Clear Sky Science · es
Un enfoque basado en YOLOv12 para la detección automática de puntos cefalométricos en radiografías laterales 2D del cráneo
Por qué importa localizar puntos diminutos en las radiografías del cráneo
Cuando un ortodoncista planifica frenillos, cirugía maxilofacial o el tratamiento de asimetrías faciales, se basa en mediciones detalladas extraídas de radiografías laterales del cráneo. Esas mediciones dependen de docenas de pequeños puntos de referencia anatómicos distribuidos por el cráneo y el rostro. Hoy en día, muchos de esos puntos todavía se señalan manualmente, un proceso lento y en cierta medida subjetivo. Este estudio explora cómo un sistema moderno de inteligencia artificial (IA), una versión avanzada de la conocida familia de detección de imágenes YOLO, puede localizar automáticamente esos puntos clave en radiografías del cráneo, con el objetivo de hacer la atención ortodóntica más rápida, más consistente y más accesible.
De la trazación manual a la guía automatizada
Durante casi un siglo, el “análisis cefalométrico” ha sido la base del diagnóstico ortodóntico. Los clínicos observan una radiografía lateral estandarizada y marcan puntos específicos en el cráneo y en los tejidos blandos: en la mandíbula, los dientes, la nariz, los labios y la base del cráneo. A partir de estas coordenadas calculan ángulos y distancias que orientan las decisiones de tratamiento. Hacer esto a mano puede llevar entre 10 y 15 minutos por radiografía y, aun con expertos experimentados, puede haber discrepancias de un par de milímetros, lo que puede influir en planes de tratamiento delicados. A medida que las clínicas dentales atienden a más pacientes y buscan mayor precisión, crece la necesidad de acelerar este trabajo y reducir la variabilidad humana sin perder la supervisión profesional.
Cómo ve la IA moderna una radiografía
Los avances recientes en IA, y en particular en aprendizaje profundo, han transformado la forma en que los ordenadores interpretan imágenes. En lugar de programarse con reglas hechas a mano, las redes neuronales profundas aprenden directamente de grandes colecciones de ejemplos etiquetados. En imagen médica, una clase de modelos llamados redes neuronales convolucionales ha tenido especial éxito, porque pueden descubrir automáticamente patrones que van desde bordes simples hasta formas anatómicas complejas. Dentro de este panorama, la familia “You Only Look Once” o YOLO destaca por detectar objetos muy rápidamente y en una sola pasada sobre la imagen. La generación más reciente, YOLOv12, incorpora mecanismos de atención y procesamiento multiescala que son especialmente útiles para encontrar estructuras pequeñas y densamente agrupadas como los puntos cefalométricos.
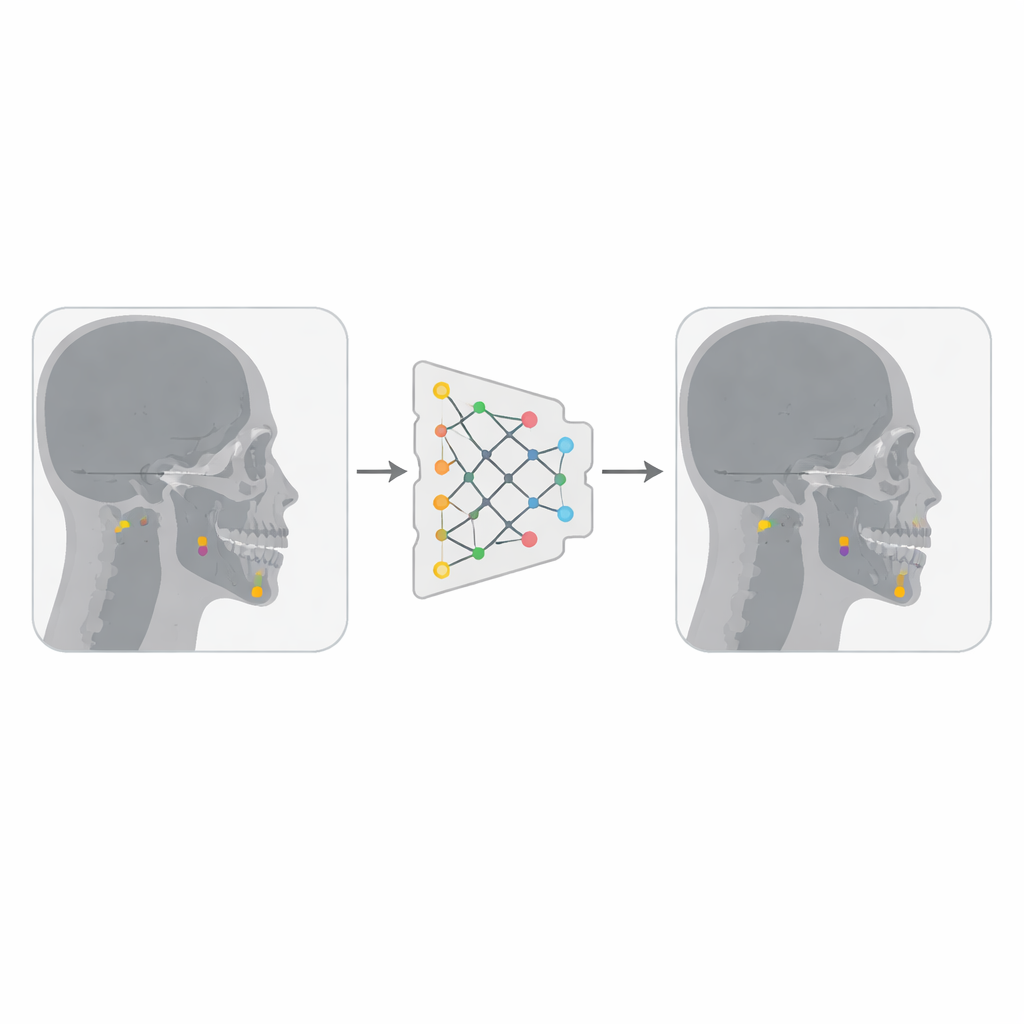
Construyendo un detector de puntos más inteligente
Los autores combinaron dos colecciones públicas de radiografías laterales del cráneo, que suman en conjunto algo menos de 500 imágenes, cada una anotada con 19 puntos cefalométricos importantes por clínicos experimentados. Convirtieron las imágenes a un formato más compacto y transformaron cada coordenada de punto en una pequeña “caja” cuadrada centrada en el punto, de modo que YOLOv12 —diseñado para detectar objetos como cajas— pudiera tratar cada punto como un objetivo diminuto. Usando una plataforma llamada Roboflow, eliminaron imágenes duplicadas y aplicaron transformaciones moderadas como pequeñas rotaciones, cambios de brillo y ruido. Estas variaciones triplicaron efectivamente el número de imágenes de entrenamiento, ayudando al modelo a ser más robusto frente a diferencias en la calidad de imagen y en la anatomía de los pacientes.
Dentro del entrenamiento y la evaluación de la IA
Los investigadores entrenaron un gran modelo YOLOv12 en una potente unidad de procesamiento gráfico durante 50 ciclos de entrenamiento u épocas. Durante el entrenamiento, las capas internas del modelo aprendieron a convertir la radiografía cruda en un conjunto de características que resaltan las áreas importantes, y la “cabeza” de salida aprendió a dibujar una pequeña caja alrededor de cada punto y asignarle una puntuación de confianza. Terminada la fase de entrenamiento, el modelo se evaluó en 94 radiografías que no había visto antes. Para juzgar el rendimiento, el equipo midió la distancia entre cada punto predicho y su equivalente marcado por el experto. También examinaron curvas de precisión–recuperación, patrones de confusión entre distintos puntos y gráficos detallados que muestran el grado de acuerdo para puntos específicos.
Qué acertó la IA — y dónde tuvo dificultades
En general, el sistema encontró alrededor de la mitad de los puntos dentro de 1 milímetro de las marcas de los expertos, y algo más del 80 por ciento dentro de 2 milímetros —un rango considerado aceptable para muchas tareas clínicas. Se comportó especialmente bien en puntos con formas claras y alto contraste, como Sella, Gnathion, Menton y ciertos puntos relacionados con dientes, donde más de tres cuartas partes de las predicciones estaban dentro de 1 milímetro y más del 93 por ciento dentro de 2 milímetros. El modelo también distinguió sorprendentemente bien agrupaciones de puntos cercanos alrededor del mentón y de los dientes frontales, lo que sugiere que aprendió relaciones espaciales sutiles, no solo patrones de píxeles aislados. Sin embargo, tuvo dificultades con puntos en regiones menos definidas, como Gonion, Subspinale, Orbitale, Articulare y Porion. Estas áreas son complicadas incluso para los humanos porque la superposición ósea y el bajo contraste hacen que los límites sean imprecisos, y la mala calidad de algunas radiografías degradó aún más la exactitud.
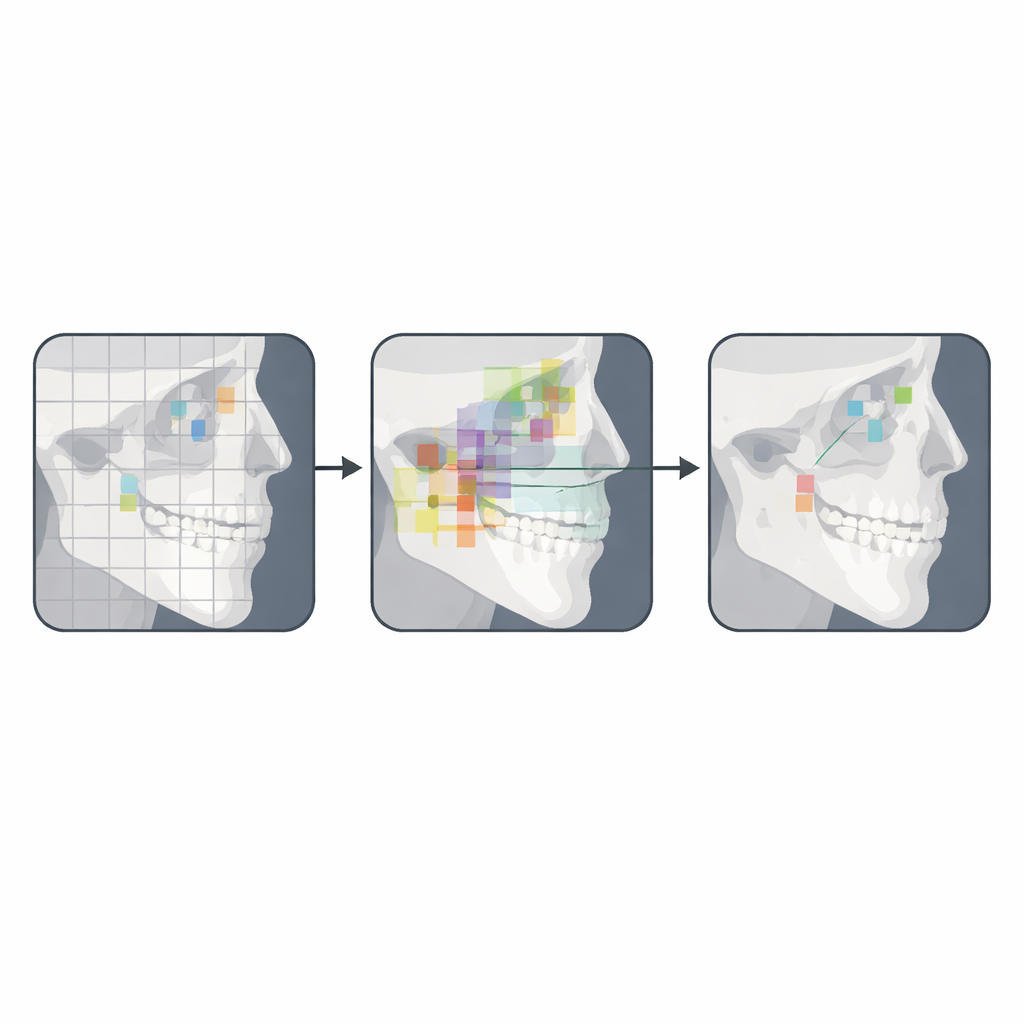
Qué implica esto para la atención ortodóntica futura
Los autores concluyen que su sistema basado en YOLOv12 aún no está listo para reemplazar a los expertos humanos, pero constituye una prueba de concepto sólida para un análisis cefalométrico semiautomatizado. En la práctica, una herramienta así podría colocar rápidamente puntos preliminares que los clínicos afinarían después, combinando la rapidez y consistencia de la IA con el juicio profesional. Con conjuntos de datos de entrenamiento más amplios y diversos, mejor tratamiento de imágenes de baja calidad y una continua refinación del modelo, versiones futuras podrían acercarse al rendimiento de grado clínico. Si eso ocurre, los ortodoncistas podrían dedicar menos tiempo a trazar radiografías manualmente y más tiempo a usar esas mediciones para diseñar planes de tratamiento personalizados.
Cita: Akre, P.D., Ghavghave, Y.G. & Pacharaney, U. A YOLOv12-based approach for automatic detection of cephalometric landmarks on 2D lateral skull X-ray images. Sci Rep 16, 12837 (2026). https://doi.org/10.1038/s41598-026-43250-z
Palabras clave: análisis cefalométrico, imagenología ortodóntica, aprendizaje profundo, detección de puntos de referencia, YOLOv12