Clear Sky Science · sv
En jämförande utvärdering av gradientbaserade optimeringsalgoritmer för korttidslastprognoser med djupa residualnätverk
Varför morgondagens elförbrukning är viktig redan idag
Varje gång vi tänder en lampa eller kopplar in en apparat måste elbolagen redan ha ström tillgänglig för att möta efterfrågan. Att förutsäga morgondagens behov några timmar eller en dag i förväg hjälper nätoperatörer att hålla igång systemet, undvika strömavbrott och spara pengar. Denna artikel undersöker hur moderna artificiella intelligensverktyg kan göra korttidsprognoser mer exakta och stabila, och visar att det ofta förbisett valet av träningsmetod kan vara lika viktigt som själva modellen.
Att hänga med i ett nät i förändring
Elförbrukningen varierar med dygnstid, årstid, helgdagar och väder. Traditionella statistiska metoder har svårt att fånga dessa komplexa mönster, särskilt när många olika signaler ingår. Djupa inlärningsmodeller, som staplar många lager av enkla beräkningar, har blivit populära eftersom de kan lära sig subtila, icke-linjära samband. Ett utförande, kallat djupa residualnätverk, lägger till "genvägs"-kopplingar mellan lager, vilket gör mycket djupa modeller enklare att träna och bättre på att fånga långsiktiga beroenden i data som elbelastningar.

Två vädermedvetna arkitekturer
Författarna fokuserar på två nära besläktade djupa residualmodeller för korttidslastprognoser. Den första använder tidigare elförbrukning, tidsinformation (som timme och veckodag) samt temperatur för att förutsäga de kommande 24 timmarna. Den andra modellen lägger till många fler vädervariabler från en tropisk stad, inklusive nederbörd och vind, men komprimerar dem till ett litet antal sammansatta signaler med ett standardstatistiskt verktyg som bevarar det mesta av variationen samtidigt som redundans minskas. Detta låter den rikare väderbilden informera nätverket utan att göra det otympligt eller svårare att träna.
Hur träningsval formar inlärningen
De flesta studier som använder dessa djupa residualnätverk för kraftprognoser väljer tyst en populär träningsmetod kallad Adam och nöjer sig med det. Träningsmetod här avser den matematiska receptet som justerar modellens interna inställningar gradvis när den lär sig från historiska data. Denna artikel ifrågasätter den vanan genom att systematiskt jämföra tretton olika gradientbaserade träningsalgoritmer, inklusive klassiska tillvägagångssätt och flera moderna adaptiva varianter, alla inom samma modellstruktur. Författarna testar dem på två verkliga datamängder: en från det tempererade New England-systemet i USA och en annan från tropiska Malaysia.
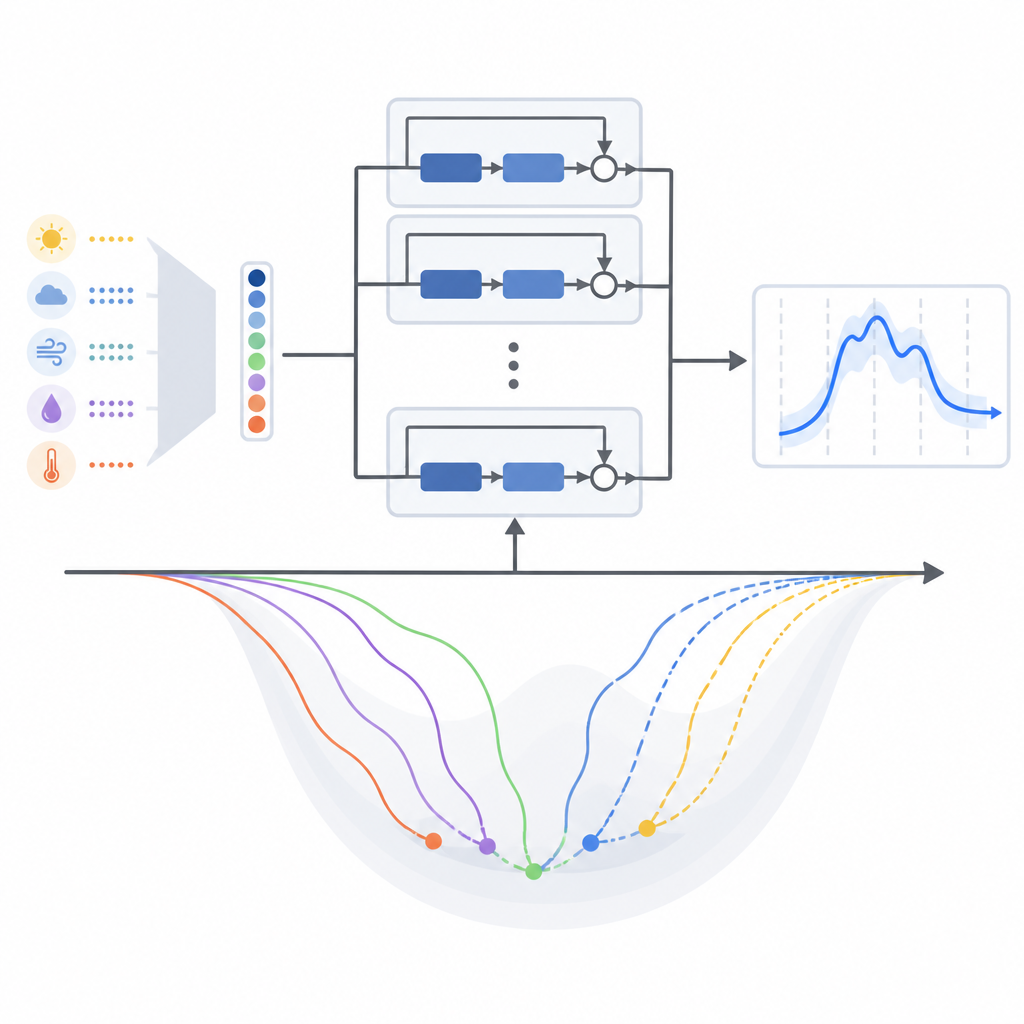
Vad som fungerade bäst i olika klimat
I båda regionerna presterade metoder som anpassar sina inlärningssteg utifrån senaste felmönster generellt bättre än äldre, enklare tillvägagångssätt. För den ursprungliga modellen som huvudsakligen förlitar sig på temperatur som vädersignal gav en variant kallad AMSGrad de lägsta genomsnittliga prognosfelen och mest stabila träningsbeteendet i båda klimat. När författarna skiftade till den komprimerade multiväderversionen av modellen ändrades dock balansen. Under denna nya indatarepresentation drog en annan adaptiv metod, AdaBelief, ifrån något, och Adam presterade också starkt. Med andra ord omformade förändringen i hur väderinformationen paketeras inlärningslandskapet och gynnade olika träningsregler.
Kontrollera att vinsterna är verkliga, inte tur
För att försäkra sig om att de observerade förbättringarna inte bara var statistiskt brus använde författarna en resamplingsteknik som upprepade gånger spelar upp prognosuppgiften på något varierade dataprover. Detta gjorde det möjligt att uppskatta hur sannolikt det är att en träningsmetod verkligen överträffar en annan. Tester visade att flera av de observerade vinsterna, såsom att AMSGrad slog Adam på New England-data och fördelarna med den komprimerade vädermetoden under vissa optimerare i Malaysia, sannolikt inte berodde på slumpen enbart.
Vad detta innebär för framtidens nät
För icke-specialister är huvudbudskapet att bättre prognoser för elbehov inte bara handlar om att uppfinna nya neurala nätverk eller stoppa in mer väderdata i dem. Hur dessa nät tränas och hur väderindata destilleras kan avsevärt förändra noggrannhet och stabilitet. Genom att visa att vissa adaptiva träningsregler konsekvent förbättrar prestanda, och att bästa valet kan bero på hur indata representeras, ger denna studie nätplanerare och AI-utövare ett klarare recept för att bygga mer pålitliga prognosverktyg som hjälper till att hålla elsystem säkra och kostnadseffektiva.
Citering: Liu, J., Ahmad, F.A., Samsudin, K. et al. A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks. Sci Rep 16, 14949 (2026). https://doi.org/10.1038/s41598-026-45829-y
Nyckelord: korttidslastprognoser, djupa residualnätverk, optimeringsalgoritmer, prognoser för kraftsystem, meteorologiska variabler