Clear Sky Science · sv
En modell för spatio-temporal nästa POI-rekommendation baserad på användarbeteendeinerti
Varför dina favoritställen fortsätter att dyka upp
Alla som använder kart‑ eller recensionsappar har sett samma kaféer, gym eller parker sakta klättra upp i förslagen. Denna artikel undersöker varför våra vardagsvanor gör de där rekommendationerna förvånansvärt förutsägbara och hur smartare matematik kan förvandla spridda incheckningsdata till mer hjälpsamma, mindre slumpmässiga förslag på nästa plats.
Vanor som styr vart vi går
Författarna utgår från en enkel iakttagelse: människor väljer sällan sitt nästa stopp helt slumpmässigt. Vardagen drivs av syften som att äta, pendla, koppla av eller gå ut. Med tiden skapar återkommande besök på liknande platser för samma syfte vad författarna kallar beteendeinerti, ett slags standarddragningskraft mot bekanta ställen. Samtidigt är verkligheten rörig. Tid på dygnet, avstånd och lusten att prova något nytt kan driva människor bort från sina vanliga val och agera som motstånd mot denna inerti. Utmaningen är att fånga båda dessa tendenser så att ett rekommendationssystem kan gissa en användares nästa stopp mer tillförlitligt.
Sortera platser efter vardagssyfte
Ett hinder är att även populära platsbaserade appar har mycket gles data för en enskild person; varje användare besöker bara en liten del av alla tillgängliga platser. För att mildra problemet grupperar forskarna intressepunkterna i fyra breda, intuitiva syften: äta och dricka, transport och boende, nöjen och uteställen samt utomhusaktiviteter. En plats kan tillhöra mer än en grupp om den tjänar flera roller, som en bar som också är en restaurang. Från varje användares historik bygger de sedan en tidslinje av syften i stället för råa koordinater. Enkla tidsserietekniker uppskattar när en användare sannolikt kommer att eftersträva varje syfte härnäst, vilket skarpt begränsar mängden kandidatplatser innan någon finare scorning görs. 
Kombinera avstånd och vanestyrka
När användarens sannolika syfte har gissats vänder modellen sig mot geografi och vana. Människor tenderar att röra sig inom några bekanta zoner där nyckelplatser, som hem eller kontor, fungerar som centra. Med hjälp av tidigare incheckningar lär sig systemet var dessa centra ligger och hur ofta varje närliggande ställe har besökts. Platser nära användarens frekventa stopp får en naturlig förstärkning, vilket speglar den extra ansträngning som krävs för att resa längre. Samtidigt mäter modellen beteendeinerti genom att se hur regelbundet någon återvänder till samma plats och hur långa mellanrum mellan besöken vanligtvis är. Den tar också hänsyn till hur många olika platser en person provar för samma syfte: en vanemänniska som alltid äter på samma restaurang beter sig annorlunda än någon som ständigt experimenterar, även om båda ofta äter ute.
Balansera trygghetszoner med nyfikenhet
Kärnan i tillvägagångssättet är att behandla inerti och motstånd som konkurrerande krafter. Om en användare ofta återvänder till en plats med konsekventa tidsmellanrum antar modellen en stark dragning att gå tillbaka dit, särskilt när nästa förutsagda besöksfönster närmar sig. För sällan besökta ställen kontrollerar systemet om de ligger nära användarens nuvarande position och om de passar inom en bredare kategori som användaren gillar att utforska. Detta gör det möjligt att rekommendera inte bara de uppenbara vanliga ställena utan också plausibla nya val i bekanta kvarter. Det slutliga poängsättningen för varje kandidatplats blandar tre ingredienser: förutsagt syfte, geografisk närhet och den inlärda styrkan hos beteendeinerti kontra motstånd. 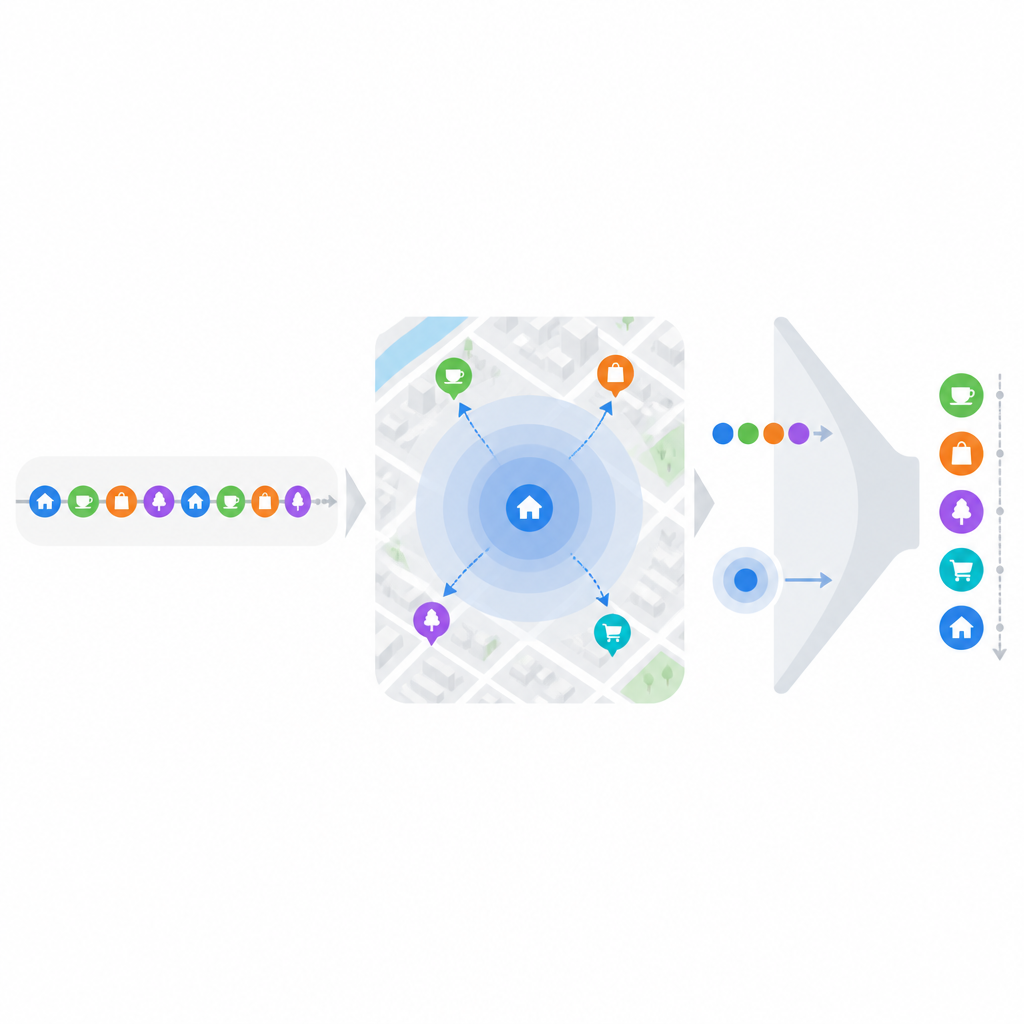
Fungerar dessa smartare gissningar i praktiken?
För att testa sin metod tillämpade författarna den på nästan ett års verkliga incheckningar från New York City och Tokyo. De jämförde sin modell med en lång lista befintliga tillvägagångssätt, inklusive tekniker som bygger på sociala nätverk, djupinlärning och detaljerad sekvensmodellering. I båda städerna förbättrade deras modell baserad på beteendeinerti nyckelmått för noggrannhet med upp till cirka 15 procent för recall och 20 procent för ett rankningsmått kallat MAP. Enkelt uttryckt hittar systemet inte bara rätt nästa plats oftare utan tenderar också att placera den högre i den föreslagna listan, där en användare är mer benägen att lägga märke till den.
Vad detta innebär för framtida rekommendationer
För vardagsanvändare är slutsatsen att bättre rekommendationer kommer av att förstå varför vi går till platser, inte bara var och när. Genom att känna igen att människor följer lösa rutiner formade av syfte, vana och små knuffar att utforska erbjuder denna modell ett sätt att föreslå nästa stopp som känns intuitivt och tidsmässigt passande. Författarna föreslår att framtida arbete kan anpassa balansen mellan inerti och motstånd i takt med att mer data kommer in och kombinera detta med modern djupinlärning, vilket ger platsbaserade tjänster en mer mänsklig känsla för både trygghetszoner och nyfikenhet.
Citering: Zhang, K., Chu, D., Tu, Z. et al. A user behavior inertia based spatio temporal next POI recommendation model. Sci Rep 16, 15784 (2026). https://doi.org/10.1038/s41598-026-42191-x
Nyckelord: rekommendation av nästa POI, användarbeteendeinerti, platsbaserade tjänster, spatio-temporal modellering, rörelsemönster