Clear Sky Science · de
Eine vergleichende Bewertung gradientenbasierter Optimierungsalgorithmen für kurzfristige Lastprognosen mit tiefen ResNet
Warum der Stromverbrauch von morgen schon heute wichtig ist
Jedes Mal, wenn wir ein Licht einschalten oder ein Gerät einstecken, müssen Energieversorger bereits Strom bereithalten, um diese Nachfrage zu decken. Die Vorhersage der Nachfrage für die nächsten Stunden oder den nächsten Tag hilft Netzbetreibern, die Versorgung sicherzustellen, Blackouts zu vermeiden und Kosten zu senken. Dieses Papier untersucht, wie moderne KI-Werkzeuge diese kurzfristigen Prognosen genauer und stabiler machen können, und zeigt, dass die oft übersehene Wahl der Trainingsmethode genauso wichtig sein kann wie das Modell selbst.
Mit einem sich wandelnden Netz Schritt halten
Die Stromnachfrage schwankt mit Tageszeit, Jahreszeit, Feiertagen und Wetter. Traditionelle statistische Verfahren haben Schwierigkeiten mit diesen komplexen Mustern, besonders wenn viele verschiedene Signale beteiligt sind. Tiefe Lernmodelle, die viele Lagen einfacher Berechnungen schichten, sind populär geworden, weil sie subtile, nichtlineare Zusammenhänge lernen können. Ein Aufbau namens tiefes Residualnetz fügt „Shortcut“-Verbindungen zwischen den Schichten hinzu, wodurch sehr tiefe Modelle leichter zu trainieren sind und besser langfristige Abhängigkeiten in Daten wie Stromlasten erfassen können.

Zwei wetterbewusste Netzwerktypen
Die Autoren konzentrieren sich auf zwei eng verwandte tiefe Residualmodelle für kurzfristige Lastprognosen. Das erste verwendet vergangene Stromverbräuche, Zeitinformationen (z. B. Stunde und Wochentag) und Temperatur, um die nächsten 24 Stunden Nachfrage vorherzusagen. Das zweite Modell fügt viele weitere Wettervariablen aus einer tropischen Stadt hinzu, darunter Niederschlag und Wind, komprimiert diese jedoch zu einer kleinen Anzahl kombinierter Signale mittels eines standardmäßigen statistischen Verfahrens, das den Großteil der Variation erhält und gleichzeitig Redundanzen reduziert. So kann das reichhaltigere Wetterbild das Netzwerk informieren, ohne es unhandlich oder schwerer zu trainieren zu machen.
Wie Trainingsentscheidungen das Lernen formen
Die meisten Studien, die diese tiefen Residualnetzwerke für Lastprognosen nutzen, wählen stillschweigend eine populäre Trainingsmethode namens Adam und belassen es dabei. Trainingsmethode meint hier das mathematische Rezept, das die internen Einstellungen des Modells beim Lernen aus historischen Daten schrittweise anpasst. Dieses Papier stellt diese Gewohnheit infrage, indem es systematisch dreizehn verschiedene gradientenbasierte Trainingsalgorithmen vergleicht, einschließlich klassischer Ansätze und mehrerer moderner adaptiver Varianten, alle innerhalb derselben Modellstruktur. Die Autoren testen sie an zwei realen Datensätzen: einem aus dem gemäßigten New-England-Stromnetz in den USA und einem weiteren aus dem tropischen Malaysia.
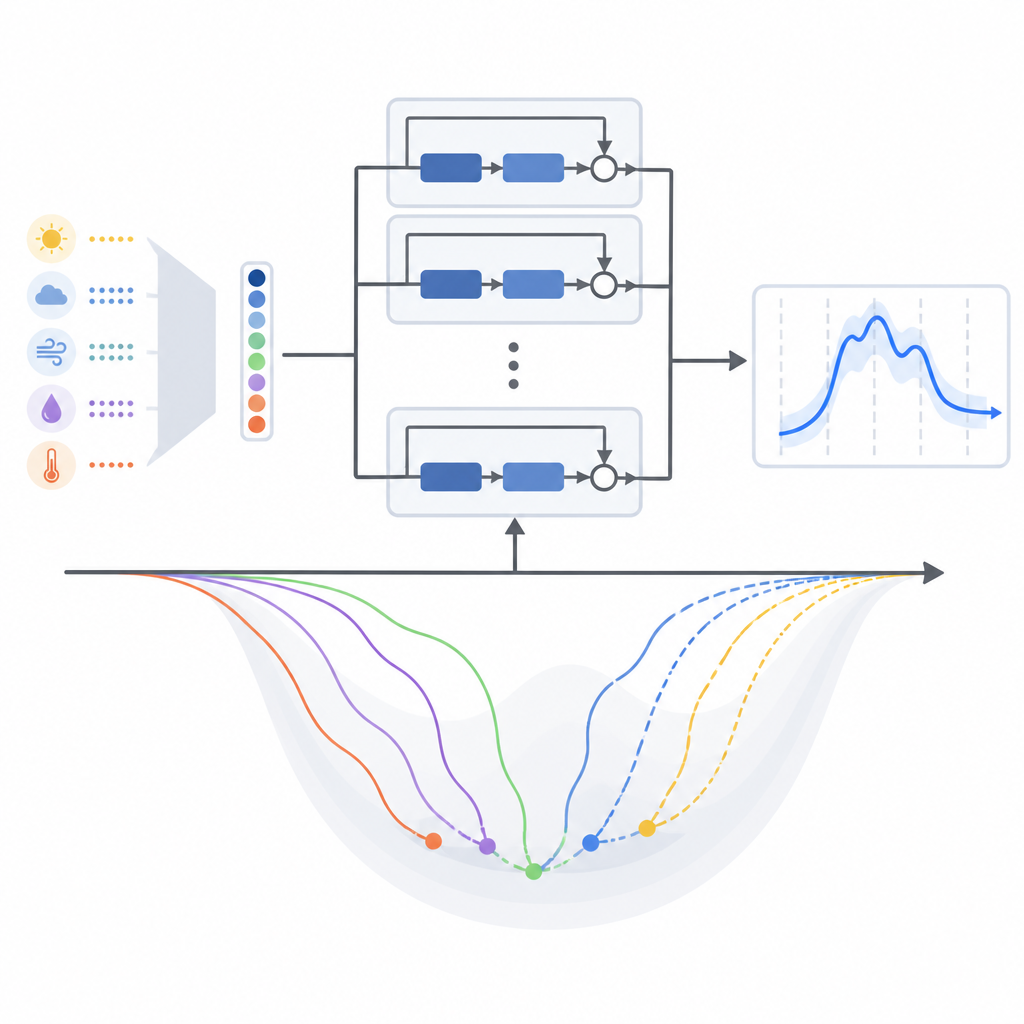
Was in unterschiedlichen Klimazonen am besten funktionierte
In beiden Regionen schnitten Methoden, die ihre Lernschritte anhand jüngster Fehlerverläufe anpassen, allgemein besser ab als ältere, einfachere Ansätze. Für das ursprüngliche Modell, das hauptsächlich auf Temperatur als Wettersignal setzt, erzielte eine Variante namens AMSGrad die niedrigsten durchschnittlichen Prognosefehler und das stabilste Trainingsverhalten in beiden Klimaten. Wechselten die Autoren jedoch zur komprimierten Multi-Wetter-Variante des Modells, verschob sich das Bild. Unter dieser neuen Eingabestruktur lag eine andere adaptive Methode, AdaBelief, vorn, und auch Adam zeigte starke Leistungen. Anders gesagt: Die Änderung der Art und Weise, wie Wetterinformationen für das Modell aufbereitet werden, formte die Lernlandschaft subtil um und begünstigte unterschiedliche Trainingsregeln.
Absichern, dass Verbesserungen echt sind und kein Zufall
Um sicherzustellen, dass die beobachteten Verbesserungen nicht nur statistisches Rauschen waren, verwendeten die Autoren eine Resampling-Technik, die die Prognoseaufgabe wiederholt auf leicht veränderten Datensamples abspielt. Dadurch konnten sie abschätzen, wie wahrscheinlich es ist, dass eine Trainingsmethode der anderen wirklich überlegen ist. Die Tests zeigten, dass mehrere der beobachteten Verbesserungen, etwa AMSGrad gegenüber Adam in den New-England-Daten und die Vorteile des komprimierten Wetteransatzes unter bestimmten Optimierern in Malaysia, kaum allein durch Zufall erklärt werden können.
Was das für das künftige Netz bedeutet
Für Nichtfachleute lautet die Hauptbotschaft: Bessere Lastprognosen hängen nicht nur davon ab, neue neuronale Netze zu erfinden oder mehr Wetterdaten hineinzustopfen. Die Art, wie diese Netze trainiert werden, und wie Wetterinputs verdichtet werden, kann Genauigkeit und Stabilität deutlich verändern. Indem die Studie zeigt, dass einige adaptive Trainingsregeln konsistent die Leistung verbessern und dass die beste Wahl von der Darstellung der Eingabedaten abhängen kann, liefert sie Netzplanern und KI-Praktikern ein klareres Rezept zum Aufbau zuverlässigerer Prognosetools, die Stromsysteme sicherer und wirtschaftlicher halten helfen.
Zitation: Liu, J., Ahmad, F.A., Samsudin, K. et al. A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks. Sci Rep 16, 14949 (2026). https://doi.org/10.1038/s41598-026-45829-y
Schlüsselwörter: kurzfristige Lastprognose, tiefe Residualnetze, Optimierungsalgorithmen, Stromsystemprognosen, meteorologische Merkmale