Clear Sky Science · fr
Traduction automatique zéro-shot anglais–assamais via alignement d’embeddings cross-lingues par pivot et apprentissage par transfert
Pourquoi cela compte pour les conversations quotidiennes
Des milliards de personnes parlent des langues que les grandes entreprises technologiques prennent peu en charge. L’assamais, parlé par des millions de personnes dans le nord‑est de l’Inde, en fait partie. En ligne, cela signifie que les informations — actualités, conseils de santé et informations gouvernementales — rédigées en anglais restent souvent inaccessibles. Cet article montre comment construire un solide système de traduction anglais–assamais même en l’absence presque totale de données d’entraînement directes, en utilisant astucieusement le bengali — une langue proche et mieux dotée en ressources — comme pont.
Un pont linguistique plutôt qu’une montagne de données
Les systèmes de traduction modernes apprennent généralement en voyant des millions de phrases alignées : la même ligne, par exemple en anglais et en français. Pour l’assamais, de telles données parallèles sont rares. Les auteurs évitent ce goulot d’étranglement en entraînant sur des paires anglais–bengali, pour lesquelles les données sont plus disponibles, puis en transférant ces connaissances à l’assamais. Parce que le bengali et l’assamais partagent une grammaire, un vocabulaire et un système d’écriture similaires, le système peut considérer le bengali comme une étape intermédiaire, apprenant des schémas qui ont aussi du sens pour l’assamais sans avoir jamais vu de paires phrase anglais–assamais pendant l’entraînement.
Faire converger trois langues dans un même espace partagé
Au cœur de l’approche se trouve un modèle multilingue appelé mBART, qui connaît déjà quelque chose de nombreuses langues. Les chercheurs affinent ce modèle sur des traductions anglais–bengali, puis placent les mots anglais, bengali et assamais dans une « carte » commune de sens. Ils font cela avec une procédure mathématique appelée alignement de Procruste, qui fait pivoter et étirer les cartes de mots afin que les mots de sens similaire dans les trois langues se retrouvent proches les uns des autres. Cet espace partagé signifie que si le système a appris à traduire un mot anglais en bengali, il peut en déduire comment exprimer un mot assamais étroitement lié qui se trouve dans le même voisinage sur la carte. 
Gérer les mots rares et garder la bonne langue
Les langues à faibles ressources souffrent non seulement du manque de paires de phrases, mais aussi de l’absence de mots — en particulier les noms propres, les termes techniques et l’argot informel. Pour y faire face, le système décompose les mots en fragments plus petits (sous‑mots) de sorte que même des termes inconnus puissent être assemblés à partir d’éléments familiers. Pour les rares cas qui restent en dehors du vocabulaire, il trouve le voisin connu le plus proche dans l’espace de sens partagé et emprunte cette représentation. Parallèlement, le modèle reçoit explicitement l’indication de la langue qu’il doit produire au moyen d’étiquettes de langue spéciales en entrée. Ces étiquettes, conjuguées aux espaces de mots alignés, réduisent fortement un échec fréquent des systèmes multilingues : répondre par erreur dans une langue proche mais incorrecte, par exemple le bengali au lieu de l’assamais.
Mettre le cadre à l’épreuve
Pour juger de l’efficacité de ces procédés, les auteurs ont constitué un jeu de test soigneusement vérifié de plus de deux mille paires de phrases anglais–assamais tirées de l’actualité, de Wikipédia, de conversations et de textes techniques. Ils ont comparé leur système à plusieurs alternatives : des modèles petits et grands entraînés directement sur des données anglais–assamais, un modèle multilingue sans étiquettes de langue et une chaîne de traitement conventionnelle en deux étapes traduisant l’anglais vers le bengali puis le bengali vers l’assamais. Sur plusieurs mesures automatiques standard, leur système zéro‑shot — entraîné sans aucune paire directe anglais–assamais — a surpassé tous ces concurrents, dépassant même un modèle beaucoup plus volumineux entraîné sur 50 000 phrases anglais–assamais authentiques. Des évaluateurs humains natifs assamais ont jugé les traductions du nouveau système à la fois plus fidèles au sens et plus fluides, avec un taux d’erreur réduit d’environ un tiers. 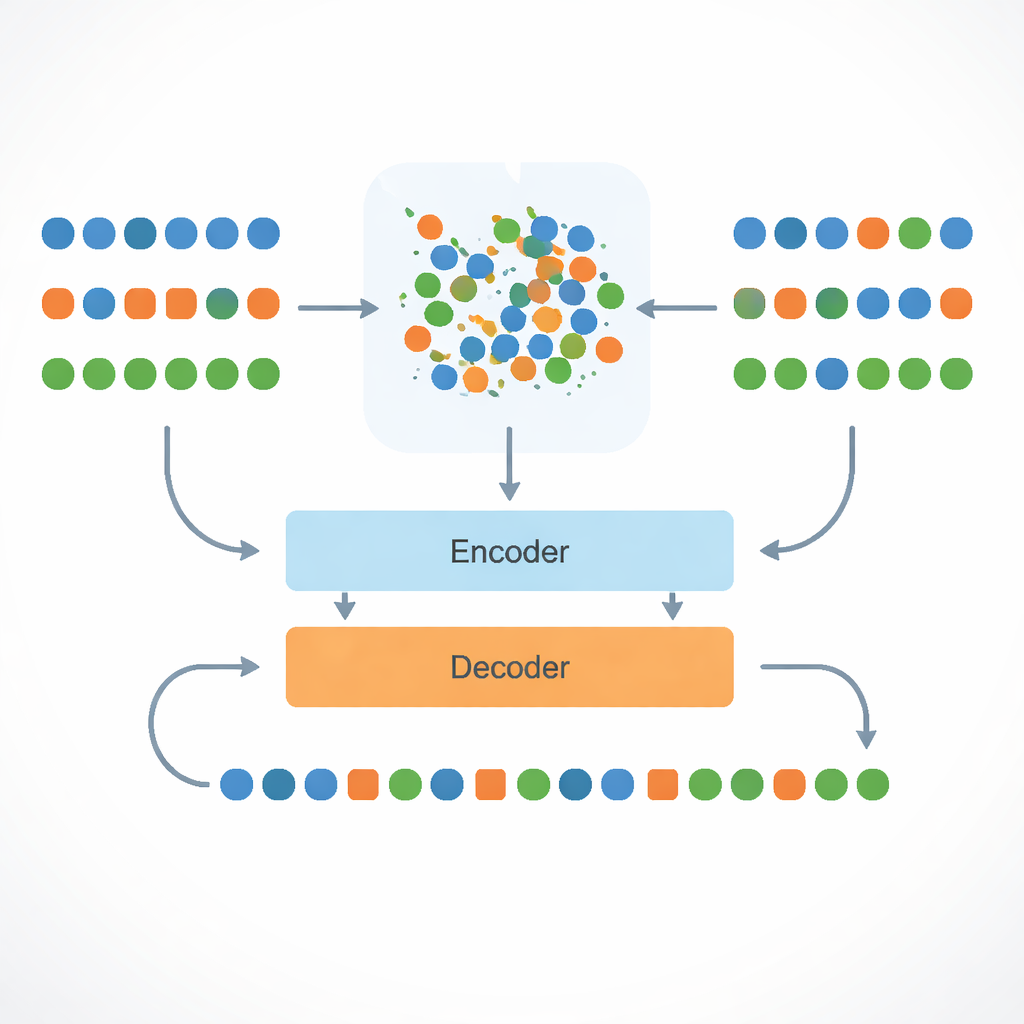
Ce que cela signifie pour les locuteurs de petites langues
Concrètement, l’étude montre qu’il n’est pas toujours nécessaire d’avoir des montagnes de données de traduction directe pour servir les locuteurs de langues sous‑représentées. En choisissant une langue « aide » linguistiquement proche comme le bengali, en alignant soigneusement la représentation des mots de langues différentes et en signalant clairement la langue de sortie souhaitée, les auteurs obtiennent une traduction anglais–assamais performante et suffisamment rapide pour un usage pratique. Leur cadre atteint plus de quatre‑vingt‑dix pour cent de la qualité d’un système idéal entièrement supervisé, tout en s’exécutant près d’un tiers plus vite lors de l’inférence. Cela suggère une recette prometteuse pour apporter une traduction automatique de haute qualité à de nombreuses autres langues à faibles ressources dans le monde, qui ont des parentes mieux étudiées mais très peu de données propres.
Citation: Nath, B., Gulzar, Y. Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning. Sci Rep 16, 13732 (2026). https://doi.org/10.1038/s41598-026-44209-w
Mots-clés: traduction automatique, langue assamaise, TAL à faibles ressources, embeddings cross-lingues, langue pivot