Clear Sky Science · sv
En YOLOv12-baserad metod för automatisk upptäckt av cefalometriska landmärken på 2D laterala skalle-röntgenbilder
Varför det spelar roll att hitta små punkter i skalle-röntgen
När en ortodontist planerar tandställning, käkkirurgi eller behandling av ansiktsobalanser förlitar sig beslutet på detaljerade mätningar från sidovyer av huvudets röntgenbilder. Dessa mätningar bygger på dussintals små anatomiska referenspunkter utspridda över skalle och ansikte. Idag markeras många av dessa punkter fortfarande för hand, en långsam och delvis subjektiv process. Denna studie undersöker hur ett modernt artificiellt intelligens (AI)-system — en avancerad version av den populära YOLO-familjen för bilddetektion — automatiskt kan hitta dessa nyckellandmärken på skalle-röntgen, med målet att göra ortodontisk vård snabbare, mer konsekvent och lättare att få tillgång till.
Från noggrann avritning till automatiserad vägledning
I nästan ett sekel har ”cefalometrisk analys” varit ryggraden i ortodontisk diagnos. Kliniker studerar en standardiserad sidovy av en röntgenbild och markerar specifika punkter på skalle och mjukvävnader — på käken, tänderna, näsan, läpparna och skallbasen. Från dessa koordinater beräknas vinklar och avstånd som styr behandlingsbeslut. Att göra detta för hand kan ta 10–15 minuter per röntgen och även erfarna experter kan vara oense med ett par millimeter, vilket kan påverka känsliga behandlingsplaner. Eftersom tandvårdspraktiker ser fler patienter och strävar efter ännu större precision ökar trycket att snabba upp detta arbete och minska mänsklig variation utan att förlora expertkontrollen.
Hur modern AI tolkar en röntgen
Senare tiders framsteg inom AI, särskilt djupinlärning, har förändrat hur datorer tolkar bilder. Istället för att programmeras med handgjorda regler lär sig djupa neurala nätverk direkt från stora samlingar av märkta exempel. Inom medicinsk bildbehandling har en klass modeller kallade konvolutionella neurala nätverk blivit särskilt framgångsrika, eftersom de automatiskt kan upptäcka mönster från enkla kanter till komplexa anatomiska former. Inom detta område utmärker sig “You Only Look Once” eller YOLO-familjen för att kunna upptäcka objekt mycket snabbt och i ett enda svep över bilden. Den senaste generationen, YOLOv12, inför uppmärksamhetsmekanismer och multiskal bearbetning som är särskilt användbara för att hitta små, tätt liggande strukturer som cefalometriska landmärken.
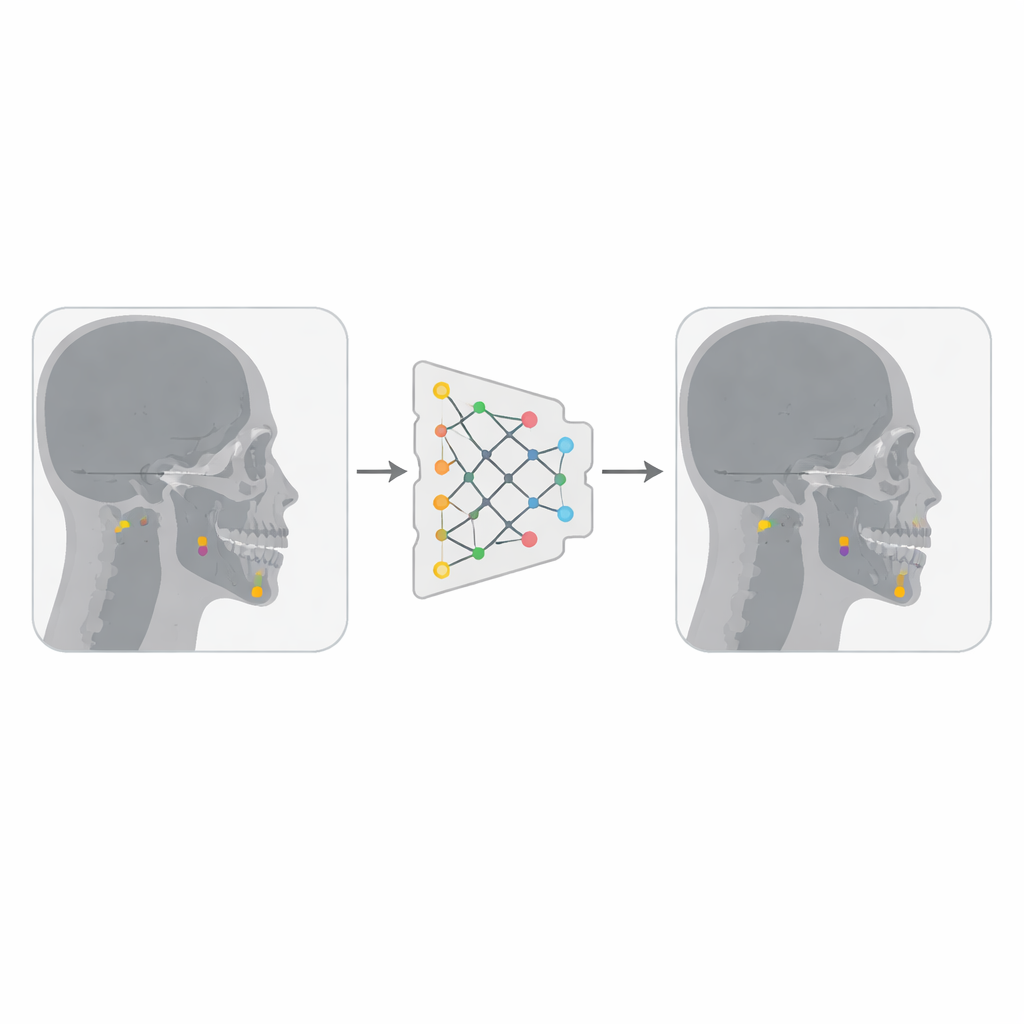
Bygga en smartare landmärkesjägare
Författarna kombinerade två offentligt tillgängliga samlingar av laterala skalle-röntgenbilder, totalt strax under 500 bilder, där varje bild var annoterad med 19 viktiga cefalometriska landmärken av erfarna kliniker. De konverterade bilderna till ett mer kompakt format och gjorde varje landmärkeskoordinat till en liten fyrkantig ”box” centrerad på punkten, så att YOLOv12 — som är designat för att detektera objekt som rutor — kunde behandla varje landmärke som ett litet mål. Med hjälp av plattformen Roboflow tog de bort duplicerade bilder och applicerade blygsamma transformationer såsom små rotationer, ljusstyrkeförändringar och brus. Dessa variationer tredubblade i praktiken antalet träningsbilder, vilket hjälpte modellen att bli mer robust mot skillnader i bildkvalitet och patientanatomi.
Inuti AI:ns träning och testning
Forskarna tränade en stor YOLOv12-modell på en kraftfull grafisk processor under 50 träningsomgångar, eller epoker. Under träningen lärde sig modellens interna lager att omvandla rå röntgen till ett uppsättning funktioner som framhäver viktiga områden, och dess utgångsdel lärde sig att rita en liten ruta runt varje landmärke och tilldela den en konfidenspoäng. När träningen avslutats testades modellen på 94 röntgenbilder den aldrig tidigare sett. För att bedöma prestanda mätte teamet hur långt varje förutsagt landmärke låg från motsvarande expertmarkerade punkt. De granskade också precision–recall-kurvor, förväxlingsmönster mellan olika landmärken och detaljerade diagram som visar överensstämmelse för specifika punkter.
Vad AI:n klarade — och var den hade svårigheter
Överlag fann systemet ungefär hälften av alla landmärken inom 1 millimeter från expertmarkeringarna, och knappt över 80 procent inom 2 millimeter — ett spann som anses acceptabelt för många kliniska uppgifter. Det presterade mycket bra för landmärken med tydliga former och stark kontrast, såsom Sella, Gnathion, Menton och vissa tandrelaterade punkter, där mer än tre fjärdedelar av förutsägelserna låg inom 1 millimeter och över 93 procent inom 2 millimeter. Modellen presterade också oväntat bra på att särskilja kluster av närliggande punkter runt hakan och framtänderna, vilket tyder på att den lärt sig subtila rumsliga relationer, inte bara isolerade pixlar. Däremot hade den svårigheter med landmärken i mer oklara regioner, såsom Gonion, Subspinale, Orbitale, Articulare och Porion. Dessa områden är svåra även för människor eftersom överlappande ben och låg kontrast gör gränserna otydliga, och dålig röntgenkvalitet förvärrade noggrannheten ytterligare.
Vad detta betyder för framtida ortodontisk vård
Författarna drar slutsatsen att deras YOLOv12-baserade system ännu inte är redo att ersätta mänskliga experter, men det är ett starkt proof of concept för semi-automatiserad cefalometrisk analys. I praktiska termer skulle ett sådant verktyg snabbt kunna placera preliminära landmärken som kliniker sedan finjusterar, vilket blandar AI:s hastighet och konsekvens med professionellt omdöme. Med större och mer mångsidiga träningsdatamängder, bättre hantering av bilder av låg kvalitet och fortsatt förfining av modellen kan framtida versioner närma sig verklig klinisk kvalitet. Om så sker kan ortodontister snart ägna mindre tid åt att manuellt avrita röntgenbilder och mer tid åt att använda dessa mätningar för att utforma personliga behandlingsplaner.
Citering: Akre, P.D., Ghavghave, Y.G. & Pacharaney, U. A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images. Sci Rep 16, 12837 (2026). https://doi.org/10.1038/s41598-026-43250-z
Nyckelord: cefalometrisk analys, ortodontisk bilddiagnostik, djupinlärning, landmärkesdetektion, YOLOv12