Clear Sky Science · en
A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks
Why tomorrow’s power use matters today
Every time we flip on a light or plug in a device, power companies must already have electricity flowing to meet that demand. Guessing tomorrow’s demand a few hours or a day ahead helps grid operators keep the lights on, avoid blackouts, and save money. This paper explores how modern artificial intelligence tools can make those short-term demand forecasts more accurate and more stable, and shows that the often-overlooked choice of training method can matter as much as the model itself.
Keeping up with a changing grid
Electricity demand rises and falls with time of day, season, holidays, and weather. Traditional statistical methods struggle with these complex patterns, especially when many different signals are involved. Deep learning models, which stack many layers of simple calculations, have become popular because they can learn subtle, nonlinear relationships. Among them, a design called a deep residual network adds “shortcut” connections between layers, making very deep models easier to train and better at capturing long-term dependencies in data such as electricity loads.

Two kinds of weather-aware brain
The authors focus on two closely related deep residual models for short-term load forecasting. The first uses past electricity use, time information (such as hour and day of week), and temperature to predict the next 24 hours of demand. The second model adds many more weather variables from a tropical city, including rainfall and wind, but compresses them into a small set of combined signals using a standard statistical tool that keeps most of the variation while reducing redundancy. This lets the richer weather picture inform the network without making it unwieldy or harder to train.
How training choices shape learning
Most studies that use these deep residual networks for power forecasting quietly pick a popular training method called Adam and leave it at that. Training method here means the mathematical recipe that nudges the model’s internal settings a bit at a time as it learns from past data. This paper challenges that habit by systematically comparing thirteen different gradient-based training algorithms, including classic approaches and several modern adaptive variants, all within the same model structure. The authors test them on two real-world datasets: one from the temperate New England power system in the United States and another from tropical Malaysia.
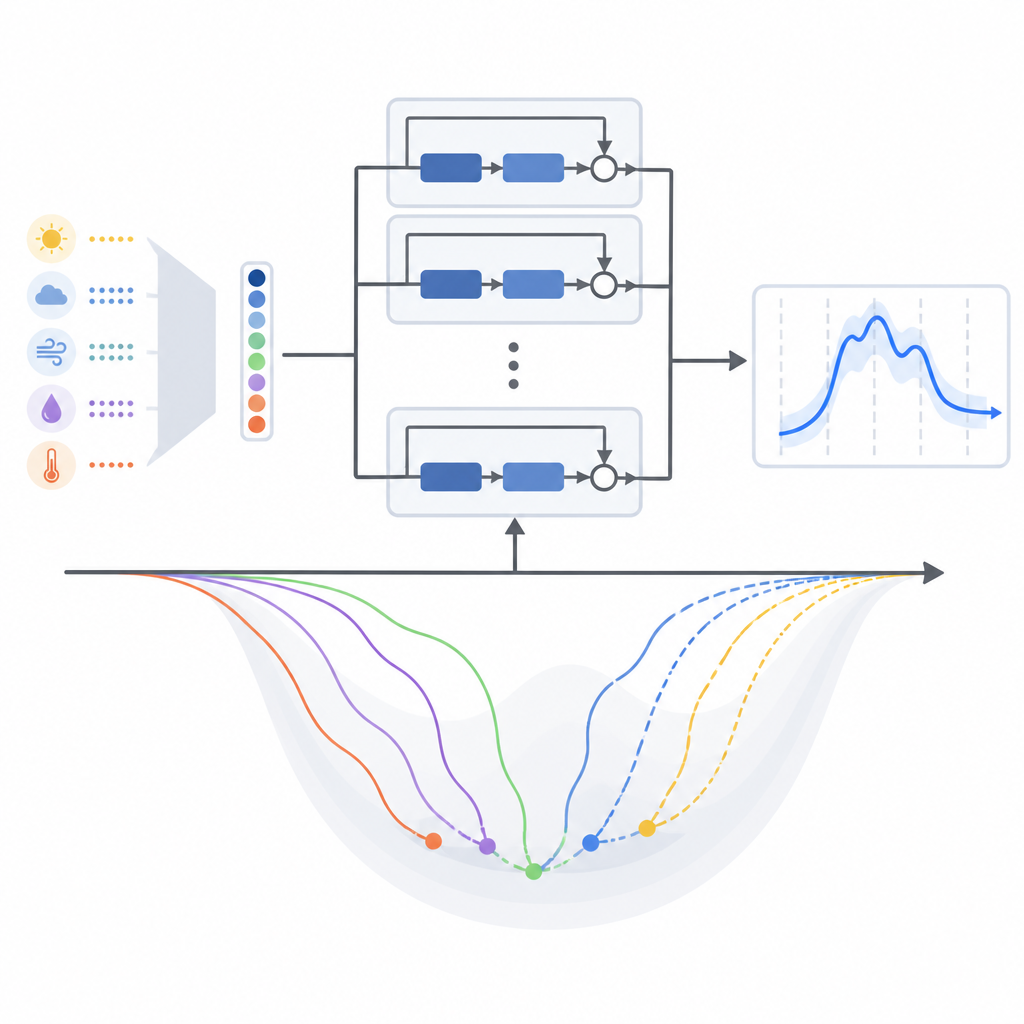
What worked best in different climates
Across both regions, methods that adapt their learning steps using recent error patterns generally beat older, simpler approaches. For the original model that mainly relies on temperature as its weather signal, a variant called AMSGrad gave the lowest average forecasting errors and the most stable training behavior in both climates. When the authors switched to the compressed multi-weather version of the model, however, the balance shifted. Under this new input design, another adaptive method, AdaBelief, edged ahead, and Adam also performed strongly. In other words, changing how weather information is packaged for the model subtly reshaped the learning landscape and favored different training rules.
Checking that gains are real, not luck
To be sure the observed improvements were not just statistical noise, the authors used a resampling technique that repeatedly replays the forecasting task on slightly varied data samples. This allowed them to estimate how likely it is that one training method truly outperforms another. The tests showed that several of the observed gains, such as AMSGrad beating Adam on the New England data and the benefits of the compressed-weather approach under certain optimizers in Malaysia, are unlikely to be due to chance alone.
What this means for the future grid
For non-specialists, the main message is that getting better power demand forecasts is not only about inventing new neural networks or stuffing more weather into them. The way those networks are trained and the way weather inputs are distilled can significantly change accuracy and stability. By demonstrating that some adaptive training rules consistently improve performance, and that the best choice can depend on how the input data are represented, this study gives grid planners and AI practitioners a clearer recipe for building more reliable forecasting tools that help keep electricity systems both secure and economical.
Citation: Liu, J., Ahmad, F.A., Samsudin, K. et al. A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks. Sci Rep 16, 14949 (2026). https://doi.org/10.1038/s41598-026-45829-y
Keywords: short term load forecasting, deep residual networks, optimization algorithms, power system forecasting, meteorological features