Clear Sky Science · pl
Metoda oparta na YOLOv12 do automatycznego wykrywania punktów cefalometrycznych na dwuwymiarowych bocznych zdjęciach rentgenowskich czaszki
Dlaczego wykrywanie drobnych punktów na zdjęciach rentgenowskich czaszki ma znaczenie
Kiedy ortodonta planuje aparat, operację szczęki lub leczenie asymetrii twarzy, opiera się na precyzyjnych pomiarach wykonanych na bocznych zdjęciach rentgenowskich głowy. Pomiary te zależą od kilkudziesięciu drobnych anatomicznych punktów odniesienia rozmieszczonych na czaszce i twarzy. Wciąż wiele z tych punktów jest oznaczanych ręcznie — to proces czasochłonny i częściowo subiektywny. Niniejsze badanie analizuje, jak nowoczesny system sztucznej inteligencji (SI) — zaawansowana wersja popularnej rodziny detektorów obrazów YOLO — może automatycznie odnajdywać te kluczowe punkty na zdjęciach rentgenowskich czaszki, z zamiarem usprawnienia opieki ortodontycznej, zwiększenia jej spójności i dostępności.
Od ręcznego trasowania do automatycznego wsparcia
Przez niemal sto lat „analiza cefalometryczna” stanowiła podstawę diagnostyki ortodontycznej. Klinicyści oglądają standaryzowane boczne zdjęcie rentgenowskie i zaznaczają określone punkty na kościach i tkankach miękkich — na żuchwie, zębach, nosie, wargach i podstawie czaszki. Z tych współrzędnych obliczane są kąty i odległości, które kierują decyzjami terapeutycznymi. Oznaczanie ręczne może zajmować 10–15 minut na zdjęcie, a nawet doświadczeni eksperci mogą różnić się o kilka milimetrów, co wpływa na precyzyjne plany leczenia. W miarę jak gabinety dentystyczne obsługują więcej pacjentów i dążą do coraz większej dokładności, rośnie presja, by przyspieszyć te czynności i zmniejszyć zmienność ludzką, nie rezygnując z nadzoru eksperckiego.
Jak nowoczesna SI „widzi” zdjęcie rentgenowskie
Ostatnie postępy w SI, zwłaszcza w uczeniu głębokim, zmieniły sposób, w jaki komputery interpretują obrazy. Zamiast polegać na ręcznie zaprogramowanych regułach, głębokie sieci neuronowe uczą się bezpośrednio z dużych zbiorów oznaczonych przykładów. W obrazowaniu medycznym szczególnie udane okazały się modele z rodziny sieci konwolucyjnych, ponieważ potrafią automatycznie odkrywać wzorce od prostych krawędzi po złożone kształty anatomiczne. W tym kontekście rodzina „You Only Look Once” (YOLO) wyróżnia się zdolnością do bardzo szybkiego wykrywania obiektów w pojedynczym przejściu po obrazie. Najnowsza generacja, YOLOv12, wprowadza mechanizmy uwagi i przetwarzanie wieloskalowe, które są szczególnie przydatne przy wykrywaniu małych, blisko położonych struktur, takich jak punkty cefalometryczne.
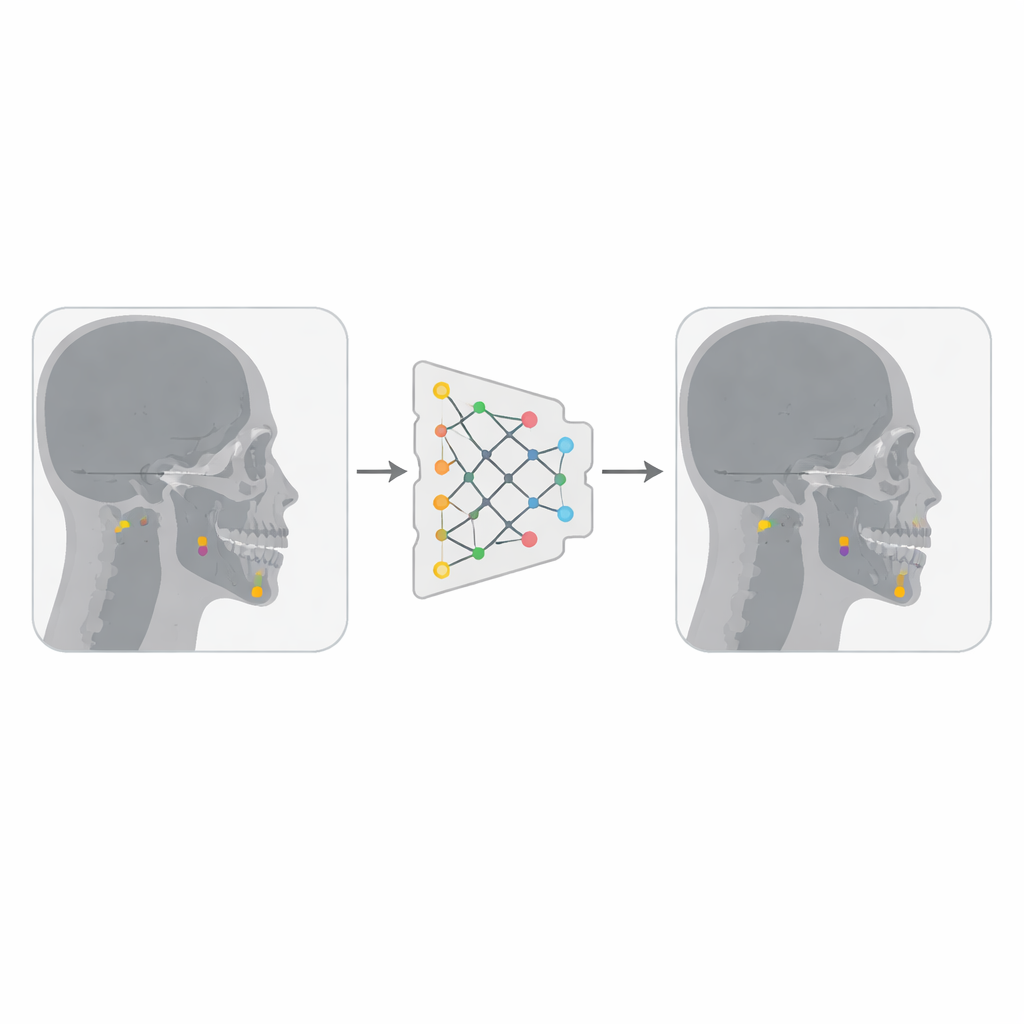
Budowanie bardziej zaawansowanego detektora punktów
Autorzy połączyli dwie publicznie dostępne kolekcje bocznych zdjęć rentgenowskich czaszki, łącznie nieco poniżej 500 obrazów, z których każdy został oznaczony przez doświadczonych klinicystów za pomocą 19 istotnych punktów cefalometrycznych. Przekonwertowali obrazy do bardziej kompaktowego formatu i zamienili współrzędne punktów w małe kwadratowe „pudełka” centrowane na tych punktach, tak aby YOLOv12 — zaprojektowany do wykrywania obiektów jako prostokątów — mógł traktować każdy punkt jako niewielki cel. Przy użyciu platformy Roboflow usunęli duplikaty i zastosowali umiarkowane transformacje, takie jak drobne rotacje, zmiany jasności i szum. Te wariacje skutecznie potroiły liczbę obrazów treningowych, pomagając modelowi stać się bardziej odpornym na różnice w jakości obrazów i anatomii pacjentów.
Wnętrze treningu i testów SI
Naukowcy trenowali duży model YOLOv12 na wydajnym procesorze graficznym przez 50 rund treningowych, czyli epok. Podczas treningu wewnętrzne warstwy modelu uczyły się przekształcać surowe zdjęcie rentgenowskie w zbiór cech uwypuklających istotne obszary, a moduł wyjściowy nauczył się rysować małe pudełko wokół każdego punktu i przypisywać mu ocenę pewności. Po zakończeniu treningu model przetestowano na 94 zdjęciach, których wcześniej nie widział. Aby ocenić wydajność, zespół mierzył odległość między przewidywanym punktem a odpowiadającym mu punktem oznaczonym przez eksperta. Analizowano też krzywe precyzji–czułości, wzorce pomyłek między różnymi punktami oraz szczegółowe wykresy pokazujące zgodność dla poszczególnych punktów.
Co SI zrobiła dobrze — i z czym miała trudności
W sumie system znalazł około połowy wszystkich punktów w odległości 1 milimetra od oznaczeń ekspertów i nieco ponad 80 procent w granicy 2 milimetrów — zakres uznawany za akceptowalny dla wielu zadań klinicznych. Najlepiej radził sobie z punktami o wyraźnych kształtach i silnym kontraście, takimi jak Sella, Gnathion, Menton oraz niektóre punkty związane z zębami, gdzie ponad trzy czwarte przewidywań mieściło się w 1 milimetrze, a ponad 93 procent w 2 milimetrach. Model zaskakująco dobrze radził sobie także z rozróżnianiem skupisk blisko położonych punktów wokół podbródka i przednich zębów, co sugeruje, że nauczył się subtelnych relacji przestrzennych, a nie tylko pojedynczych pikseli. Natomiast miał trudności z punktami w mniej wyraźnych obszarach, takimi jak Gonion, Subspinale, Orbitale, Articulare i Porion. Te rejony są trudniejsze nawet dla ludzi, ponieważ nakładające się kości i niski kontrast powodują niejasne granice, a niska jakość zdjęć dodatkowo pogarsza dokładność.
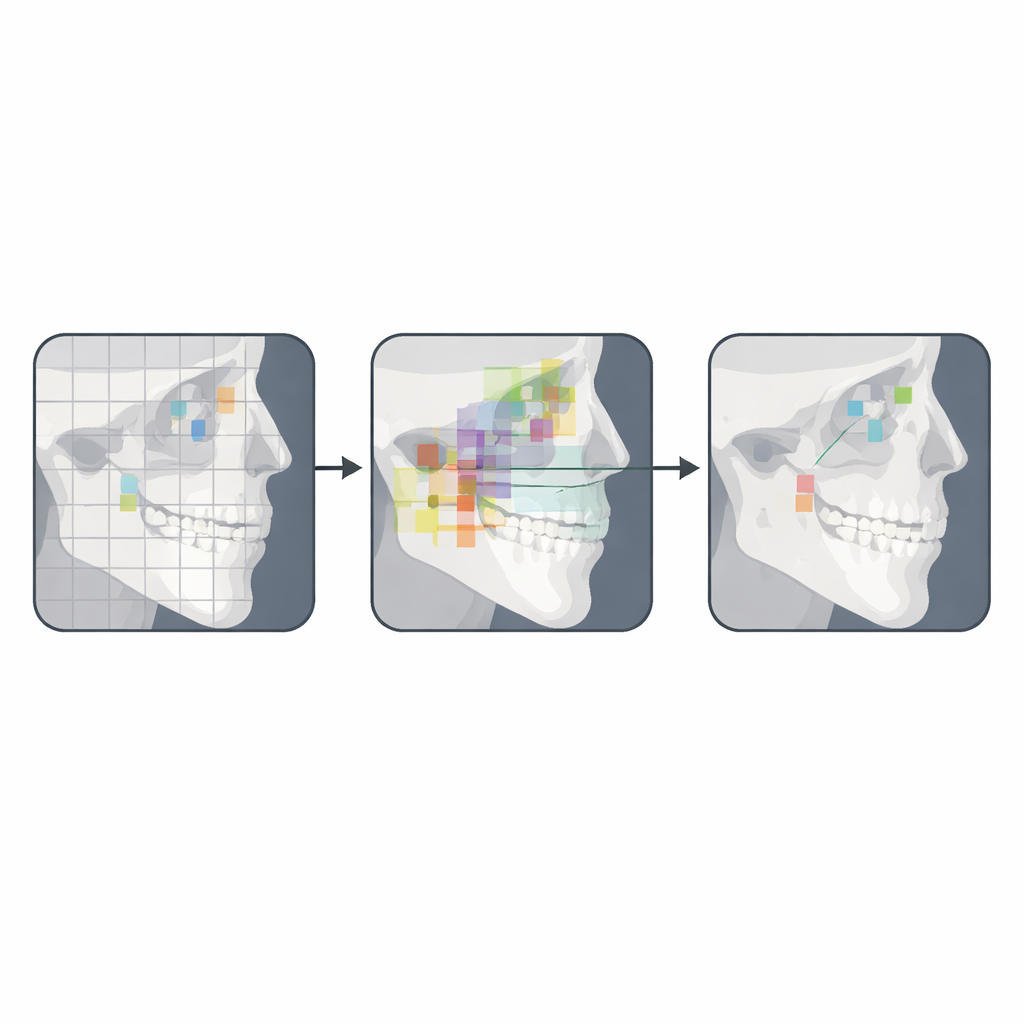
Co to oznacza dla przyszłej opieki ortodontycznej
Autorzy wnioskują, że ich system oparty na YOLOv12 jeszcze nie zastąpi ekspertów, ale stanowi silny dowód koncepcji dla półautomatycznej analizy cefalometrycznej. W praktyce takie narzędzie mogłoby szybko umieszczać wstępne punkty, które klinicyści następnie poprawiają, łącząc szybkość i spójność SI z profesjonalnym osądem. Przy większych i bardziej zróżnicowanych zbiorach treningowych, lepszym radzeniu sobie z obrazami niskiej jakości i dalszym doskonaleniu modelu przyszłe wersje mogłyby zbliżyć się do wydajności na poziomie klinicznym. Jeśli tak się stanie, ortodonci wkrótce mogą spędzać mniej czasu na ręcznym trasowaniu zdjęć rentgenowskich, a więcej na wykorzystywaniu tych pomiarów do tworzenia spersonalizowanych planów leczenia.
Cytowanie: Akre, P.D., Ghavghave, Y.G. & Pacharaney, U. A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images. Sci Rep 16, 12837 (2026). https://doi.org/10.1038/s41598-026-43250-z
Słowa kluczowe: analiza cefalometryczna, obrazowanie ortodontyczne, uczenie głębokie, wykrywanie punktów orientacyjnych, YOLOv12