Clear Sky Science · de
Ein YOLOv12-basierter Ansatz zur automatischen Erkennung cephalometrischer Landmarken auf 2D-lateralen Schädelröntgenaufnahmen
Warum das Erkennen winziger Punkte in Schädelröntgenaufnahmen wichtig ist
Wenn ein Kieferorthopäde eine Zahnspange, eine Kieferoperation oder eine Therapie für Gesichtsasymmetrien plant, verlässt er sich auf detaillierte Messungen aus seitlichen Röntgenaufnahmen des Kopfes. Diese Messungen basieren auf Dutzenden winziger anatomischer Referenzpunkte, die über Schädel und Gesicht verteilt sind. Noch werden viele dieser Punkte von Hand markiert, ein zeitaufwändiger und bisweilen subjektiver Prozess. Diese Studie untersucht, wie ein modernes System der künstlichen Intelligenz (KI) — eine weiterentwickelte Version der bekannten YOLO-Bilddetektionsfamilie — diese Schlüssel-Landmarken auf Schädelröntgenaufnahmen automatisch finden kann, mit dem Ziel, die kieferorthopädische Versorgung schneller, konsistenter und besser zugänglich zu machen.
Vom sorgfältigen Nachzeichnen zur automatisierten Unterstützung
Seit nahezu einem Jahrhundert ist die „cephalometrische Analyse“ die Grundlage der kieferorthopädischen Diagnose. Kliniker betrachten eine standardisierte Seitenaufnahme und markieren bestimmte Punkte am Schädel und an Weichteilen — am Kiefer, an den Zähnen, an Nase, Lippen und Schädelbasis. Aus diesen Koordinaten berechnen sie Winkel und Abstände, die die Behandlungsplanung steuern. Die manuelle Erfassung kann 10–15 Minuten pro Röntgenbild dauern, und selbst erfahrene Expertinnen und Experten können um ein bis zwei Millimeter voneinander abweichen, was empfindliche Behandlungsentscheidungen beeinflussen kann. Da Praxen mehr Patientinnen und Patienten sehen und eine immer feinere Präzision anstreben, wächst der Druck, diese Arbeit zu beschleunigen und menschliche Variabilität zu reduzieren, ohne die fachliche Aufsicht aufzugeben.
Wie moderne KI ein Röntgenbild „sieht”
Jüngste Fortschritte in der KI, insbesondere im Deep Learning, haben die Bildinterpretation durch Computer verändert. Anstatt mit handgefertigten Regeln programmiert zu werden, lernen tiefe neuronale Netze direkt aus großen Sammlungen beschrifteter Beispiele. In der medizinischen Bildgebung haben sich insbesondere konvolutionale neuronale Netze durchgesetzt, weil sie automatisch Muster entdecken können — von einfachen Kanten bis hin zu komplexen anatomischen Formen. In diesem Umfeld zeichnet sich die „You Only Look Once“-Familie (YOLO) dadurch aus, Objekte sehr schnell und in einem einzigen Durchgang über das Bild zu erkennen. Die neueste Generation, YOLOv12, integriert Aufmerksamkeitsmechanismen und Multi-Skalen-Verarbeitung, die besonders hilfreich sind, um kleine, dicht beieinander liegende Strukturen wie cephalometrische Landmarken zu finden.
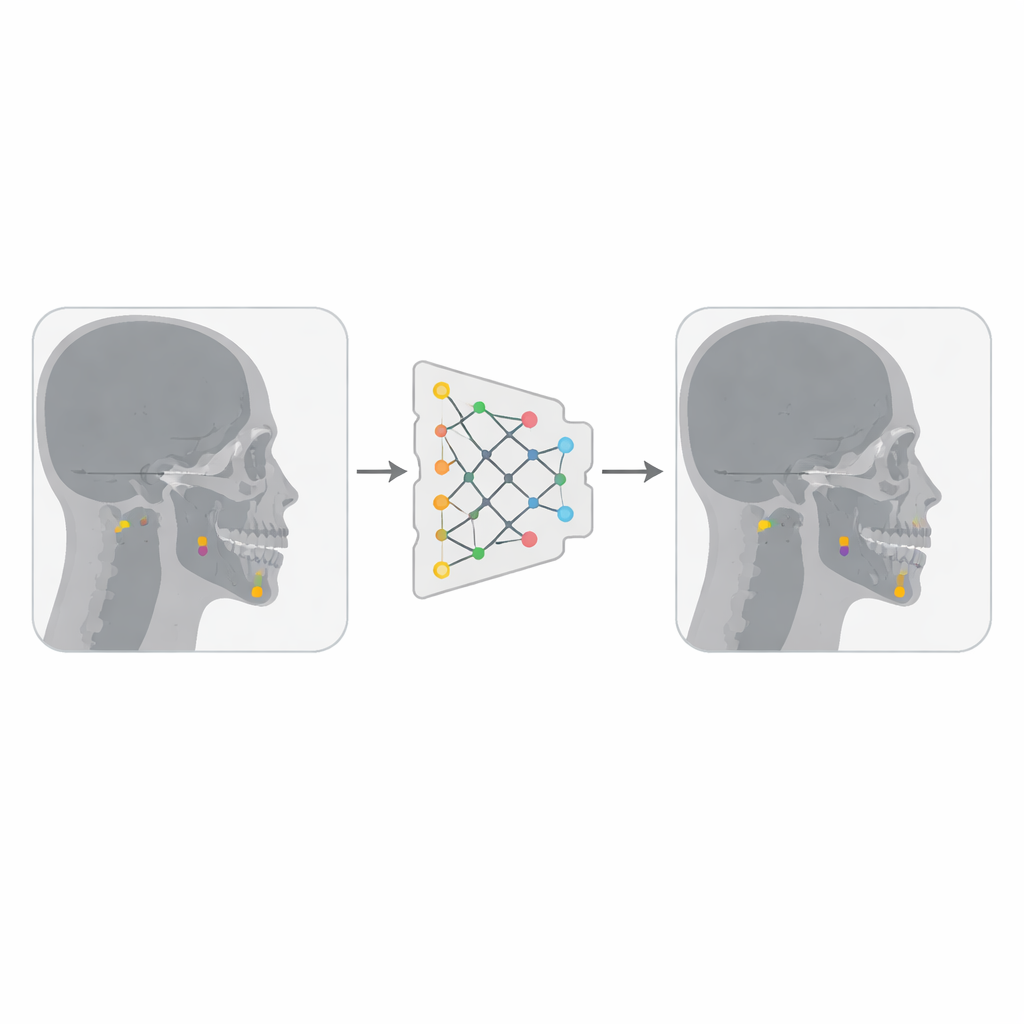
Entwicklung eines schlaueren Landmarkensuchers
Die Autorinnen und Autoren kombinierten zwei öffentlich verfügbare Sammlungen lateraler Schädelröntgenaufnahmen, insgesamt knapp 500 Bilder, die jeweils von erfahrenen Klinikerinnen und Klinikern mit 19 wichtigen cephalometrischen Landmarken annotiert waren. Sie konvertierten die Bilder in ein kompakteres Format und verwandelten jede Landmark-Koordinate in ein kleines quadratisches „Box“-Label, das auf dem Punkt zentriert ist, sodass YOLOv12 — ausgelegt auf die Erkennung von Objekten als Kästen — jede Landmarke als winziges Ziel behandeln konnte. Mithilfe einer Plattform namens Roboflow entfernten sie doppelte Bilder und wandten moderate Transformationen an, etwa leichte Rotationen, Helligkeitsänderungen und Rauschen. Diese Variationen vervielfachten die Zahl der Trainingsbilder effektiv um das Dreifache und halfen dem Modell, robuster gegenüber Unterschieden in Bildqualität und Anatomie der Patienten zu werden.
Wie das Training und die Prüfung der KI abliefen
Die Forschenden trainierten ein großes YOLOv12-Modell auf einer leistungsfähigen Grafikkarte über 50 Trainingsdurchläufe (Epochen). Während des Trainings lernten die internen Schichten des Modells, das rohe Röntgenbild in Merkmale umzuwandeln, die wichtige Bereiche hervorheben, und der Ausgabe-„Kopf“ lernte, um jede Landmarke ein kleines Kästchen zu zeichnen und eine Konfidenz zuzuweisen. Nach Abschluss des Trainings wurde das Modell an 94 Röntgenaufnahmen getestet, die es vorher nicht gesehen hatte. Zur Bewertung wurde gemessen, wie weit jede vorhergesagte Landmarke von der vom Experten markierten Position entfernt war. Außerdem untersuchte das Team Precision–Recall-Kurven, Verwechslungsmuster zwischen verschiedenen Landmarken und detaillierte Diagramme, die die Übereinstimmung für einzelne Punkte zeigten.
Was die KI gut konnte — und wo sie Schwierigkeiten hatte
Insgesamt fand das System etwa die Hälfte aller Landmarken innerhalb von 1 Millimeter zur Expertenmarke und etwas mehr als 80 Prozent innerhalb von 2 Millimetern — ein Bereich, der für viele klinische Aufgaben als akzeptabel gilt. Besonders gut funktionierte die Erkennung von Landmarken mit klarer Form und starkem Kontrast, wie Sella, Gnathion, Menton und bestimmte zahnbezogene Punkte: Mehr als drei Viertel der Vorhersagen lagen hier innerhalb von 1 Millimeter und über 93 Prozent innerhalb von 2 Millimetern. Das Modell zeigte zudem überraschend gute Ergebnisse beim Unterscheiden nahe beieinanderliegender Punktgruppen rund um das Kinn und die Frontzähne, was darauf hindeutet, dass es subtile räumliche Beziehungen gelernt hatte und nicht nur isolierte Pixelmuster. Schwierigkeiten traten jedoch bei Landmarken in unschärferen Regionen auf, etwa Gonion, Subspinale, Orbitale, Articulare und Porion. Diese Bereiche sind selbst für Menschen schwer zu lokalisieren, weil sich Knochen überlagern und der Kontrast gering ist, und eine schlechte Röntgenqualität verschlechterte die Genauigkeit zusätzlich.
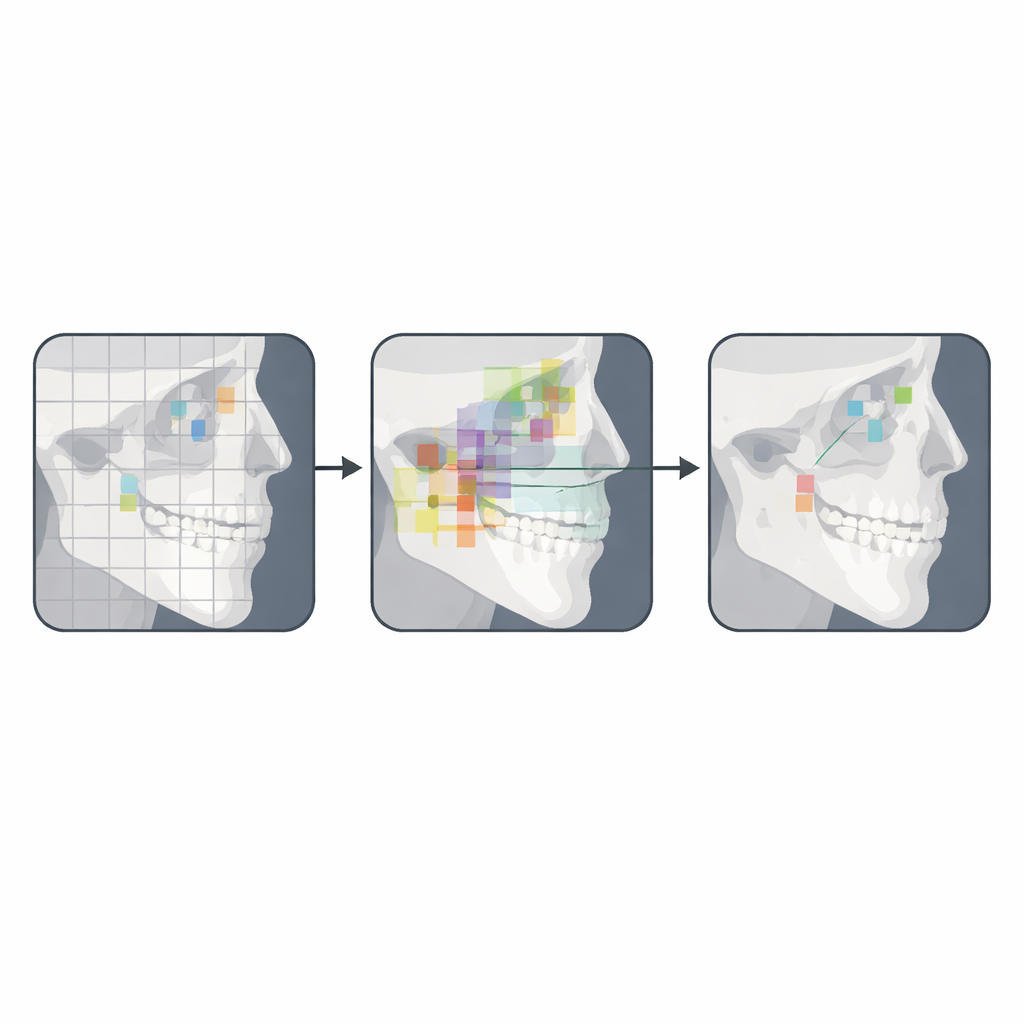
Was das für die zukünftige kieferorthopädische Versorgung bedeutet
Die Autorinnen und Autoren schließen, dass ihr YOLOv12-basiertes System noch nicht bereit ist, menschliche Expertinnen und Experten vollständig zu ersetzen, es jedoch einen überzeugenden Prototyp für halbautomatisierte cephalometrische Analysen darstellt. Praktisch könnte ein solches Werkzeug vorläufige Landmarken sehr schnell platzieren, die dann von Klinikerinnen und Klinikern feinjustiert werden — eine Kombination aus der Geschwindigkeit und Konsistenz der KI und dem fachlichen Urteil. Mit größeren und diverseren Trainingsdatensätzen, besserer Handhabung von Bildmaterial geringer Qualität und fortgesetzter Verfeinerung des Modells könnten künftige Versionen echte klinische Leistungsniveaus erreichen. Wenn das gelingt, werden Kieferorthopädinnen und Kieferorthopäden womöglich bald weniger Zeit mit manueller Nachzeichnung verbringen und mehr Zeit damit, diese Messungen zur Erstellung individueller Behandlungspläne zu nutzen.
Zitation: Akre, P.D., Ghavghave, Y.G. & Pacharaney, U. A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images. Sci Rep 16, 12837 (2026). https://doi.org/10.1038/s41598-026-43250-z
Schlüsselwörter: cephalometrische Analyse, kieferorthopädische Bildgebung, Deep Learning, Landmarkenerkennung, YOLOv12