Clear Sky Science · it
Traduzione automatica neurale zero-shot Inglese–Assamese tramite allineamento degli embedding cross-lingua basato su pivot e transfer learning
Perché questo è importante per le conversazioni quotidiane
Miliardi di persone parlano lingue che le grandi aziende tecnologiche supportano a malapena. L’assamese, parlato da milioni di persone nel nord-est dell’India, è una di queste. Online, ciò significa che notizie, consigli sanitari e informazioni governative in inglese spesso rimangono fuori portata. Questo studio mostra come costruire un solido sistema di traduzione Inglese–Assamese anche quando non esistono quasi dati diretti di addestramento, usando in modo intelligente il bengalese — una lingua strettamente imparentata e meglio dotata di risorse — come ponte.
Un ponte linguistico invece di una montagna di dati
I sistemi di traduzione moderni di solito apprendono vedendo milioni di frasi appaiate: la stessa riga per esempio in inglese e francese. Per l’assamese, tali dati paralleli sono scarsi. Gli autori evitano questo collo di bottiglia addestrando su coppie Inglese–Bengalese, dove i dati sono più disponibili, e poi trasferendo quelle conoscenze all’assamese. Poiché bengalese e assamese condividono grammatica, vocabolario e scrittura simili, il sistema può trattare il bengalese come un gradino intermedio, imparando schemi che hanno senso anche per l’assamese senza mai vedere coppie di frasi Inglese–Assamese durante l’addestramento.
Portare tre lingue in uno spazio condiviso
Al centro dell’approccio c’è un modello multilingue chiamato mBART, che conosce già qualcosa su molte lingue. I ricercatori perfezionano questo modello sulle traduzioni Inglese–Bengalese e poi spingono parole inglesi, bengalesi e assamese in una “mappa” comune dei significati. Lo fanno con una procedura matematica chiamata allineamento di Procruste, che ruota e scala le mappe delle parole in modo che parole con significati simili nelle tre lingue finiscano vicine tra loro. Questo spazio condiviso significa che se il sistema ha imparato a tradurre una parola inglese in bengalese, può inferire come esprimere una parola assamese strettamente correlata che vive nello stesso quartiere della mappa. 
Gestire parole rare e mantenere la lingua corretta
Le lingue a bassa risorsa soffrono non solo per la mancanza di coppie di frasi, ma anche per la mancanza di parole — in particolare nomi propri, termini tecnici e gerghi informali. Per affrontare questo, il sistema scompone le parole in pezzi più piccoli (sottoparole) così che anche termini mai visti possano essere ricostruiti da blocchi noti. Per i casi rari che restano fuori dal vocabolario, trova il vicino conosciuto più vicino nello spazio di significato condiviso e ne prende in prestito la rappresentazione. Allo stesso tempo, al modello viene detto esplicitamente quale lingua deve produrre usando tag linguistici speciali in ingresso. Questi tag, insieme agli spazi di parole allineati, riducono nettamente un errore comune nei sistemi multilingue: rispondere accidentalmente nella lingua sbagliata ma correlata, come il bengalese invece dell’assamese.
Mettere il framework alla prova
Per giudicare se tutti questi accorgimenti funzionano, gli autori hanno costruito un set di test controllato con cura di oltre duemila coppie di frasi Inglese–Assamese tratte da notizie, Wikipedia, conversazioni e testi tecnici. Hanno confrontato il loro sistema con diverse alternative: modelli piccoli e grandi addestrati direttamente sui dati Inglese–Assamese, un modello multilingue senza tag linguistici e una pipeline convenzionale in due passi che traduce dall’Inglese al Bengalese e poi dal Bengalese all’Assamese. Su varie misure automatiche standard, il loro sistema zero-shot — addestrato senza alcuna coppia diretta Inglese–Assamese — ha superato tutti questi, e ha persino battuto un modello molto più grande addestrato su 50.000 frasi Inglese–Assamese genuine. Giudici umani madrelingua assamesi hanno valutato le traduzioni del nuovo sistema come più accurate nel significato e più fluide, con tassi di errore ridotti di circa un terzo. 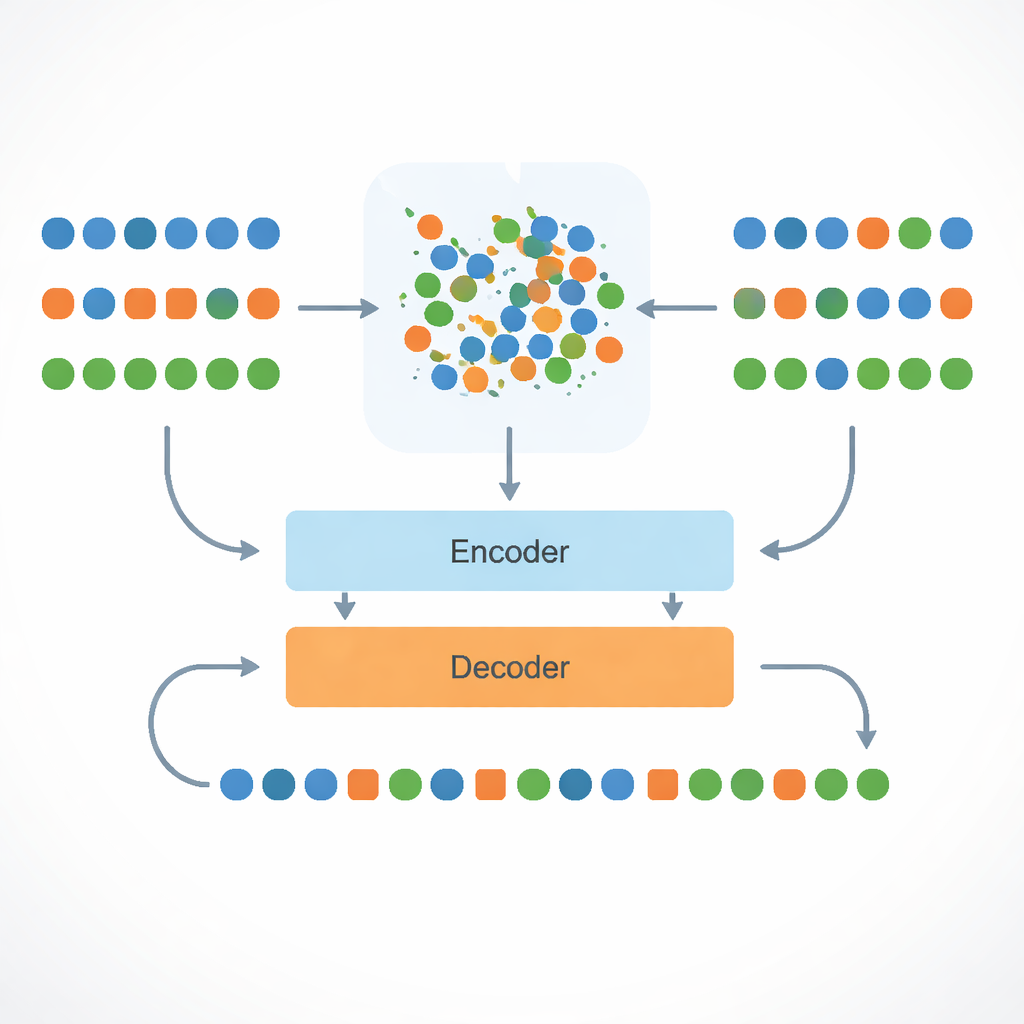
Cosa significa per i parlanti di lingue piccole
In termini semplici, lo studio mostra che non serve sempre una montagna di dati di traduzione diretti per servire i parlanti di lingue poco rappresentate. Scegliendo una lingua “aiutante” linguisticamente vicina come il bengalese, allineando con cura come le parole di lingue diverse sono rappresentate e segnalando chiaramente la lingua di output desiderata, gli autori ottengono una solida traduzione Inglese–Assamese sufficientemente veloce per l’uso pratico. Il loro framework raggiunge oltre il novanta percento della qualità di un sistema ideale completamente supervisionato, pur funzionando quasi un terzo più velocemente in fase di inferenza. Questo suggerisce una ricetta promettente per portare traduzione automatica di alta qualità a molte altre lingue a bassa risorsa nel mondo che hanno parenti meglio studiati ma pochissimi dati propri.
Citazione: Nath, B., Gulzar, Y. Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning. Sci Rep 16, 13732 (2026). https://doi.org/10.1038/s41598-026-44209-w
Parole chiave: traduzione automatica, lingua assamese, NLP a bassa risorsa, embedding cross-lingua, lingua pivot