Clear Sky Science · it
Valutazione comparativa degli algoritmi di ottimizzazione basati sul gradiente per la previsione a breve termine del carico usando reti residuali profonde
Perché l’uso di energia di domani conta oggi
Ogni volta che accendiamo una luce o colleghiamo un dispositivo, le aziende elettriche devono già avere energia in circolazione per soddisfare quella domanda. Prevedere la domanda di domani con qualche ora o un giorno di anticipo aiuta gli operatori di rete a mantenere le luci accese, evitare blackout e risparmiare denaro. Questo articolo esplora come gli strumenti di intelligenza artificiale moderni possano rendere queste previsioni a breve termine più accurate e più stabili, e mostra che la scelta spesso trascurata del metodo di addestramento può contare tanto quanto il modello stesso.
Stare al passo con una rete in cambiamento
La domanda di elettricità aumenta e diminuisce con l’ora del giorno, la stagione, le festività e il meteo. I metodi statistici tradizionali faticano con questi schemi complessi, specialmente quando sono coinvolti molti segnali diversi. I modelli di deep learning, che impilano molti strati di semplici calcoli, sono diventati popolari perché possono apprendere relazioni sottili e non lineari. Tra questi, un’architettura chiamata rete residua profonda aggiunge connessioni “a scorciatoia” fra gli strati, rendendo i modelli molto profondi più facili da addestrare e migliori nel catturare dipendenze a lungo termine in dati come i carichi elettrici.

Due tipi di cervello consapevole del meteo
Gli autori si concentrano su due modelli residuali profondi strettamente correlati per la previsione a breve termine del carico. Il primo usa l’uso elettrico passato, informazioni temporali (come ora e giorno della settimana) e la temperatura per prevedere le successive 24 ore di domanda. Il secondo modello aggiunge molte più variabili meteorologiche provenienti da una città tropicale, inclusi pioggia e vento, ma le comprime in un piccolo insieme di segnali combinati usando uno strumento statistico standard che mantiene la maggior parte della variazione riducendo la ridondanza. Questo permette al quadro meteorologico più ricco di informare la rete senza renderla ingombrante o più difficile da addestrare.
Come le scelte di addestramento modellano l’apprendimento
La maggior parte degli studi che usa queste reti residuali profonde per la previsione energetica sceglie silenziosamente un metodo di addestramento popolare chiamato Adam e si ferma lì. Per metodo di addestramento si intende qui la ricetta matematica che sposta un po’ alla volta i parametri interni del modello mentre impara dai dati passati. Questo articolo mette in discussione quell’abitudine confrontando sistematicamente tredici diversi algoritmi di addestramento basati sul gradiente, includendo approcci classici e diverse varianti adattive moderne, tutti nella stessa struttura di modello. Gli autori li testano su due dataset reali: uno dal sistema elettrico temperato del New England negli Stati Uniti e un altro dalla Malesia tropicale.
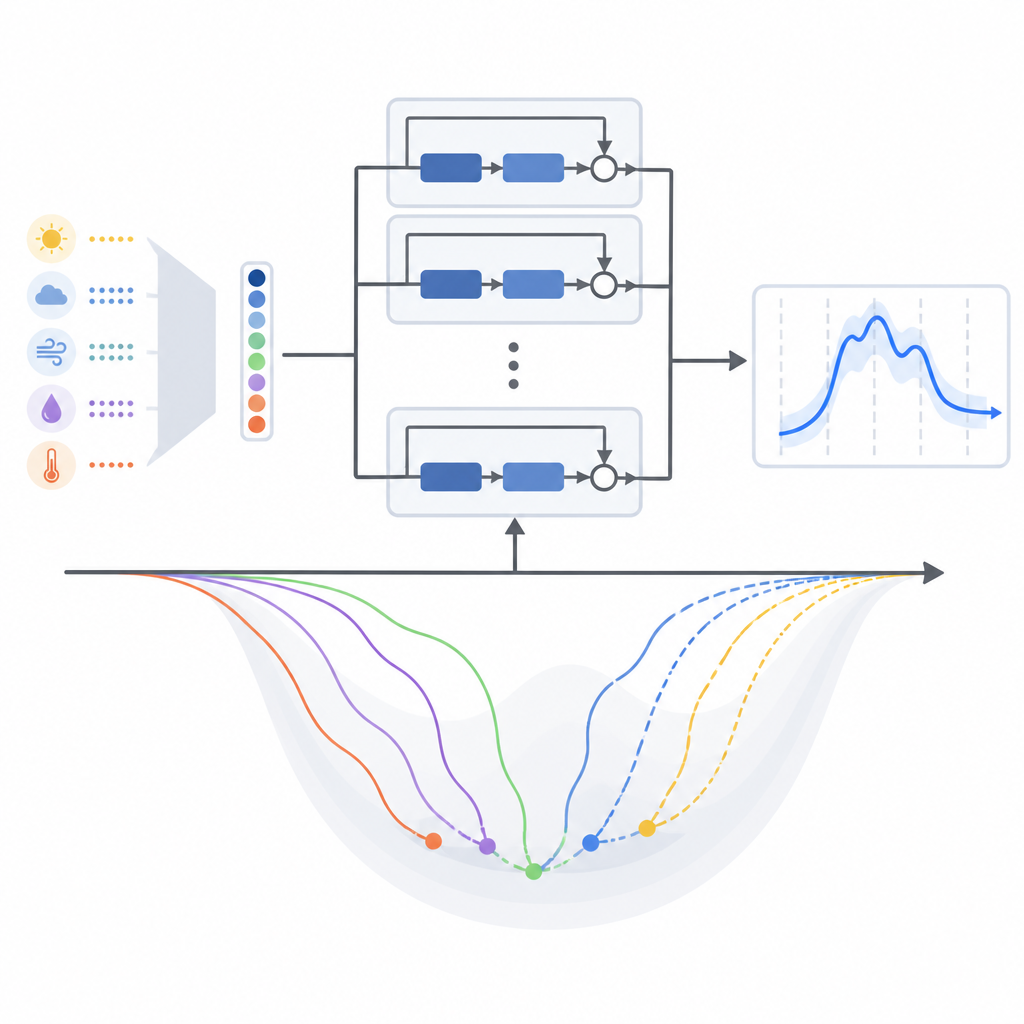
Cosa ha funzionato meglio in climi diversi
In entrambe le regioni, i metodi che adattano i passi di apprendimento usando schemi di errore recenti generalmente superano gli approcci più vecchi e più semplici. Per il modello originale che si basa principalmente sulla temperatura come segnale meteorologico, una variante chiamata AMSGrad ha fornito gli errori di previsione medi più bassi e il comportamento di addestramento più stabile in entrambi i climi. Quando gli autori sono passati alla versione del modello con meteo multi-variabile compresso, tuttavia, l’equilibrio è cambiato. Con questo nuovo design di input, un altro metodo adattivo, AdaBelief, ha preso leggermente il sopravvento, e anche Adam ha avuto buone prestazioni. In altre parole, cambiare il modo in cui l’informazione meteorologica è confezionata per il modello ha rimodellato sottilmente il paesaggio di apprendimento e ha favorito regole di addestramento differenti.
Verificare che i miglioramenti siano reali, non fortuna
Per assicurarsi che i miglioramenti osservati non fossero solo rumore statistico, gli autori hanno usato una tecnica di risampling che ripete ripetutamente il compito di previsione su campioni di dati leggermente variati. Questo ha permesso loro di stimare quanto sia probabile che un metodo di addestramento superi davvero un altro. I test hanno mostrato che diversi dei miglioramenti osservati, come AMSGrad che batte Adam sui dati del New England e i benefici dell’approccio con meteo compresso sotto certi ottimizzatori in Malesia, sono improbabili che siano dovuti al caso.
Cosa significa per la rete elettrica futura
Per i non specialisti, il messaggio principale è che ottenere previsioni migliori della domanda elettrica non riguarda solo l’invenzione di nuove reti neurali o l’inserimento di più dati meteorologici. Il modo in cui quelle reti vengono addestrate e il modo in cui gli input meteorologici sono distillati possono cambiare significativamente accuratezza e stabilità. Dimostrando che alcune regole di addestramento adattive migliorano costantemente le prestazioni, e che la scelta ottimale può dipendere da come i dati di input sono rappresentati, questo studio offre ai pianificatori di rete e ai professionisti dell’IA una ricetta più chiara per costruire strumenti di previsione più affidabili che aiutino a mantenere i sistemi elettrici sicuri ed economici.
Citazione: Liu, J., Ahmad, F.A., Samsudin, K. et al. A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks. Sci Rep 16, 14949 (2026). https://doi.org/10.1038/s41598-026-45829-y
Parole chiave: previsione del carico a breve termine, reti residuali profonde, algoritmi di ottimizzazione, previsione dei sistemi elettrici, variabili meteorologiche