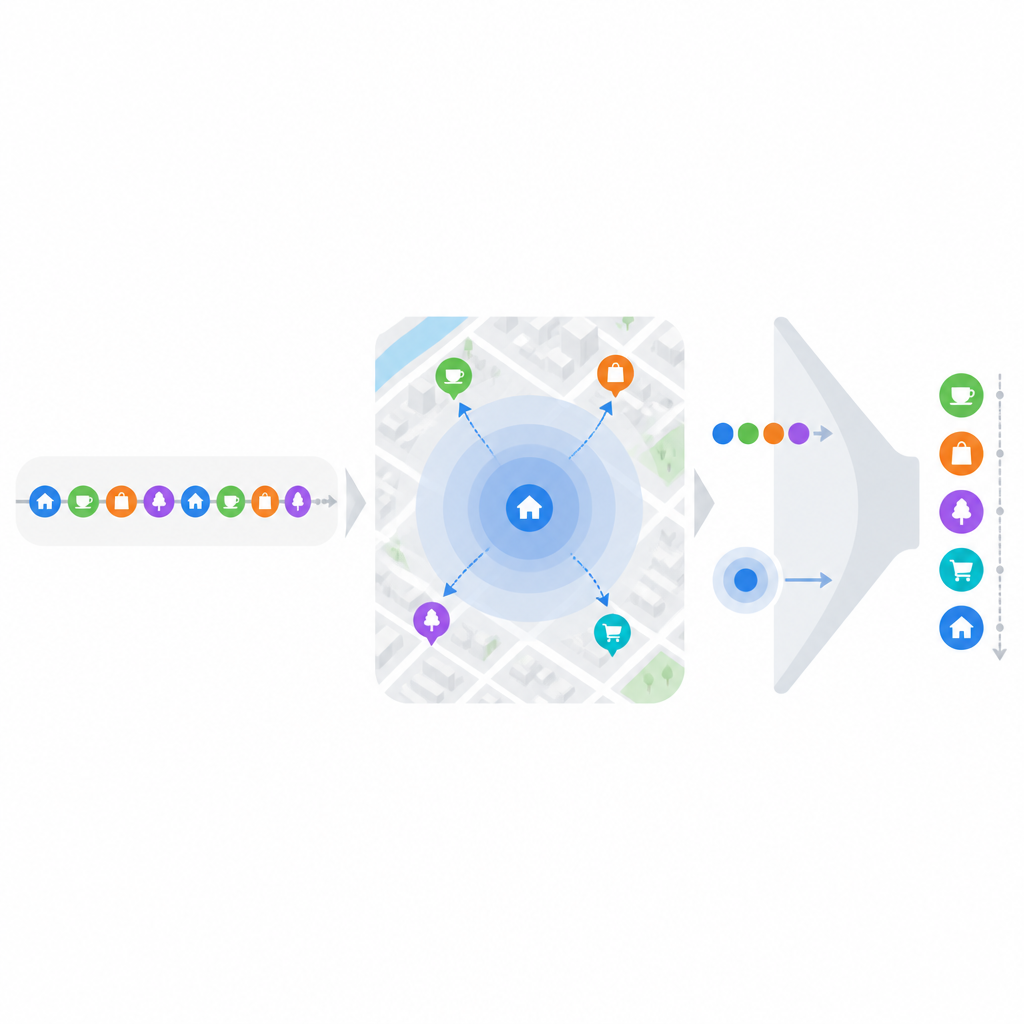
Werken deze slimme gissingen echt
Om hun methode te testen pasten de auteurs die toe op bijna een jaar aan echte check-ins uit New York City en Tokio. Ze vergeleken hun model met een lange lijst van bestaande benaderingen, inclusief technieken die leunen op sociale netwerken, deep learning en gedetailleerde sequentiemodellering. In beide steden verbeterde hun op gedragsinertie gebaseerde model belangrijke nauwkeurigheidsmaten met maximaal ongeveer 15 procent voor recall en 20 procent voor een rangschikkingsmaat genaamd MAP. In gewone bewoordingen vindt het systeem niet alleen vaker de correcte volgende plek, maar zet het die ook vaker hoger in de voorgestelde lijst, waar een gebruiker hem eerder opmerkt.
Wat dit betekent voor toekomstige aanbevelingen
Voor alledaagse gebruikers is de conclusie dat betere aanbevelingen voortkomen uit begrip van waarom we ergens naartoe gaan, niet alleen waar en wanneer. Door te erkennen dat mensen losse routines volgen die worden gevormd door doel, gewoonte en kleine duwtjes om te verkennen, biedt dit model een manier om volgende stops voor te stellen die logisch en tijdig aanvoelen. De auteurs suggereren dat toekomstig werk de balans tussen inertie en weerstand kan aanpassen naarmate er meer data binnenkomt, en dit kan combineren met moderne deep learning, waardoor locatiegebaseerde diensten een meer menselijk gevoel krijgen voor zowel comfortzones als nieuwsgierigheid.
Bronvermelding: Zhang, K., Chu, D., Tu, Z. et al. A user behavior inertia based spatio temporal next POI recommendation model. Sci Rep 16, 15784 (2026). https://doi.org/10.1038/s41598-026-42191-x
Trefwoorden: aanbeveling volgende POI, gebruikersgedragsinertie, locatiegebaseerde diensten, spatio-temporaal modelleren, mobiliteitspatronen