Clear Sky Science · nl
Een vergelijkende evaluatie van gradient-gebaseerde optimalisatie-algoritmen voor kortetermijn-energievraagvoorspelling met diepe residuenetwerken
Waarom het elektriciteitsverbruik van morgen vandaag al telt
Elke keer dat we een licht aandoen of een apparaat aansluiten, moeten energiebedrijven al elektriciteit beschikbaar hebben om aan die vraag te voldoen. Het voorspellen van de vraag voor morgen, enkele uren tot één dag vooruit, helpt netbeheerders om de lichten aan te houden, black-outs te voorkomen en kosten te besparen. Dit artikel onderzoekt hoe moderne kunstmatige-intelligentietools die kortetermijnvoorspellingen van de vraag nauwkeuriger en stabieler kunnen maken, en laat zien dat de vaak over het hoofd geziene keuze van trainingsmethode even belangrijk kan zijn als het model zelf.
Bijblijven met een veranderend net
De vraag naar elektriciteit stijgt en daalt met het tijdstip van de dag, het seizoen, feestdagen en het weer. Traditionele statistische methoden hebben moeite met deze complexe patronen, vooral wanneer veel verschillende signalen meespelen. Diepe leermodellen, die vele lagen van eenvoudige berekeningen stapelen, zijn populair geworden omdat ze subtiele, niet-lineaire relaties kunnen leren. Een ontwerp dat diepe residuenetwerk wordt genoemd voegt ‘snelkoppelingen’ tussen lagen toe, waardoor zeer diepe modellen makkelijker te trainen zijn en beter in staat zijn langetermijnafhankelijkheden in gegevens zoals elektriciteitsvraag vast te leggen.

Twee soorten weerbewuste netwerken
De auteurs richten zich op twee nauwe verwante diepe residuenmodellen voor kortetermijn-energievraagvoorspelling. Het eerste gebruikt eerder elektriciteitsverbruik, tijdinformatie (zoals uur en dag van de week) en temperatuur om de volgende 24 uur vraag te voorspellen. Het tweede model voegt veel meer weerkundige variabelen toe uit een tropische stad, waaronder neerslag en wind, maar comprimeert deze tot een kleine set gecombineerde signalen met behulp van een standaard statistisch hulpmiddel dat het merendeel van de variatie behoudt terwijl redundantie wordt verminderd. Dit stelt het rijkere weerbeeld in staat het netwerk te informeren zonder het onhandig of moeilijker te trainen te maken.
Hoe trainingskeuzes het leren vormen
De meeste studies die deze diepe residuenetwerken voor energievraagvoorspelling gebruiken, kiezen geruisloos een populaire trainingsmethode genaamd Adam en laten het daarbij. Trainingsmethode betekent hier het wiskundige recept dat de interne instellingen van het model beetje bij beetje bijstuurt terwijl het leert van historische gegevens. Dit artikel daagt die gewoonte uit door dertien verschillende gradient-gebaseerde trainingsalgoritmen systematisch te vergelijken, waaronder klassieke benaderingen en meerdere moderne adaptieve varianten, allemaal binnen dezelfde modelstructuur. De auteurs testen ze op twee echte datasets: één uit het gematigde New England in de Verenigde Staten en een andere uit tropisch Maleisië.
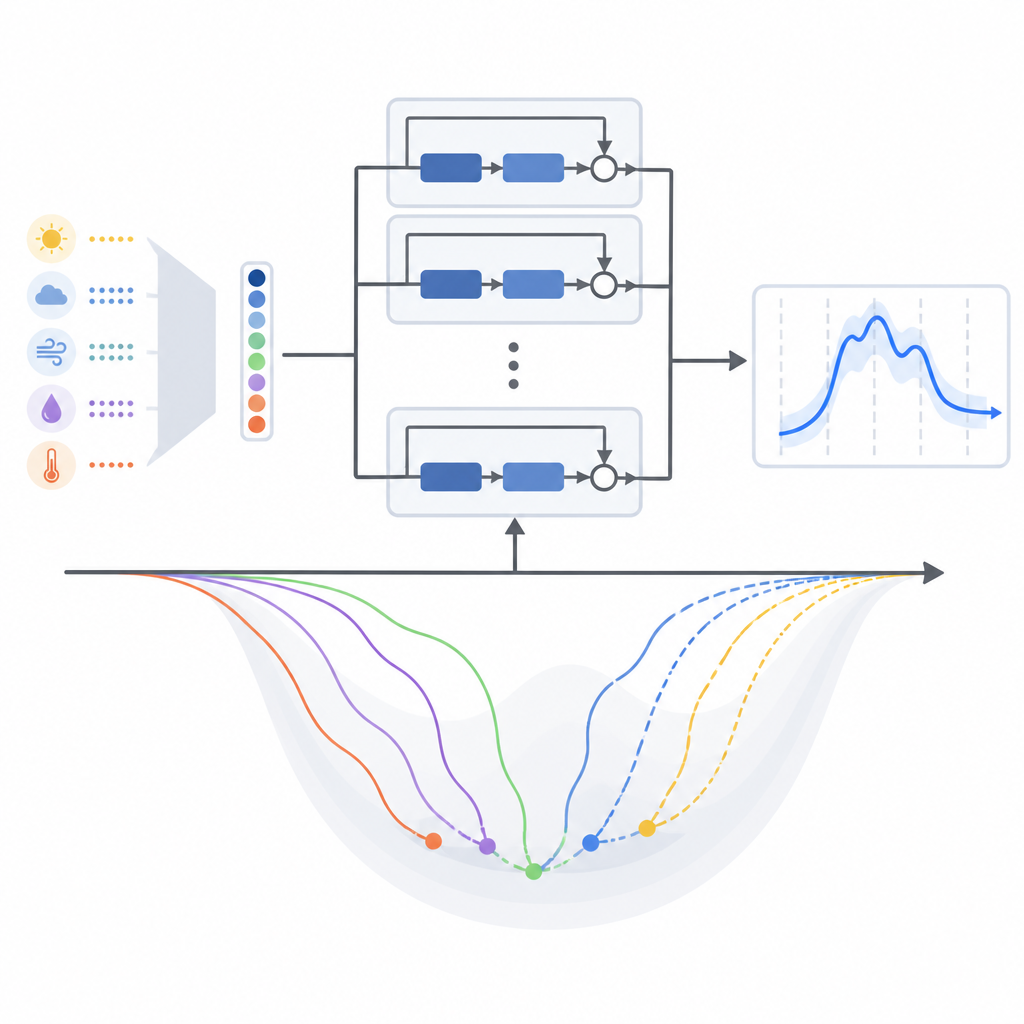
Wat het beste werkte in verschillende klimaten
In beide regio’s waren methoden die hun leerstappen aanpassen op basis van recente foutpatronen over het algemeen beter dan oudere, eenvoudigere benaderingen. Voor het originele model, dat vooral op temperatuur als weersignaal leunt, gaf een variant genaamd AMSGrad de laagste gemiddelde voorspellingsfouten en het meest stabiele trainingsgedrag in beide klimaten. Toen de auteurs overschakelden naar de gecomprimeerde multi-weer-variant van het model, verschoof de balans echter. Onder dit nieuwe invoerontwerp liep een andere adaptieve methode, AdaBelief, iets uit op de rest, en ook Adam presteerde sterk. Met andere woorden: veranderen hoe weerinformatie voor het model wordt verpakt herschikte subtiel het leerlanschap en gaf de voorkeur aan andere trainingsregels.
Controleren dat verbeteringen echt zijn, niet geluk
Om zeker te zijn dat de waargenomen verbeteringen geen statistische ruis waren, gebruikten de auteurs een herbemonsteringsmethode die de voorspellingsopdracht herhaaldelijk afspeelt op licht gevarieerde datasamples. Dit stelde hen in staat in te schatten hoe waarschijnlijk het is dat één trainingsmethode werkelijk beter presteert dan een andere. De tests toonden aan dat meerdere van de waargenomen winstpunten, zoals AMSGrad dat Adam verslaat op de New England-data en de voordelen van de gecomprimeerde-weerbenadering onder bepaalde optimizers in Maleisië, onwaarschijnlijk alleen aan toeval toe te schrijven zijn.
Wat dit betekent voor het toekomstige net
Voor niet-specialisten is de hoofdboodschap dat betere voorspellingen van de energievraag niet alleen gaan over het uitvinden van nieuwe neurale netwerken of het toevoegen van meer weergegevens. De manier waarop die netwerken worden getraind en de wijze waarop weerinvoeren worden gedistilleerd, kunnen de nauwkeurigheid en stabiliteit aanzienlijk veranderen. Door aan te tonen dat sommige adaptieve trainingsregels consequent de prestaties verbeteren, en dat de beste keuze kan afhangen van hoe de invoergegevens worden gerepresenteerd, biedt deze studie netplanners en AI-practitioners een duidelijker recept voor het bouwen van betrouwbaardere voorspellingshulpmiddelen die helpen elektriciteitssystemen zowel veilig als economisch te houden.
Bronvermelding: Liu, J., Ahmad, F.A., Samsudin, K. et al. A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks. Sci Rep 16, 14949 (2026). https://doi.org/10.1038/s41598-026-45829-y
Trefwoorden: kortetermijn-energievraagvoorspelling, diepe residuenetwerken, optimalisatie-algoritmen, voorspelling in energiesystemen, meteorologische kenmerken