Clear Sky Science · sv
Nollskotts engelska–assamesisk neuralt maskinöversättningssystem via pivotbaserad korsspråklig inbäddningsjustering och transferinlärning
Varför detta spelar roll i vardagliga samtal
Miljarder människor talar språk som stora teknikföretag knappt stödjer. Assamesiska, som talas av miljontals i nordöstra Indien, är ett av dem. Online innebär detta att nyheter, hälsoråd och myndighetsinformation på engelska ofta förblir ouppnåeliga. Denna artikel visar hur man kan bygga ett kraftfullt engelska–assamesiskt översättningssystem även när det nästan saknas direkt träningsdata, genom att smart använda bengali — ett nära besläktat, bättre resurserat språk — som en brygga.
En språkbrygga istället för ett datamonster
Moderna översättningssystem lär sig vanligtvis genom att se miljontals parade meningar: samma rad på till exempel engelska och franska. För assamesiska är sådan parallelldata knapp. Författarna undviker denna flaskhals genom att träna på engelska–bengali-par, där data är mer tillgängliga, och sedan överföra den kunskapen till assamesiska. Eftersom bengali och assamesiska delar liknande grammatik, ordförråd och skrift, kan systemet betrakta bengali som ett steg på vägen och lära mönster som också är meningsfulla för assamesiska utan att någonsin se engelska–assamesiska meningar under träningen.
Att föra tre språk in i ett gemensamt rum
Kärnan i tillvägagångssättet är en flerspråkig modell kallad mBART, som redan har viss kunskap om många språk. Forskarna finjusterar denna modell på engelska–bengali-översättningar och trycker sedan engelska, bengali och assamesiska ord in i en gemensam ”karta” av betydelse. De gör detta med en matematisk procedur kallad Procrustes-justering, som roterar och skalar ordkartorna så att ord med liknande betydelser i de tre språken hamnar nära varandra. Detta delade rum innebär att om systemet har lärt sig hur man översätter ett engelskt ord till bengali, kan det härleda hur man uttrycker ett nära besläktat assamesiskt ord som ligger i samma kvarter på kartan. 
Hantera sällsynta ord och hålla rätt språk
Resursfattiga språk drabbas inte bara av avsaknad av meningspar, utan också av saknade ord — särskilt namn, facktermer och informell slang. För att hantera detta delar systemet upp ord i mindre delar (subord) så att även osedda termer kan sättas ihop av bekanta byggstenar. För de sällsynta fall som fortfarande ligger utanför dess vokabulär hittar det den närmaste kända grannen i det delade betydelserummet och lånar den representationen. Samtidigt får modellen uttryckligen veta vilket språk den ska producera genom speciella språktaggar i ingången. Dessa taggar, tillsammans med de justerade ordrummen, minskar skarpt ett vanligt fel i flerspråkiga system: att av misstag svara på det felaktiga men besläktade språket, till exempel bengali istället för assamesiska.
Sätta ramverket på prov
För att avgöra om alla dessa knep fungerar byggde författarna ett noggrant kontrollerat testset med över tvåtusen engelska–assamesiska meningspar från nyheter, Wikipedia, samtal och tekniska texter. De jämförde sitt system med flera alternativ: små och stora modeller tränade direkt på engelska–assamesiska data, en flerspråkig modell utan språktaggar och en konventionell tvåstegs-pipeline som först översätter engelska till bengali och sedan bengali till assamesiska. Över flera standardiserade automatiska mått slog deras nollskottsystem — tränat utan några direkta engelska–assamesiska par — alla dessa, och överträffade till och med en mycket större modell tränad på 50 000 äkta engelska–assamesiska meningar. Mänskliga bedömare som är modersmålstalare i assamesiska rankade det nya systemets översättningar som både mer korrekta i betydelsen och mer flytande, med felfrekvenser som sjönk med ungefär en tredjedel. 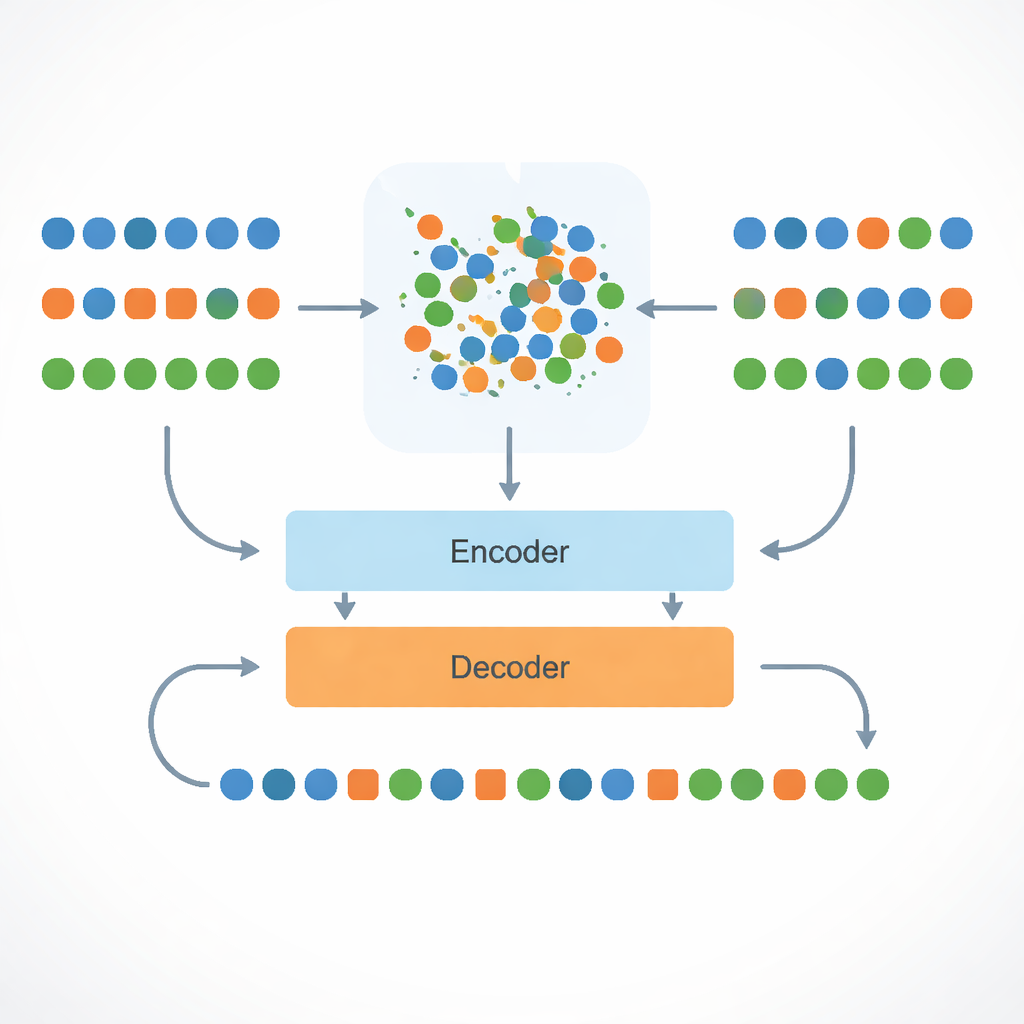
Vad detta betyder för talare av små språk
Enkelt uttryckt visar studien att man inte alltid behöver berg av direkt översättningsdata för att betjäna talare av underrepresenterade språk. Genom att välja ett lingvistiskt nära ”hjälpspråk” som bengali, noggrant justera hur ord från olika tungomål representeras och tydligt signalera önskat målspråk, uppnår författarna stark engelska–assamesiska översättning som är tillräckligt snabb för praktisk användning. Deras ramverk når mer än nittio procent av kvaliteten hos ett idealiskt, fullständigt övervakat system, samtidigt som det kör nästan en tredjedel snabbare vid inferens. Detta tyder på ett lovande recept för att föra högkvalitativ maskinöversättning till många andra resursfattiga språk runt om i världen som har bättre studerade släktingar men väldigt lite egen data.
Citering: Nath, B., Gulzar, Y. Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning. Sci Rep 16, 13732 (2026). https://doi.org/10.1038/s41598-026-44209-w
Nyckelord: maskinöversättning, assamesiska, resursfattig NLP, korsspråkliga inbäddningar, pivot-språk