Clear Sky Science · en
A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images
Why spotting tiny points in skull X-rays matters
When an orthodontist plans braces, jaw surgery, or treatment for facial imbalances, they rely on detailed measurements taken from side-view X-rays of the head. These measurements depend on dozens of tiny anatomical reference points scattered across the skull and face. Today, many of these points are still marked by hand, a slow and somewhat subjective process. This study explores how a modern artificial intelligence (AI) system—an advanced version of the popular YOLO image-detection family—can automatically find these key landmarks on skull X-rays, aiming to make orthodontic care faster, more consistent, and easier to access.
From careful tracing to automated guidance
For nearly a century, “cephalometric analysis” has been the backbone of orthodontic diagnosis. Clinicians look at a standardized side-view X-ray and mark specific points on the skull and soft tissues—on the jaw, teeth, nose, lips, and skull base. From these coordinates they calculate angles and distances that guide treatment decisions. Doing this by hand can take 10–15 minutes per X-ray and even experienced experts may disagree by a couple of millimeters, which can affect delicate treatment plans. As dental practices see more patients and aim for ever finer precision, there is growing pressure to speed up this work and reduce human variation without losing expert oversight.
How modern AI sees an X-ray
Recent progress in AI, especially deep learning, has transformed how computers interpret images. Instead of being programmed with hand-crafted rules, deep neural networks learn directly from large collections of labeled examples. In medical imaging, a class of models called convolutional neural networks has become particularly successful, because it can automatically discover patterns ranging from simple edges to complex anatomical shapes. Within this landscape, the “You Only Look Once” or YOLO family stands out for spotting objects extremely quickly and in a single pass over the image. The newest generation, YOLOv12, incorporates attention mechanisms and multi-scale processing that are especially helpful for finding small, closely packed structures like cephalometric landmarks.
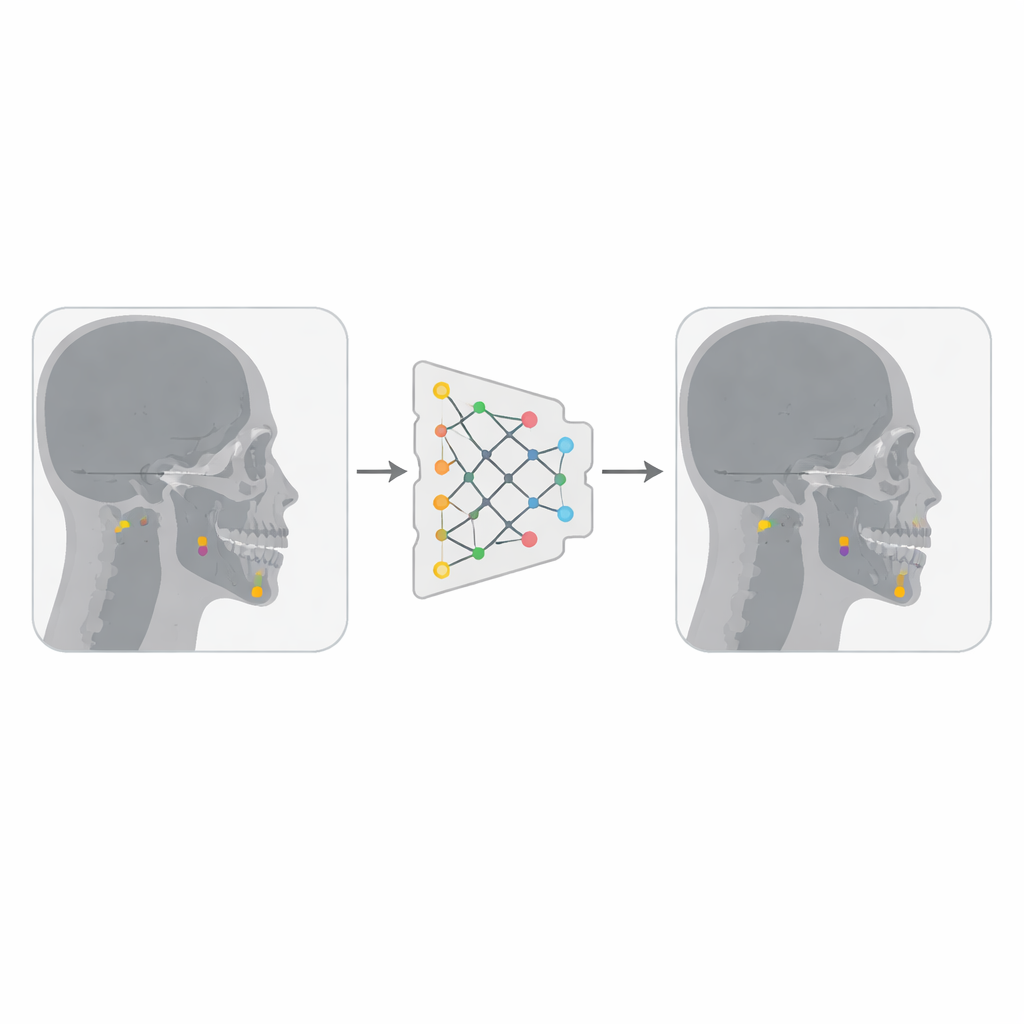
Building a smarter landmark hunter
The authors combined two publicly available collections of lateral skull X-rays, together totaling just under 500 images, each annotated with 19 important cephalometric landmarks by experienced clinicians. They converted the images into a more compact format and turned each landmark coordinate into a small square “box” centered on the point, so that YOLOv12—designed to detect objects as boxes—could treat each landmark as a tiny target. Using a platform called Roboflow, they removed duplicate images and applied modest transformations such as slight rotations, brightness changes, and noise. These variations effectively tripled the number of training images, helping the model become more robust to differences in image quality and patient anatomy.
Inside the AI’s training and testing
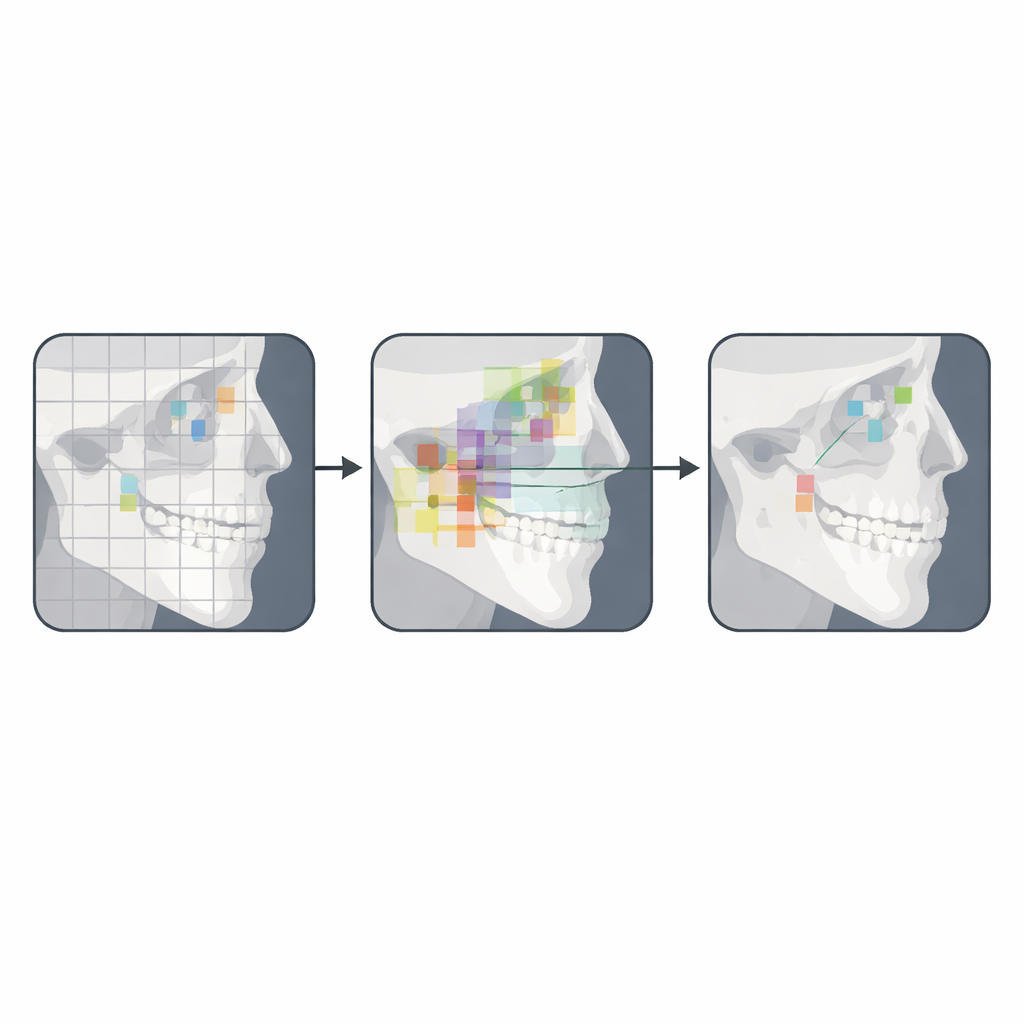
The researchers trained a large YOLOv12 model on a powerful graphics processor for 50 training rounds, or epochs. During training, the model’s internal layers learned to convert the raw X-ray into a set of features that highlight important areas, and its output “head” learned to draw a small box around each landmark and assign it a confidence score. Once training finished, the model was tested on 94 X-rays it had never seen before. To judge performance, the team measured how far each predicted landmark sat from its expert-marked counterpart. They also examined precision–recall curves, confusion patterns between different landmarks, and detailed plots showing agreement for specific points.
What the AI got right—and where it struggled
Overall, the system found about half of all landmarks within 1 millimeter of the expert marks, and just over 80 percent within 2 millimeters—a range considered acceptable for many clinical tasks. It excelled at landmarks with clear shapes and strong contrast, such as Sella, Gnathion, Menton, and certain tooth-related points, where more than three-quarters of predictions were within 1 millimeter and over 93 percent within 2 millimeters. The model also did surprisingly well at distinguishing clusters of nearby points around the chin and front teeth, suggesting it had learned subtle spatial relationships, not just isolated pixels. However, it struggled with landmarks in fuzzier regions, like Gonion, Subspinale, Orbitale, Articulare, and Porion. These areas are harder even for humans because overlapping bones and low contrast make the boundaries unclear, and poor X-ray quality further degraded accuracy.
What this means for future orthodontic care
The authors conclude that their YOLOv12-based system is not yet ready to replace human experts, but it is a strong proof of concept for semi-automated cephalometric analysis. In practical terms, such a tool could rapidly place preliminary landmarks that clinicians then fine-tune, blending the speed and consistency of AI with professional judgment. With larger and more diverse training datasets, better handling of low-quality images, and continued refinement of the model, future versions could approach true clinical-grade performance. If that happens, orthodontists may soon spend less time manually tracing X-rays and more time using those measurements to craft personalized treatment plans.
Citation: Akre, P.D., Ghavghave, Y.G. & Pacharaney, U. A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images. Sci Rep 16, 12837 (2026). https://doi.org/10.1038/s41598-026-43250-z
Keywords: cephalometric analysis, orthodontic imaging, deep learning, landmark detection, YOLOv12