Clear Sky Science · fr
Une approche basée sur YOLOv12 pour la détection automatique des repères céphalométriques sur des radiographies latérales 2D du crâne
Pourquoi repérer de tout petits points sur des radiographies du crâne est important
Lorsqu’un orthodontiste planifie un appareil dentaire, une chirurgie maxillo-faciale ou un traitement des déséquilibres faciaux, il s’appuie sur des mesures détaillées prises à partir de radiographies latérales de la tête. Ces mesures dépendent de dizaines de petits points anatomiques de référence répartis sur le crâne et le visage. Aujourd’hui, bon nombre de ces points sont encore marqués à la main, un processus lent et en partie subjectif. Cette étude examine comment un système d’intelligence artificielle (IA) moderne — une version avancée de la populaire famille d’algorithmes YOLO — peut automatiquement localiser ces repères clés sur des radiographies du crâne, dans le but d’accélérer les soins orthodontiques, d’en améliorer la cohérence et d’en faciliter l’accès.
Du traçage minutieux à l’assistance automatisée
Depuis près d’un siècle, « l’analyse céphalométrique » constitue l’ossature du diagnostic orthodontique. Les cliniciens examinent une radiographie standardisée de profil et marquent des points spécifiques sur le crâne et les tissus mous — sur la mâchoire, les dents, le nez, les lèvres et la base du crâne. À partir de ces coordonnées, ils calculent des angles et des distances qui orientent les décisions thérapeutiques. Faire cela manuellement peut prendre 10 à 15 minutes par radiographie, et même des experts expérimentés peuvent diverger de quelques millimètres, ce qui peut influer sur des plans de traitement délicats. À mesure que les cabinets dentaires voient davantage de patients et visent une précision toujours plus fine, la pression augmente pour accélérer ce travail et réduire la variabilité humaine sans perdre l’avis d’experts.
Comment l’IA moderne « voit » une radiographie
Les progrès récents de l’IA, et en particulier de l’apprentissage profond, ont transformé la manière dont les ordinateurs interprètent les images. Plutôt que d’être programmés par des règles faites à la main, les réseaux neuronaux profonds apprennent directement à partir de larges collections d’exemples annotés. En imagerie médicale, une classe de modèles appelée réseaux convolutionnels s’est montrée particulièrement performante, car elle peut découvrir automatiquement des motifs allant des contours simples aux formes anatomiques complexes. Dans ce paysage, la famille « You Only Look Once » ou YOLO se distingue par sa capacité à repérer des objets très rapidement et en un seul passage sur l’image. La génération la plus récente, YOLOv12, intègre des mécanismes d’attention et un traitement multi-échelle particulièrement utiles pour détecter de petites structures voisines comme les repères céphalométriques.
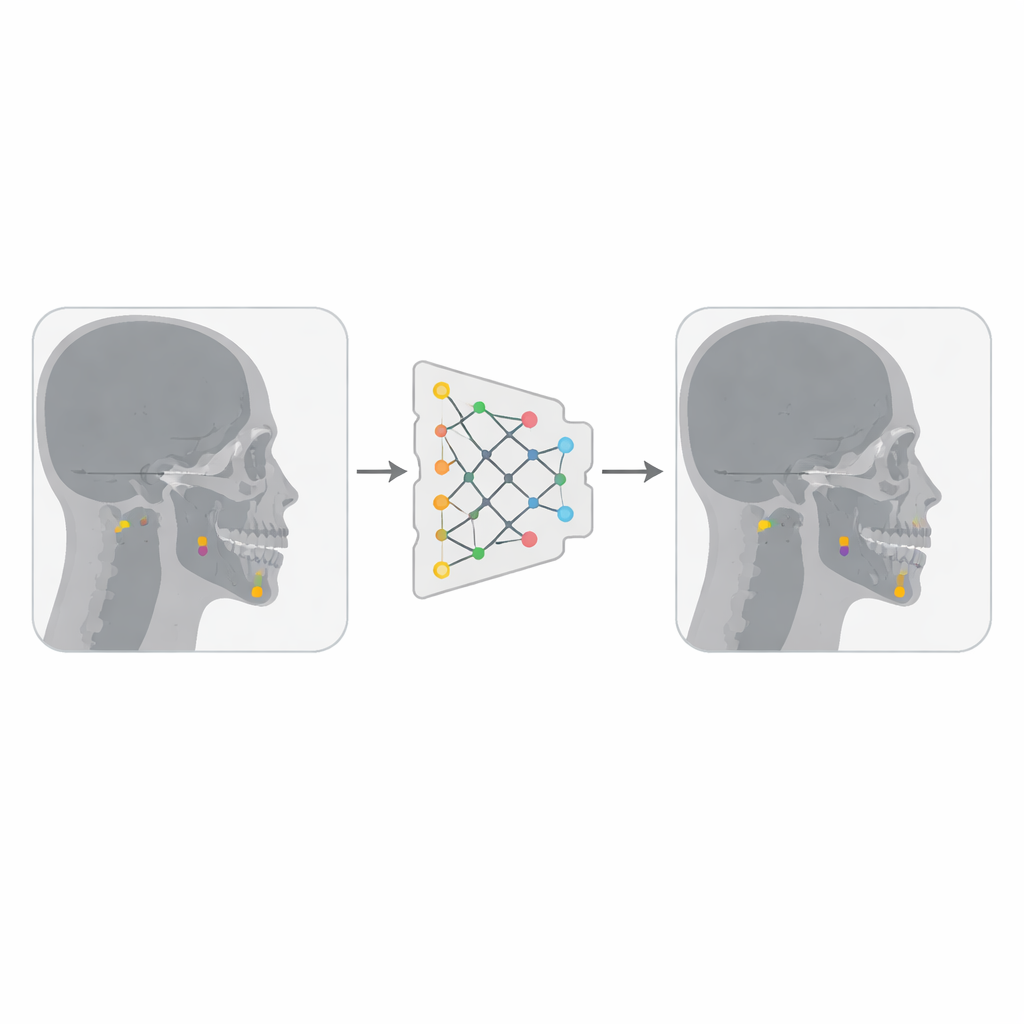
Construire un détecteur de repères plus intelligent
Les auteurs ont combiné deux collections publiques de radiographies latérales du crâne, totalisant un peu moins de 500 images, chacune annotée par des cliniciens expérimentés avec 19 repères céphalométriques importants. Ils ont converti les images dans un format plus compact et transformé chaque coordonnée de repère en un petit « carré » centré sur le point, afin que YOLOv12 — conçu pour détecter des objets sous forme de boîtes — puisse traiter chaque repère comme une cible minuscule. En utilisant une plateforme appelée Roboflow, ils ont supprimé les images en double et appliqué des transformations modestes comme de légères rotations, des variations de luminosité et du bruit. Ces variations ont effectivement triplé le nombre d’images d’entraînement, aidant le modèle à devenir plus robuste aux différences de qualité d’image et d’anatomie des patients.
À l’intérieur de l’entraînement et des tests de l’IA
Les chercheurs ont entraîné un grand modèle YOLOv12 sur un processeur graphique puissant pendant 50 cycles d’apprentissage, ou époques. Pendant l’entraînement, les couches internes du modèle ont appris à convertir la radiographie brute en un ensemble de caractéristiques mettant en évidence les zones importantes, et sa « tête » de sortie a appris à dessiner une petite boîte autour de chaque repère et à lui attribuer un score de confiance. Une fois l’entraînement terminé, le modèle a été testé sur 94 radiographies qu’il n’avait jamais vues. Pour évaluer les performances, l’équipe a mesuré l’écart entre chaque repère prédit et son équivalent marqué par un expert. Ils ont aussi examiné les courbes précision-rappel, les confusions entre repères différents et des graphiques détaillés montrant l’accord pour des points spécifiques.
Ce que l’IA a bien fait — et où elle a peiné
Globalement, le système a localisé environ la moitié des repères à moins de 1 millimètre des marques d’experts, et un peu plus de 80 % à moins de 2 millimètres — une plage considérée acceptable pour de nombreuses tâches cliniques. Il a excellé sur des repères aux contours nets et au fort contraste, comme Sella, Gnathion, Menton et certains points liés aux dents, où plus des trois quarts des prédictions se trouvaient dans un rayon de 1 millimètre et plus de 93 % dans un rayon de 2 millimètres. Le modèle s’en est également bien sorti pour distinguer des groupes de points proches autour du menton et des incisives, suggérant qu’il avait appris des relations spatiales subtiles, pas seulement des pixels isolés. En revanche, il a eu des difficultés avec des repères situés dans des régions plus floues, comme Gonion, Subspinale, Orbitale, Articulare et Porion. Ces zones sont plus difficiles même pour les humains car des os qui se chevauchent et un faible contraste rendent les limites peu nettes, et une mauvaise qualité d’image a encore dégradé la précision.
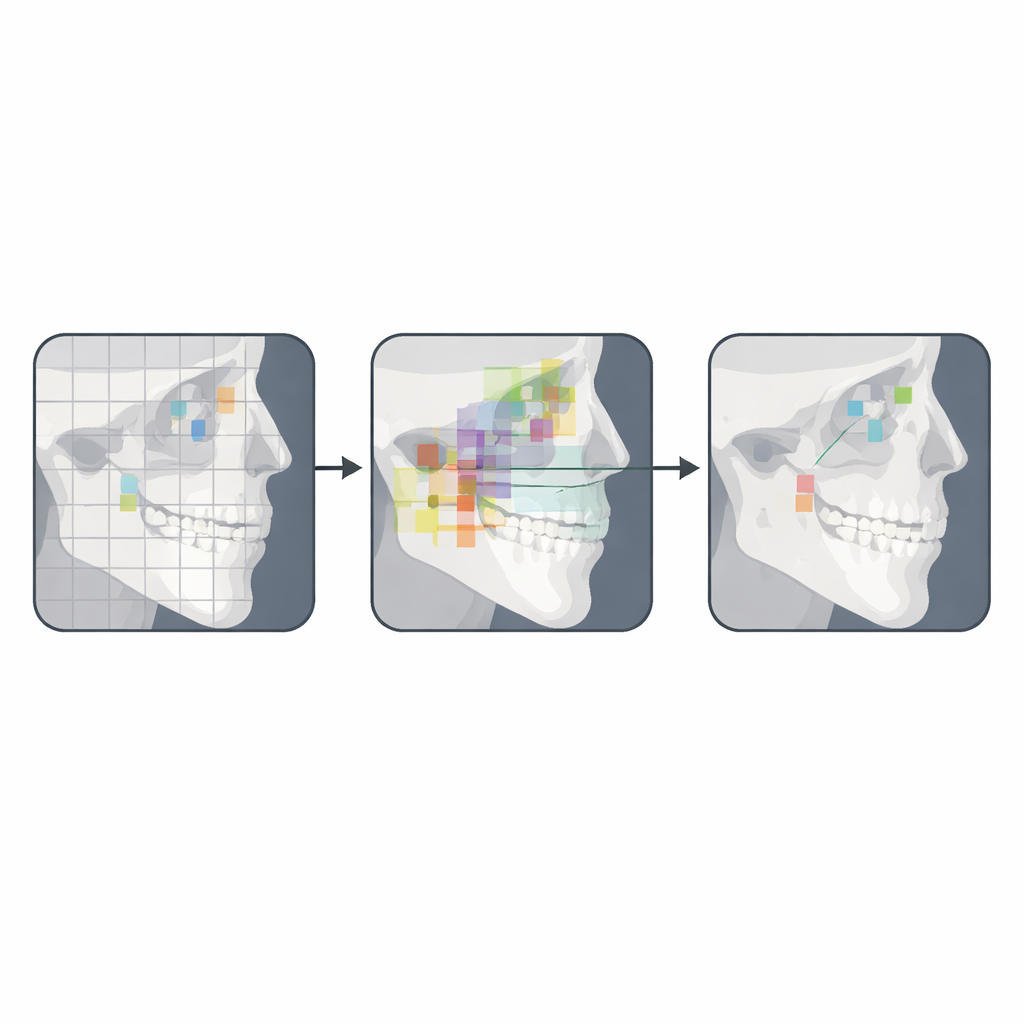
Ce que cela signifie pour les soins orthodontiques à venir
Les auteurs concluent que leur système basé sur YOLOv12 n’est pas encore prêt à remplacer les experts humains, mais constitue une solide preuve de concept pour l’analyse céphalométrique semi-automatisée. Concrètement, un tel outil pourrait positionner rapidement des repères préliminaires que les cliniciens ajusteraient ensuite, combinant la rapidité et la cohérence de l’IA avec le jugement professionnel. Avec des jeux de données d’entraînement plus vastes et diversifiés, une meilleure gestion des images de faible qualité et un affinage continu du modèle, les versions futures pourraient atteindre une performance de niveau clinique. Si tel est le cas, les orthodontistes pourraient bientôt passer moins de temps à tracer manuellement des radiographies et davantage de temps à utiliser ces mesures pour élaborer des plans de traitement personnalisés.
Citation: Akre, P.D., Ghavghave, Y.G. & Pacharaney, U. A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images. Sci Rep 16, 12837 (2026). https://doi.org/10.1038/s41598-026-43250-z
Mots-clés: analyse céphalométrique, imagerie orthodontique, apprentissage profond, détection de repères, YOLOv12