Clear Sky Science · ru
Использование гибридного стекинг-ансамбля для точной диагностики тромбоэмболии лёгочной артерии на основе табличных клинических данных
Почему это важно для ухода за пациентами
Тромбоэмболия лёгочной артерии — это тромб в лёгких, который при пропуске диагноза может привести к смерти за считанные минуты. Врачи в значительной степени полагаются на сложные сканирования и собственную клиническую оценку, чтобы выявить её вовремя. В этом исследовании рассматривается, как интеллектуальные компьютерные системы могут использовать рутинные клинические данные, а не только изображения, чтобы помогать отмечать пациентов с возможным скрытым тромбом, поддерживая более быстрые и надёжные решения в загруженных больницах.
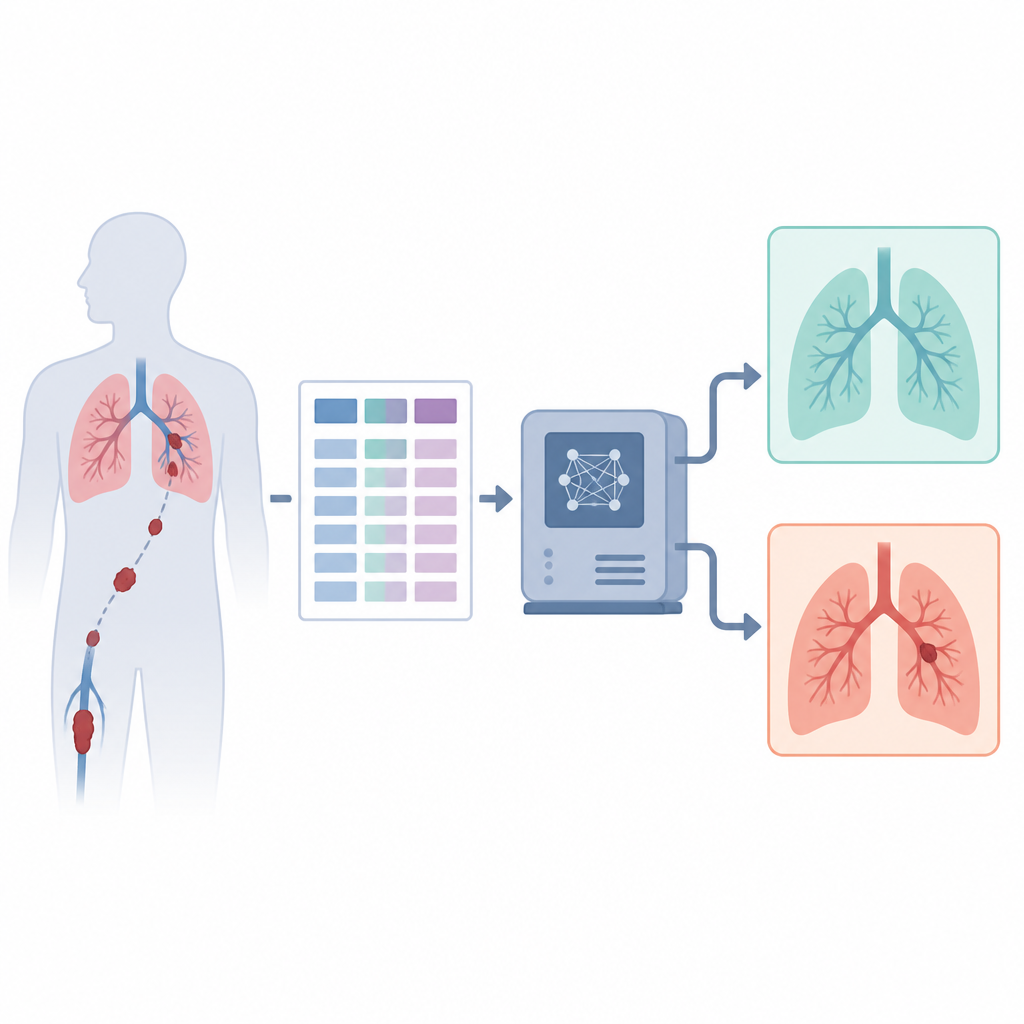
Опасность скрытых тромбов в лёгких
Тромбоэмболия лёгочной артерии — одно из наиболее частых угрожающих жизни сердечно‑лёгочных состояний после инфарктов и инсультов. Тромбы, попадая в лёгкие, могут резко блокировать кровоток, перегружать правую часть сердца и лишать организм кислорода. Многие пациенты погибают до того, как станет ясно, что происходит. Однако при своевременном распознавании и лечении вероятность выживания существенно возрастает. Этот разрыв между «молчащим» риском и спасительными действиями стимулирует поиск инструментов, которые могут раньше указать врачам на правильный диагноз.
Ограничения нынешних тестов и шкал
Сегодня основным тестом для выявления тромбоэмболии лёгочной артерии служит специальный КТ‑скан грудной клетки. Несмотря на свою эффективность, такие сканы требуют дорогостоящего оборудования, экспертного чтения и времени. Стандартные клинические шкалы и отдельные модели машинного обучения, использующие базовые данные пациента, помогли частично, но часто пропускают тонкие закономерности в больших смешанных клинических наборах. По мере того как больницы накапливают больше цифровых записей, растёт потребность в более умных системах, которые могут одновременно извлекать информацию из разных клинических признаков и при этом оставаться надёжными и понятными для врачей.
Команда моделей, работающая совместно
Авторы решают эту задачу, используя только структурированную клиническую информацию из большого публичного набора данных КТ, не просматривая сами изображения. Они создают гибридный стекинг‑ансамбль, который лучше всего представить как комиссию из разных компьютерных моделей, совместно голосующих за наличие тромба у пациента. В состав комиссии входят две модели на основе деревьев решений, классическая нейронная сеть и современная трансформер‑модель, адаптированная для табличных данных. Каждая модель выдаёт вероятность наличия тромба, а простая итоговая модель обучается комбинировать эти мнения в одно решение так, чтобы избежать переобучения и сохранить стабильность поведения.
Пусть природа подскажет настройки
Чтобы извлечь максимум из этой комиссии, исследователи применяют метод поиска, вдохновлённый природой, под названием алгоритм морских хищников. Этот метод исследует множество комбинаций внутренних настроек каждой модели и способов взвешивания их выводов, подобно виртуальным охотникам, ищущим лучшие рыболовные места в большом океане. С применением кросс‑валидации для защиты от случайных находок, алгоритм находит конфигурацию, которая улучшает способность всей системы разделять пациентов с тромбами и без них по сравнению с каждой отдельной моделью или простыми схемами голосования.
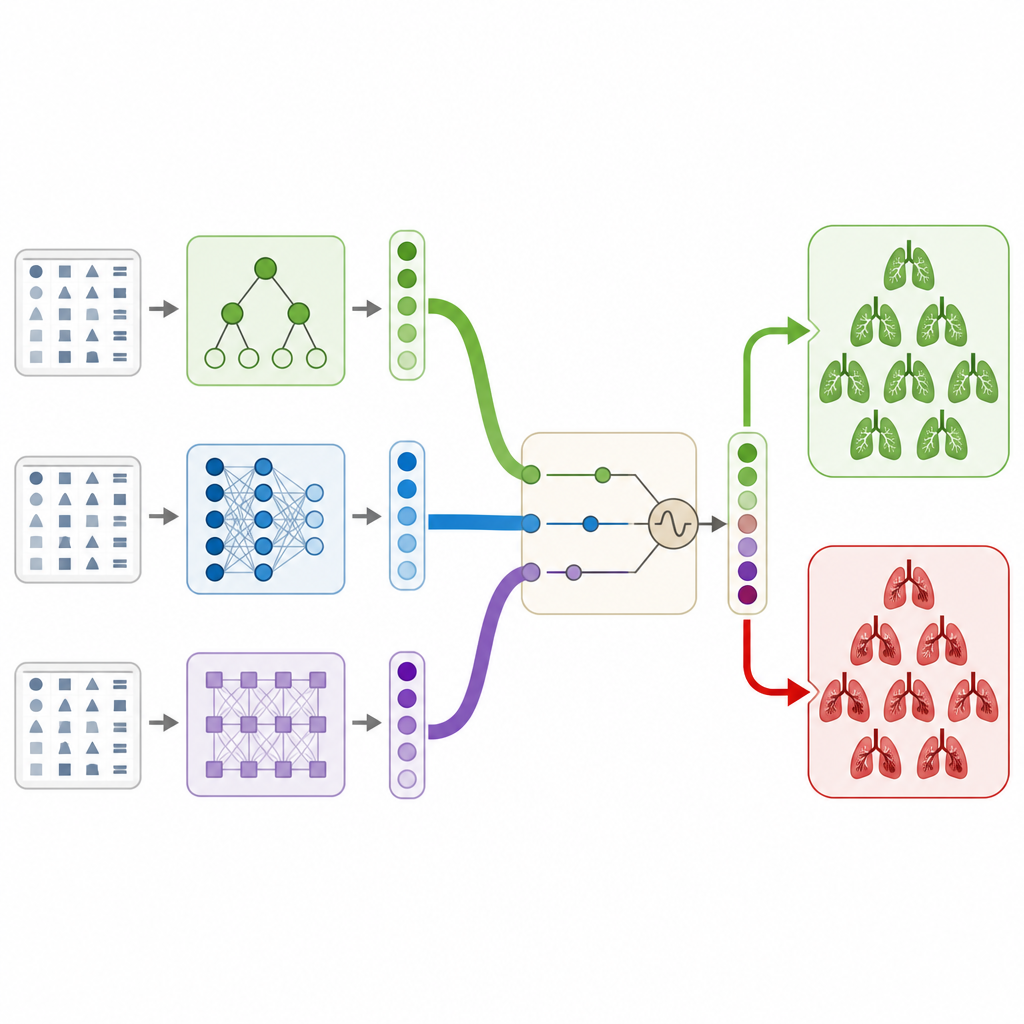
Как работает система и чему она учится
На публичном наборе данных RSNA по тромбоэмболии лёгочной артерии объединённая система достигает примерно 92 процентов общей точности и высокой способности отличать положительные и отрицательные случаи. Это превосходит все отдельные модели и несколько стандартных способов их комбинирования. Авторы также применяют инструменты объяснимости, чтобы понять, какие клинические поля наиболее влияют на предсказания. Признаки, непосредственно описывающие наличие и локализацию тромба, а также показатели нагрузки на правую часть сердца, оказывают наибольшее влияние, тогда как технические флаги качества изображения мало влияют. Эта картина согласуется с медицинскими знаниями, что указывает на то, что модель фокусируется на клинически значимых сигналах, а не на шуме.
Что это значит для будущей диагностики
Проще говоря, работа показывает, что тщательно настроенная команда разнообразных компьютерных моделей может использовать обычные клинические данные, чтобы помогать выявлять тромбы в лёгких точнее, чем одиночные методы. Хотя систему ещё нужно тестировать вне использованного набора данных и она не заменяет сканирование или врачей, она предлагает практический путь к инструментам поддержки, которые раньше выделяют пациентов высокого риска, снижают число пропущенных диагнозов и лучше используют имеющиеся в больницах данные в реальных условиях.
Цитирование: Abdelhamid, A., Moustafa, H.ED., Nafea, H.B. et al. Harnessing hybrid stacking ensemble learning for accurate pulmonary embolism diagnosis using tabular clinical data. Sci Rep 16, 15051 (2026). https://doi.org/10.1038/s41598-026-49331-3
Ключевые слова: тромбоэмболия лёгочной артерии, клинические данные, ансамблевое обучение, машинное обучение, медицинская диагностика