Clear Sky Science · en
Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning
Why this matters for everyday conversations
Billions of people speak languages that big tech companies barely support. Assamese, spoken by millions in northeast India, is one of them. Online, this means news, health advice, and government information in English often remain out of reach. This paper shows how to build a strong English–Assamese translation system even when there is almost no direct training data, by cleverly using Bengali—a closely related, better-resourced language—as a bridge.
A language bridge instead of a data mountain
Modern translation systems usually learn by seeing millions of paired sentences: the same line in, say, English and French. For Assamese, such parallel data are scarce. The authors avoid this bottleneck by training on English–Bengali pairs, where data are more available, and then transferring that knowledge to Assamese. Because Bengali and Assamese share similar grammar, vocabulary, and script, the system can treat Bengali as a stepping stone, learning patterns that also make sense for Assamese without ever seeing English–Assamese sentence pairs during training.
Bringing three languages into one shared space
At the heart of the approach is a multilingual model called mBART, which already knows something about many languages. The researchers refine this model on English–Bengali translations and then push English, Bengali, and Assamese words into a common “map” of meaning. They do this with a mathematical procedure called Procrustes alignment, which rotates and stretches the word maps so that words with similar meanings in the three languages end up near each other. This shared space means that if the system has learned how to translate an English word into Bengali, it can infer how to express a closely related Assamese word that lives in the same neighborhood on the map. 
Handling rare words and keeping the right language
Low-resource languages suffer not just from missing sentence pairs, but also from missing words—especially names, technical terms, and informal slang. To cope with this, the system breaks words into smaller pieces (subwords) so that even unseen terms can be assembled from familiar building blocks. For the rare cases that still fall outside its vocabulary, it finds the closest known neighbor in the shared meaning space and borrows that representation. At the same time, the model is explicitly told which language it should produce using special language tags at the input. These tags, together with the aligned word spaces, sharply reduce a common failure in multilingual systems: accidentally answering in the wrong but related language, such as Bengali instead of Assamese.
Putting the framework to the test
To judge whether all these tricks work, the authors built a carefully checked test set of over two thousand English–Assamese sentence pairs from news, Wikipedia, conversation, and technical writing. They compared their system against several alternatives: small and large models trained directly on English–Assamese data, a multilingual model without language tags, and a conventional two-step pipeline that translates English to Bengali and then Bengali to Assamese. Across several standard automatic measures, their zero-shot system—trained without any direct English–Assamese pairs—beat all of these, even outperforming a much larger model trained on 50,000 genuine English–Assamese sentences. Human judges who are native Assamese speakers rated the new system’s translations as both more accurate in meaning and more fluent, with error rates dropping by about a third. 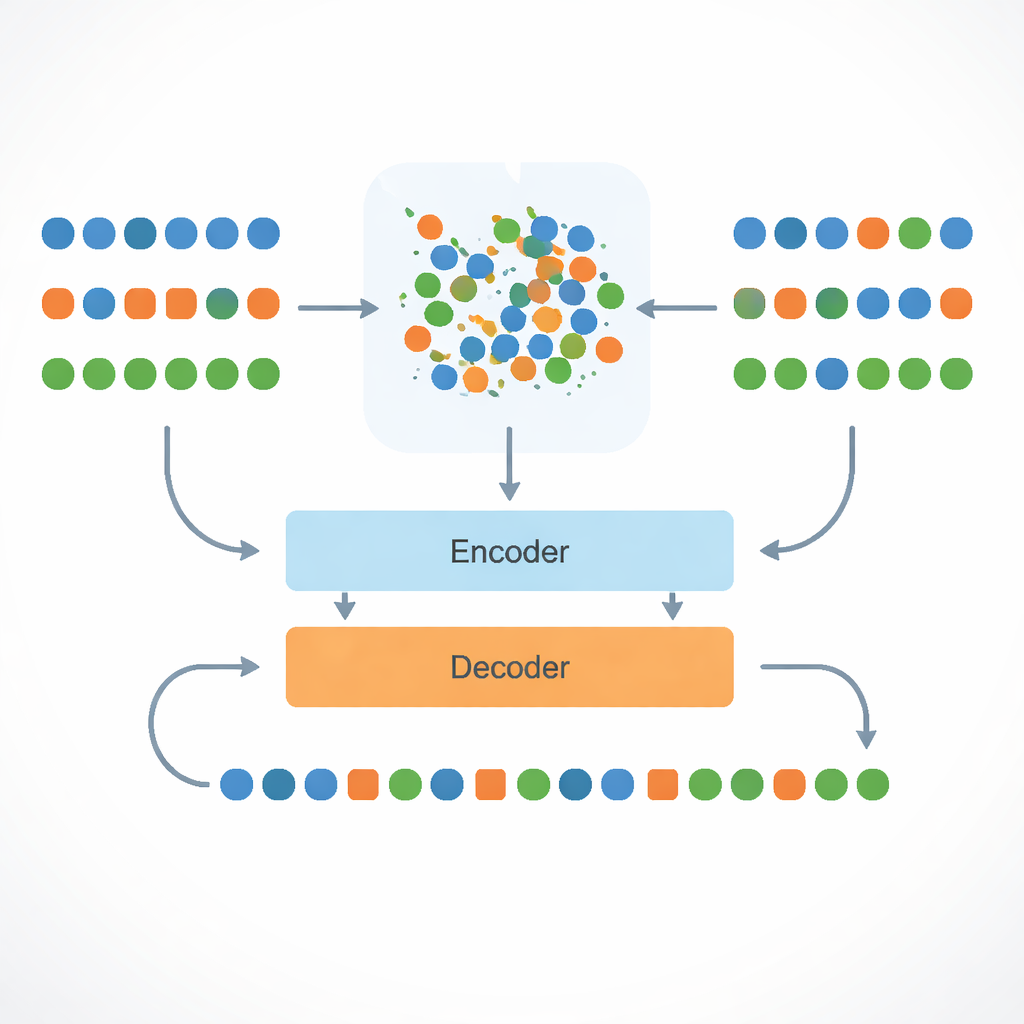
What this means for speakers of small languages
In plain terms, the study shows that you do not always need mountains of direct translation data to serve speakers of underrepresented languages. By choosing a linguistically close “helper” language like Bengali, carefully aligning how words from different tongues are represented, and clearly signaling the desired output language, the authors achieve strong English–Assamese translation that is fast enough for practical use. Their framework reaches more than ninety percent of the quality of an ideal, fully supervised system, while running nearly a third faster at inference. This suggests a promising recipe for bringing high-quality machine translation to many other low-resource languages around the world that have better-studied relatives but very little data of their own.
Citation: Nath, B., Gulzar, Y. Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning. Sci Rep 16, 13732 (2026). https://doi.org/10.1038/s41598-026-44209-w
Keywords: machine translation, Assamese language, low-resource NLP, cross-lingual embeddings, pivot language