Clear Sky Science · de
Zero-shot English–Assamese neuronale maschinelle Übersetzung über pivotbasierte cross-linguale Einbettungsanpassung und Transferlernen
Warum das für Alltagsgespräche wichtig ist
Milliarden von Menschen sprechen Sprachen, die von großen Tech‑Firmen kaum unterstützt werden. Assamesisch, das von Millionen im Nordosten Indiens gesprochen wird, ist eine davon. Online bedeutet das, dass Nachrichten, Gesundheitsratschläge und staatliche Informationen in Englisch oft unerreichbar bleiben. Dieses Papier zeigt, wie man ein leistungsfähiges Englisch–Assamesisch‑Übersetzungssystem aufbaut, selbst wenn nahezu keine direkten Trainingsdaten vorliegen, indem man geschickt Bengali — eine eng verwandte, besser ausgestattete Sprache — als Brücke nutzt.
Eine Sprachbrücke statt eines Datenbergs
Moderne Übersetzungssysteme lernen normalerweise, indem sie Millionen gepaarter Sätze sehen: dieselbe Zeile etwa auf Englisch und Französisch. Für Assamesisch sind derartige Paralleldaten rar. Die Autorinnen und Autoren umgehen dieses Nadelöhr, indem sie an English–Bengali‑Paaren trainieren, für die mehr Daten verfügbar sind, und dieses Wissen dann auf Assamesisch übertragen. Da Bengali und Assamesisch ähnliche Grammatik, Wortschatz und Schriftsysteme teilen, kann das System Bengali als Zwischenschritt behandeln und Muster lernen, die auch für Assamesisch Sinn ergeben, ohne jemals während des Trainings Englisch–Assamesisch‑Satzpaare gesehen zu haben.
Drei Sprachen in einen gemeinsamen Raum bringen
Im Kern der Methode steht ein multilingualer Modelltyp namens mBART, der bereits etwas über viele Sprachen weiß. Die Forschenden verfeinern dieses Modell auf Englisch–Bengali‑Übersetzungen und bringen dann Englisch-, Bengali‑ und Assamesischwörter in eine gemeinsame „Landkarte“ der Bedeutung. Sie tun dies mit einem mathematischen Verfahren namens Procrustes‑Alignment, das die Wortkarten rotiert und skaliert, sodass Wörter mit ähnlicher Bedeutung in den drei Sprachen nahe beieinander liegen. Dieser gemeinsame Raum ermöglicht, dass, wenn das System gelernt hat, ein englisches Wort ins Bengalische zu übersetzen, es ableiten kann, wie ein eng verwandtes assamesisches Wort ausgedrückt wird, das im selben Nachbarschaftsbereich auf der Karte liegt. 
Umgang mit seltenen Wörtern und Sicherstellung der richtigen Sprache
Ressourcenarme Sprachen leiden nicht nur unter fehlenden Satzpaaren, sondern auch unter fehlenden Wörtern — insbesondere Namen, Fachbegriffe und informeller Slang. Um damit umzugehen, zerlegt das System Wörter in kleinere Einheiten (Subwörter), sodass auch ungesehene Begriffe aus vertrauten Bausteinen zusammengesetzt werden können. Für die seltenen Fälle, die dennoch außerhalb des Vokabulars liegen, findet es den nächstgelegenen bekannten Nachbarn im gemeinsamen Bedeutungsraum und leiht sich dessen Repräsentation. Gleichzeitig wird dem Modell explizit mit speziellen Sprachmarkern am Eingang gesagt, welche Sprache es ausgeben soll. Diese Marker, zusammen mit den ausgerichteten Worträumen, reduzieren deutlich ein häufiges Versagen multilingualer Systeme: versehentlich in der falschen, aber verwandten Sprache zu antworten, etwa Bengali statt Assamesisch.
Das Framework auf die Probe stellen
Um zu beurteilen, ob all diese Tricks funktionieren, bauten die Autorinnen und Autoren einen sorgfältig geprüften Testdatensatz von über zweitausend Englisch–Assamesisch‑Satzpaaren aus Nachrichten, Wikipedia, Gesprächen und Fachtexten auf. Sie verglichen ihr System mit mehreren Alternativen: kleinen und großen Modellen, die direkt auf Englisch–Assamesisch‑Daten trainiert wurden, einem multilingualen Modell ohne Sprachmarker sowie einer konventionellen Zweischritt‑Pipeline, die zuerst Englisch ins Bengalische und dann Bengalisch ins Assamesische übersetzt. Über mehrere standardisierte automatische Metriken hinweg übertraf ihr Zero‑Shot‑System — ohne direkte Englisch–Assamesisch‑Paare trainiert — all diese Ansätze und schlug sogar ein deutlich größeres Modell, das mit 50.000 echten Englisch–Assamesisch‑Sätzen trainiert worden war. Menschliche Prüfer, die Muttersprachler des Assamesischen sind, bewerteten die Übersetzungen des neuen Systems sowohl als genauer in der Bedeutung als auch als flüssiger; die Fehlerquote sank um etwa ein Drittel. 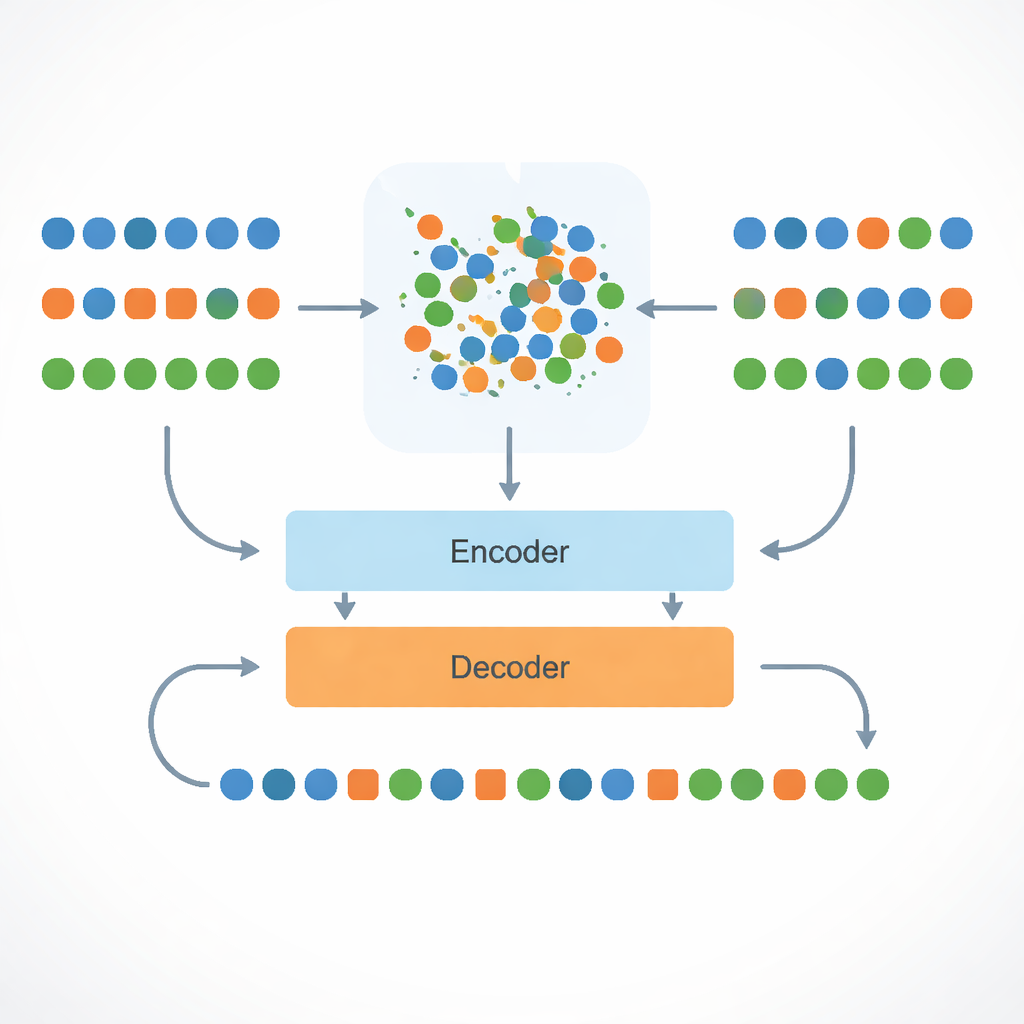
Was das für Sprecher kleiner Sprachen bedeutet
Vereinfacht gesagt zeigt die Studie, dass man nicht immer Berge direkter Übersetzungsdaten braucht, um Sprecher unterrepräsentierter Sprachen zu bedienen. Durch die Wahl einer linguistisch nahen „Hilfssprache“ wie Bengali, das sorgfältige Angleichen der Darstellung von Wörtern aus verschiedenen Sprachen und das deutliche Signalisieren der gewünschten Zielsprache erreichen die Autorinnen und Autoren eine starke Englisch–Assamesisch‑Übersetzung, die schnell genug für den praktischen Einsatz ist. Ihr Framework erreicht mehr als neunzig Prozent der Qualität eines idealen, vollständig überwachten Systems, während es beim Inferenzdurchlauf nahezu ein Drittel schneller ist. Das legt eine vielversprechende Methode nahe, um hochwertige maschinelle Übersetzung für viele andere ressourcenarme Sprachen weltweit zu bringen, die besser untersuchte Verwandte, aber sehr wenige eigene Daten haben.
Zitation: Nath, B., Gulzar, Y. Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning. Sci Rep 16, 13732 (2026). https://doi.org/10.1038/s41598-026-44209-w
Schlüsselwörter: maschinelle Übersetzung, Assamesische Sprache, ressourcenarme NLP, cross-linguale Einbettungen, Pivotsprache