Clear Sky Science · pt
Avaliação comparativa de algoritmos de otimização baseados em gradiente para previsão de carga de curto prazo usando redes residuais profundas
Por que o consumo de energia de amanhã importa hoje
Cada vez que acendemos uma lâmpada ou conectamos um aparelho, as empresas de energia já precisam ter eletricidade disponível para atender a essa demanda. Estimar a demanda de amanhã com algumas horas ou um dia de antecedência ajuda os operadores da rede a manter as luzes acesas, evitar apagões e economizar dinheiro. Este artigo explora como ferramentas modernas de inteligência artificial podem tornar essas previsões de demanda de curto prazo mais precisas e mais estáveis, e mostra que a escolha muitas vezes negligenciada do método de treinamento pode importar tanto quanto o próprio modelo.
Acompanhando uma rede em transformação
A demanda de eletricidade sobe e desce conforme a hora do dia, a estação, feriados e o tempo. Métodos estatísticos tradicionais têm dificuldade com esses padrões complexos, especialmente quando muitos sinais distintos estão envolvidos. Modelos de aprendizado profundo, que empilham muitas camadas de cálculos simples, tornaram-se populares porque podem aprender relações sutis e não lineares. Entre eles, um projeto chamado rede residual profunda adiciona conexões "atalho" entre camadas, tornando modelos muito profundos mais fáceis de treinar e melhores em capturar dependências de longo prazo em dados como cargas elétricas.

Dois tipos de redes sensíveis ao tempo
Os autores concentram-se em dois modelos residuais profundos intimamente relacionados para previsão de carga de curto prazo. O primeiro usa consumo elétrico passado, informações temporais (como hora e dia da semana) e temperatura para prever as próximas 24 horas de demanda. O segundo modelo adiciona muitas mais variáveis meteorológicas de uma cidade tropical, incluindo precipitação e vento, mas as comprime em um pequeno conjunto de sinais combinados usando uma ferramenta estatística padrão que mantém a maior parte da variação enquanto reduz a redundância. Isso permite que o quadro climático mais rico informe a rede sem torná-la pesada ou mais difícil de treinar.
Como as escolhas de treinamento moldam o aprendizado
A maioria dos estudos que usam essas redes residuais profundas para previsão de energia escolhe silenciosamente um método popular de treinamento chamado Adam e para por aí. Método de treinamento aqui significa a receita matemática que ajusta gradualmente as configurações internas do modelo enquanto ele aprende com dados passados. Este artigo desafia esse hábito ao comparar sistematicamente treze algoritmos de treinamento baseados em gradiente diferentes, incluindo abordagens clássicas e várias variantes adaptativas modernas, todos dentro da mesma estrutura de modelo. Os autores os testam em dois conjuntos de dados do mundo real: um do sistema elétrico temperado de New England, nos Estados Unidos, e outro da Malásia tropical.
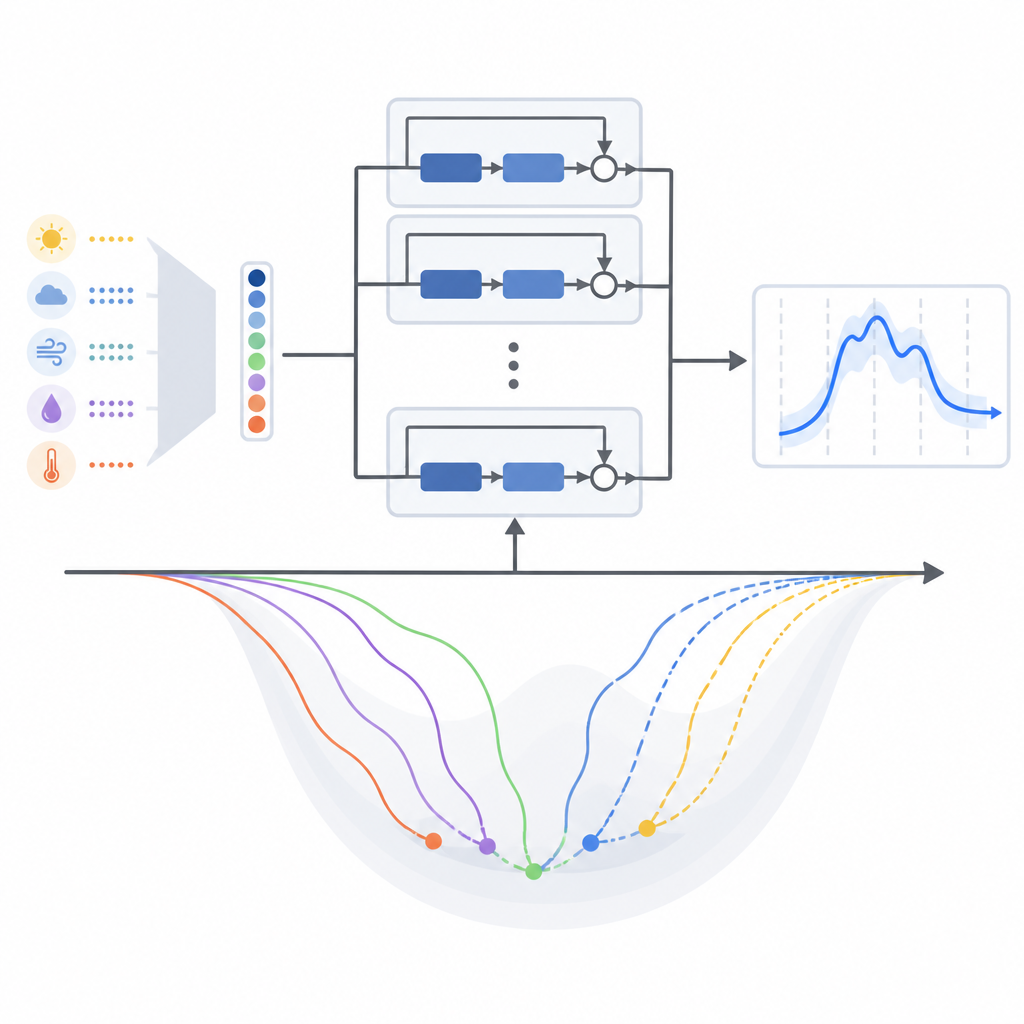
O que funcionou melhor em climas diferentes
Em ambas as regiões, métodos que adaptam seus passos de aprendizagem usando padrões de erro recentes geralmente superaram abordagens mais antigas e simples. Para o modelo original que depende principalmente da temperatura como sinal meteorológico, uma variante chamada AMSGrad apresentou os menores erros médios de previsão e o comportamento de treinamento mais estável em ambos os climas. Quando os autores mudaram para a versão do modelo com clima multi‑variável comprimido, entretanto, o equilíbrio mudou. Sob esse novo desenho de entrada, outro método adaptativo, AdaBelief, ficou à frente, e o Adam também apresentou desempenho forte. Em outras palavras, mudar a forma como a informação meteorológica é empacotada para o modelo remodelou sutilmente a paisagem de aprendizado e favoreceu regras de treinamento diferentes.
Verificando que os ganhos são reais, não sorte
Para garantir que as melhorias observadas não fossem apenas ruído estatístico, os autores usaram uma técnica de reamostragem que reproduz repetidamente a tarefa de previsão em amostras de dados ligeiramente variadas. Isso lhes permitiu estimar quão provável é que um método de treinamento supere realmente outro. Os testes mostraram que várias das melhorias observadas, como o AMSGrad superando o Adam nos dados de New England e os benefícios da abordagem de clima comprimido sob certos otimizadores na Malásia, são improváveis de se dever apenas ao acaso.
O que isso significa para a rede do futuro
Para não especialistas, a mensagem principal é que obter previsões melhores de demanda de energia não se resume apenas a inventar novas redes neurais ou a inserir mais informações meteorológicas nelas. A forma como essas redes são treinadas e a maneira como as entradas meteorológicas são destiladas podem mudar significativamente a precisão e a estabilidade. Ao demonstrar que algumas regras de treinamento adaptativas melhoram consistentemente o desempenho, e que a melhor escolha pode depender de como os dados de entrada são representados, este estudo oferece a planejadores de rede e praticantes de IA uma receita mais clara para construir ferramentas de previsão mais confiáveis que ajudam a manter os sistemas elétricos seguros e econômicos.
Citação: Liu, J., Ahmad, F.A., Samsudin, K. et al. A comparative evaluation of gradient-based optimization algorithms for short-term load forecasting using deep residual networks. Sci Rep 16, 14949 (2026). https://doi.org/10.1038/s41598-026-45829-y
Palavras-chave: previsão de carga de curto prazo, redes residuais profundas, algoritmos de otimização, previsão de sistemas de energia, variáveis meteorológicas