Clear Sky Science · pt
Tradução neural em zero-shot Inglês–Assamês via alinhamento de embeddings cross-lingual com pivô e aprendizagem por transferência
Por que isso importa nas conversas do dia a dia
Bilhões de pessoas falam línguas que as grandes empresas de tecnologia mal suportam. O assamês, falado por milhões no nordeste da Índia, é um desses casos. Online, isso significa que notícias, conselhos de saúde e informações governamentais em inglês frequentemente ficam inacessíveis. Este artigo mostra como construir um sistema forte de tradução Inglês–Assamês mesmo quando quase não há dados diretos de treinamento, usando de forma inteligente o bengali — uma língua próxima e com mais recursos — como ponte.
Uma ponte linguística em vez de uma montanha de dados
Sistemas modernos de tradução normalmente aprendem vendo milhões de sentenças pareadas: a mesma frase em, por exemplo, inglês e francês. Para o assamês, tais dados paralelos são escassos. Os autores evitam esse gargalo treinando com pares Inglês–Bengali, onde há mais dados disponíveis, e então transferindo esse conhecimento para o assamês. Porque bengali e assamês compartilham gramática, vocabulário e escrita semelhantes, o sistema pode tratar o bengali como um degrau, aprendendo padrões que também fazem sentido para o assamês sem nunca ver pares de sentenças Inglês–Assamês durante o treinamento.
Reunindo três línguas em um único espaço compartilhado
No cerne da abordagem está um modelo multilíngue chamado mBART, que já contém conhecimento sobre muitas línguas. Os pesquisadores refinam esse modelo com traduções Inglês–Bengali e então projetam palavras de inglês, bengali e assamês em um “mapa” comum de significado. Eles fazem isso com um procedimento matemático chamado alinhamento de Procrustes, que rotaciona e estica os mapas de palavras para que termos com significados semelhantes nas três línguas fiquem próximos uns dos outros. Esse espaço compartilhado significa que, se o sistema aprendeu a traduzir uma palavra inglesa para o bengali, pode inferir como expressar uma palavra assamesa relacionada que vive no mesmo bairro do mapa. 
Tratando palavras raras e mantendo a língua correta
Línguas de poucos recursos sofrem não apenas pela falta de pares de sentença, mas também pela ausência de palavras — especialmente nomes, termos técnicos e gírias informais. Para lidar com isso, o sistema divide palavras em pedaços menores (subwords) para que mesmo termos não vistos possam ser montados a partir de blocos familiares. Nos casos raros que ainda caem fora de seu vocabulário, ele encontra o vizinho conhecido mais próximo no espaço de significado compartilhado e toma emprestada essa representação. Ao mesmo tempo, o modelo é explicitamente informado sobre qual língua deve produzir usando etiquetas de idioma especiais na entrada. Essas etiquetas, junto com os espaços de palavras alinhados, reduzem drasticamente uma falha comum em sistemas multilíngues: responder acidentalmente na língua errada, porém relacionada, como bengali em vez de assamês.
Testando o quadro na prática
Para avaliar se todos esses truques funcionam, os autores construíram um conjunto de teste cuidadosamente verificado com mais de dois mil pares de sentenças Inglês–Assamês extraídos de notícias, Wikipédia, conversas e textos técnicos. Eles compararam seu sistema contra várias alternativas: modelos pequenos e grandes treinados diretamente em dados Inglês–Assamês, um modelo multilíngue sem etiquetas de idioma e um pipeline convencional em duas etapas que traduz Inglês para Bengali e depois Bengali para Assamês. Em várias medidas automáticas padrão, seu sistema zero-shot — treinado sem quaisquer pares diretos Inglês–Assamês — superou todos esses, chegando até a superar um modelo muito maior treinado com 50.000 sentenças reais Inglês–Assamês. Avaliadores humanos nativos em assamês classificaram as traduções do novo sistema como mais precisas em significado e mais fluentes, com as taxas de erro caindo cerca de um terço. 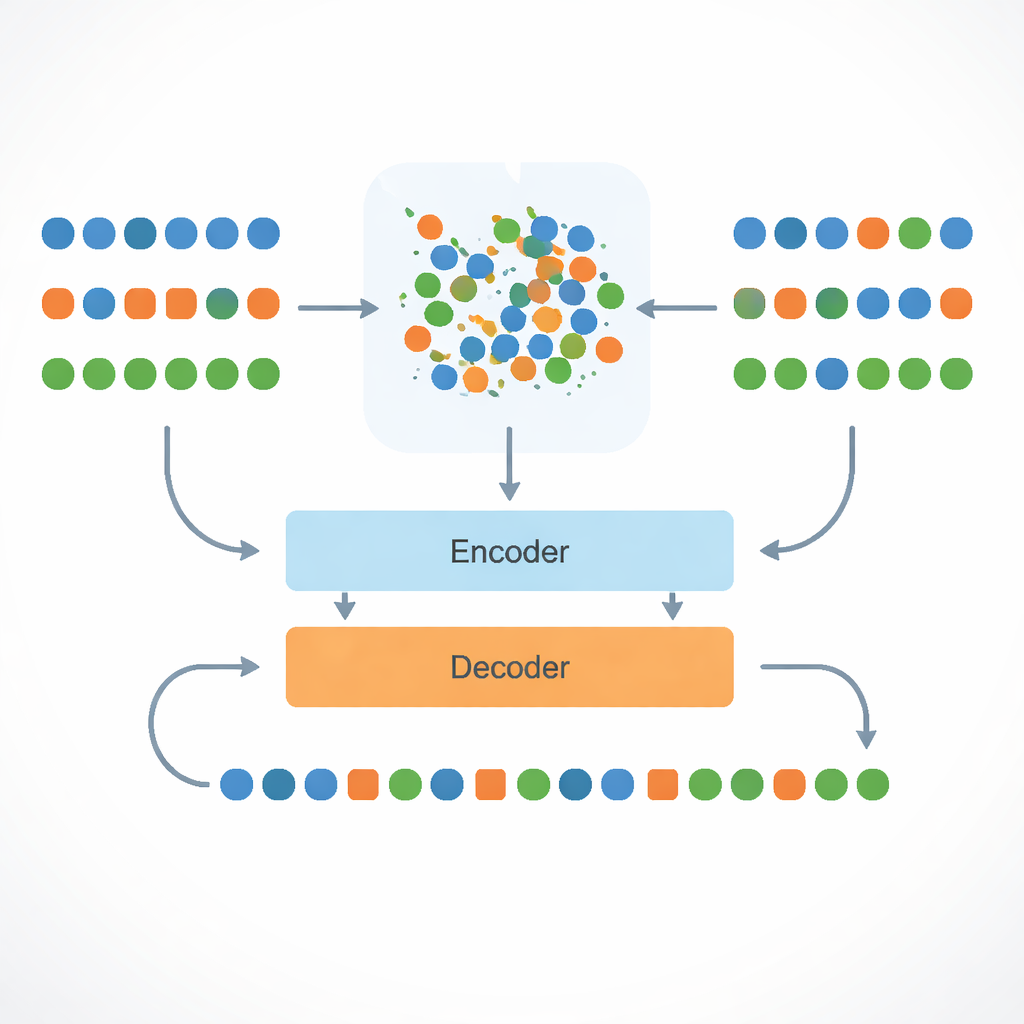
O que isso significa para falantes de línguas pequenas
Em termos simples, o estudo mostra que nem sempre é preciso ter montanhas de dados de tradução direta para atender falantes de línguas subrepresentadas. Ao escolher uma língua “ajudante” linguisticamente próxima como o bengali, alinhar cuidadosamente como palavras de diferentes línguas são representadas e sinalizar claramente a língua de saída desejada, os autores alcançam tradução Inglês–Assamês robusta e rápida o suficiente para uso prático. Seu quadro atinge mais de noventa por cento da qualidade de um sistema ideal totalmente supervisionado, enquanto roda quase um terço mais rápido na inferência. Isso sugere uma receita promissora para levar tradução automática de alta qualidade a muitas outras línguas de poucos recursos pelo mundo que têm parentes melhor estudados, mas pouquíssimos dados próprios.
Citação: Nath, B., Gulzar, Y. Zero-shot English–Assamese neural machine translation via pivot-based cross-lingual embedding alignment and transfer learning. Sci Rep 16, 13732 (2026). https://doi.org/10.1038/s41598-026-44209-w
Palavras-chave: tradução automática, língua assamesa, PBL de baixo recurso, embeddings cross-linguísticos, língua pivô