Clear Sky Science · ru
Модель пространственно-временных рекомендаций следующей точки интереса, основанная на инертности поведения пользователя
Почему ваши любимые места постоянно появляются в списке
Каждый, кто пользуется картами или приложениями с отзывами, видел, как одни и те же кафе, тренажёрные залы или парки тихо поднимаются вверх в списке предложений. В этой статье исследуется, почему наши повседневные привычки делают такие рекомендации удивительно предсказуемыми и как более продуманная математика может превратить разрозненные данные о чекинах в более полезные, менее случайные предложения следующего места.
Привычки, определяющие, куда мы ходим
Авторы исходят из простого наблюдения: люди редко выбирают следующую остановку случайно. Повседневная жизнь определяется целями — поесть, поехать, отдохнуть или развлечься. Со временем повторяющиеся походы в похожие места для одной и той же цели создают то, что авторы называют инертностью поведения, своего рода «по́тянутость» к знакомым локациям. В то же время реальная жизнь непредсказуема. Время суток, расстояние и желание попробовать что‑то новое могут оттолкнуть человека от привычного выбора, выступая как сопротивление этой инертности. Задача состоит в том, чтобы учесть оба этих вектора, чтобы система рекомендаций могла более надёжно угадывать следующую остановку пользователя.
Сортировка мест по повседневным целям
Одна из проблем — даже у популярных приложений, работающих с местоположением, данные для каждого отдельного человека очень разрежены: каждый пользователь посещает лишь крошечную часть всех доступных мест. Чтобы упростить эту задачу, исследователи группируют точки интереса в четыре широкие, интуитивно понятные категории по целям: еда и напитки, транспорт и проживание, развлечения и выходы в свет, а также активности на открытом воздухе. Одна и та же локация может принадлежать сразу нескольким группам, если она выполняет разные роли — например бар, который также является рестораном. Из истории каждого пользователя они затем строят хронологию целей вместо сырых координат. Простые методы анализа временных рядов оценивают, когда с наибольшей вероятностью пользователь будет стремиться к каждой цели в следующий раз, что резко сужает набор кандидатных мест до детальной оценки. 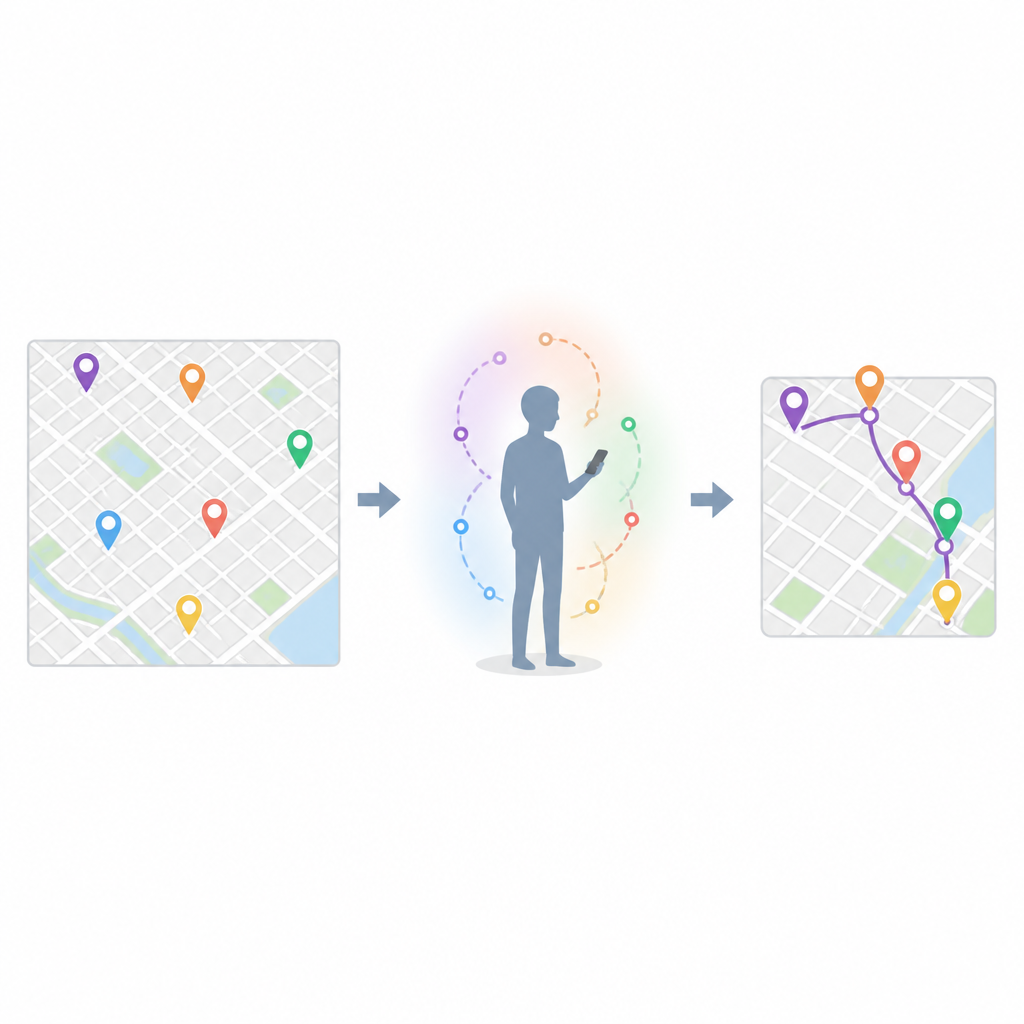
Комбинация расстояния и силы привычки
После определения вероятной цели пользователя модель обращается к географии и привычке. Люди, как правило, перемещаются в пределах нескольких знакомых зон, где ключевые локации, такие как дом или офис, выступают центрами. На основе прошлых чекинов система учится, где находятся эти центры и как часто посещается каждое близлежащее место. Места ближе к частым остановкам пользователя получают естественное преимущество, отражая дополнительные затраты на поездку на более дальние расстояния. Одновременно модель измеряет инертность поведения, анализируя, как регулярно человек возвращается в одно место и каковы обычно промежутки между визитами. Она также учитывает, сколько разных мест человек пробует для одной и той же цели: человек привычный, который всегда ужинает в одном ресторане, ведёт себя иначе, чем тот, кто постоянно экспериментирует, даже если оба часто питаются вне дома.
Баланс между комфортной зоной и любопытством
Суть подхода — рассматривать инертность и сопротивление как конкурирующие силы. Если пользователь часто возвращается в место с одинаковыми временными интервалами, модель предполагает сильное притяжение вернуться туда, особенно когда приближается предсказанное окно следующего визита. Для редко посещаемых мест система проверяет, находятся ли они близко к текущему положению пользователя и попадают ли в более широкую категорию, которую пользователь любит исследовать. Это позволяет рекомендовать не только очевидные постоянные точки, но и правдоподобные новые варианты в знакомых районах. Итоговый счёт для каждой кандидатной локации сочетает три компонента: предсказанную цель, географическую близость и оценённую силу инертности поведения относительно сопротивления. 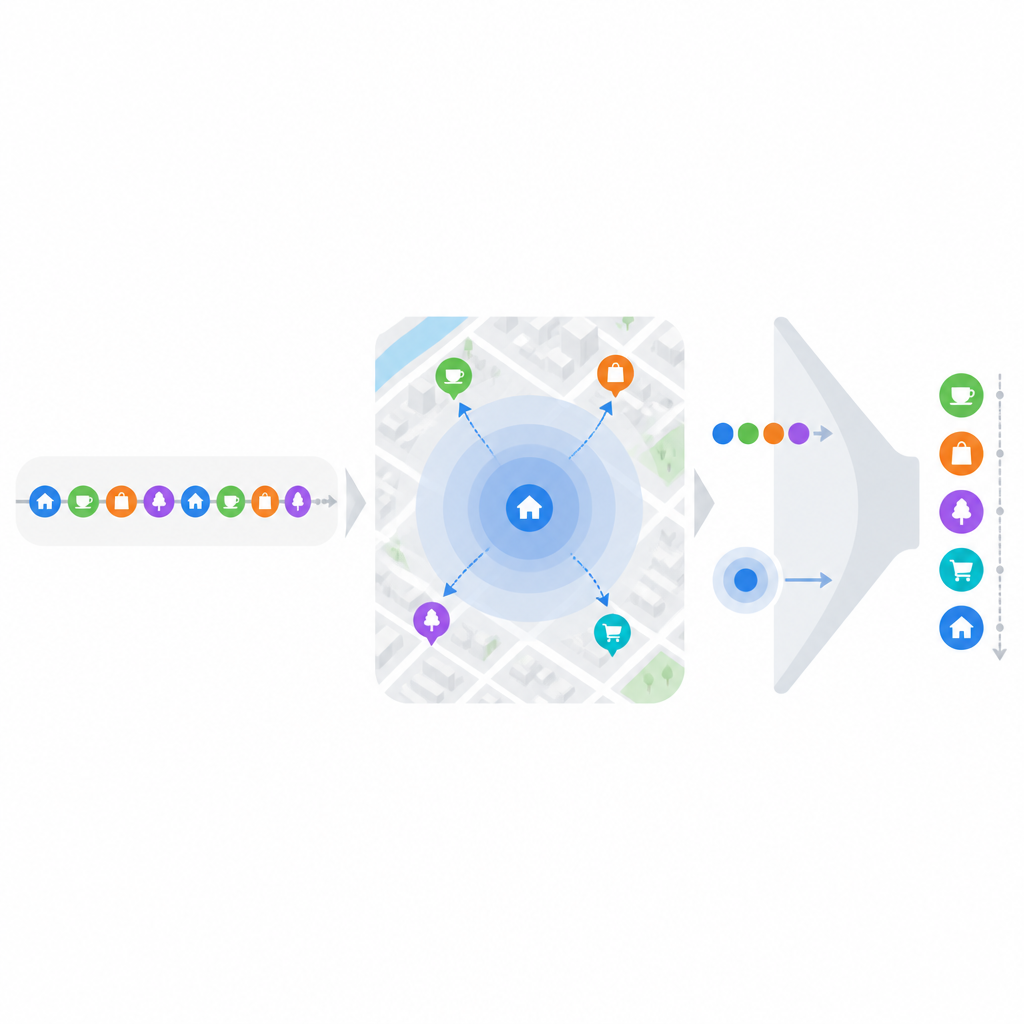
Действительно ли эти более умные предположения работают
Чтобы проверить метод, авторы применили его к почти году реальных чекинов из Нью‑Йорка и Токио. Они сравнили свою модель с длинным списком существующих подходов, включая методы, опирающиеся на социальные сети, глубокое обучение и детальное моделирование последовательностей. В обоих городах модель, основанная на инертности поведения, улучшила ключевые показатели точности примерно до 15 процентов по recall и до 20 процентов по показателю ранжирования MAP. Проще говоря, система не только чаще находит правильную следующую точку, но и чаще располагает её выше в списке предложений, где пользователь с большей вероятностью её заметит.
Что это значит для будущих рекомендаций
Для повседневных пользователей вывод таков: лучшие рекомендации появляются из понимания того, почему мы ходим в те или иные места, а не только где и когда. Признавая, что люди следуют рыхлым рутинам, сформированным целью, привычкой и небольшими подтолкиваниями к исследованию, эта модель предлагает способ рекомендовать следующие остановки, которые кажутся интуитивными и своевременными. Авторы предполагают, что будущие работы могут адаптировать баланс между инертностью и сопротивлением по мере поступления новых данных и сочетать это с методами глубокого обучения, придавая сервисам, основанным на местоположении, более человеческое чувство как зон комфорта, так и любопытства.
Цитирование: Zhang, K., Chu, D., Tu, Z. et al. A user behavior inertia based spatio temporal next POI recommendation model. Sci Rep 16, 15784 (2026). https://doi.org/10.1038/s41598-026-42191-x
Ключевые слова: рекомендация следующей точки интереса, инертность поведения пользователя, сервисы, привязанные к местоположению, пространственно-временное моделирование, мобилизационные паттерны