Clear Sky Science · es
Aprovechamiento del aprendizaje en ensamblaje híbrido por apilamiento para un diagnóstico preciso de embolia pulmonar usando datos clínicos tabulares
Por qué esto importa para la atención al paciente
La embolia pulmonar es un coágulo de sangre en los pulmones que puede ser mortal en cuestión de minutos si pasa desapercibido. Los médicos dependen en gran medida de exploraciones complejas y de su propio juicio para detectarla a tiempo. Este estudio explora cómo los sistemas informáticos inteligentes pueden usar información clínica de rutina, en lugar de solo imágenes, para ayudar a identificar a los pacientes que podrían tener un coágulo oculto, apoyando decisiones más rápidas y fiables en hospitales congestionados.
El peligro de los coágulos pulmonares ocultos
La embolia pulmonar es una de las emergencias cardiopulmonares potencialmente mortales más comunes, tras los infartos y los accidentes cerebrovasculares. Los coágulos que viajan a los pulmones pueden bloquear de forma repentina el flujo sanguíneo, sobrecargar el lado derecho del corazón y privar al cuerpo de oxígeno. Muchos pacientes fallecen antes de que se detecte lo que está ocurriendo. Sin embargo, cuando la afección se reconoce con rapidez y se trata, la probabilidad de supervivencia mejora de forma drástica. Esta brecha entre el riesgo silencioso y la acción que salva vidas motiva la búsqueda de herramientas que puedan orientar a los médicos hacia el diagnóstico correcto con mayor rapidez.
Límites de las pruebas y puntuaciones actuales
Hoy en día, la prueba principal para la embolia pulmonar es un tipo especial de tomografía computarizada (TC) del tórax. Aunque potentes, estos escáneres requieren equipos caros, lectores expertos y tiempo. Los sistemas de puntuación clínica estándar y los modelos individuales de aprendizaje automático que usan datos básicos del paciente han ayudado en cierta medida, pero a menudo pasan por alto patrones sutiles en conjuntos de datos clínicos grandes y heterogéneos. A medida que los hospitales recopilan más registros digitales, existe una necesidad creciente de sistemas más inteligentes que puedan aprender de múltiples tipos de indicios clínicos a la vez y, al mismo tiempo, seguir siendo fiables y comprensibles para los clínicos.
Un equipo de modelos que trabajan juntos
Los autores abordan esta necesidad usando únicamente la información clínica estructurada que acompaña a un gran conjunto de datos público de TC, sin analizar las imágenes. Construyen un ensamblaje híbrido por apilamiento, que puede entenderse mejor como un comité de distintos modelos informáticos que votan conjuntamente sobre si un paciente tiene un coágulo. El comité incluye dos modelos basados en árboles, una red neuronal clásica y un modelo transformer moderno diseñado para datos tipo tabla. Cada modelo produce una probabilidad de que haya un coágulo, y un modelo final sencillo aprende a combinar estas opiniones en una decisión de forma que evita el sobreajuste y mantiene el comportamiento estable.
Dejar que la naturaleza guíe la optimización
Para extraer el máximo rendimiento de este comité, los investigadores usan un método de búsqueda inspirado en la naturaleza llamado algoritmo de depredadores marinos. Este método explora muchas combinaciones de parámetros internos para cada modelo y múltiples maneras de ponderar sus salidas, de forma similar a cazadores virtuales que exploran un gran océano en busca de las mejores zonas de pesca. Usando validación cruzada para protegerse contra hallazgos por casualidad, el algoritmo se decanta por una configuración que mejora la capacidad del sistema completo para separar a los pacientes con y sin coágulos, en comparación con cada modelo individual o con esquemas de votación más simples.
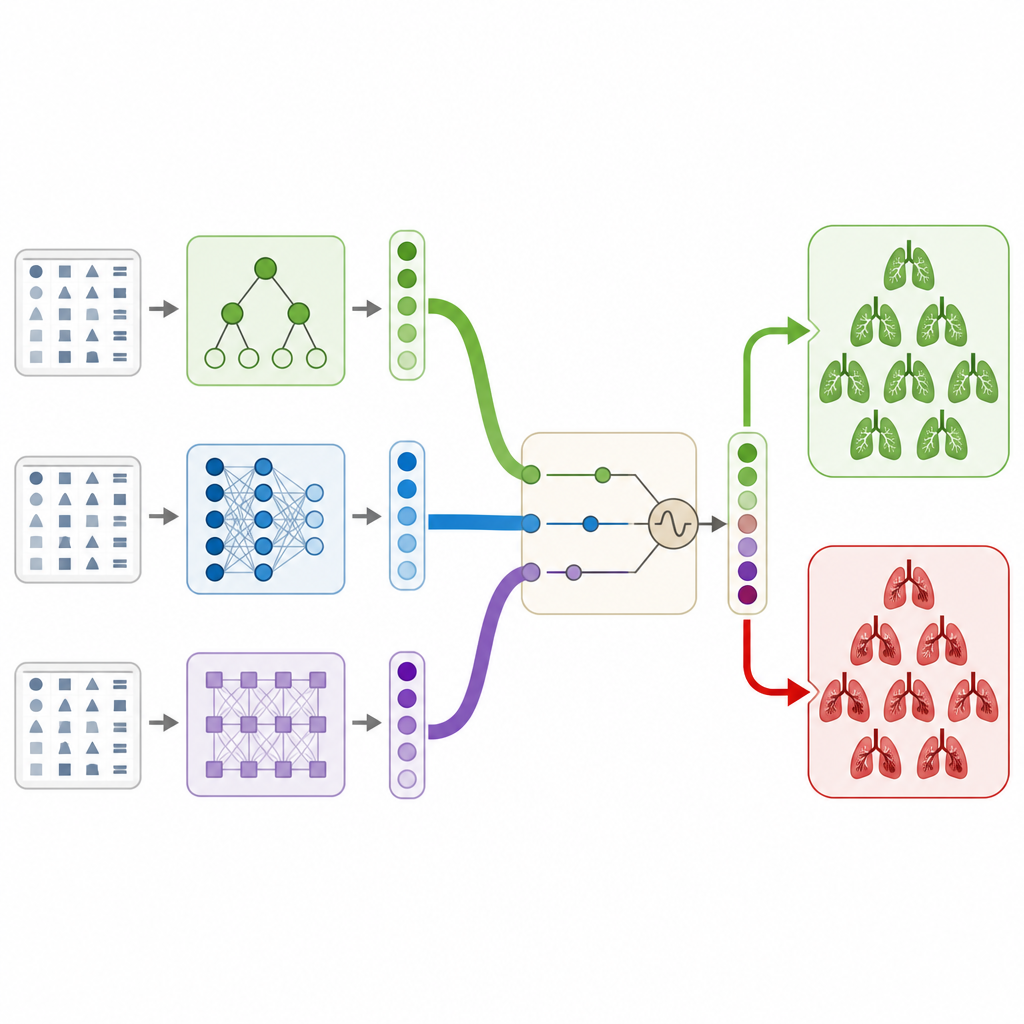
Qué tan bien funciona el sistema y qué aprende
En el conjunto de datos público de embolia pulmonar de la RSNA, el sistema combinado alcanza aproximadamente un 92 por ciento de precisión global y una fuerte medida de discriminación entre casos positivos y negativos. Esto supera a todos los modelos individuales y a varias formas estándar de combinarlos. A continuación, los autores usan herramientas de explicación para ver qué campos clínicos influyen más en las predicciones. Las características que describen directamente la presencia y el lado del coágulo, junto con medidas de sobrecarga del lado derecho del corazón, tienen el mayor impacto, mientras que las señales técnicas de calidad de imagen tienen poco efecto. Este patrón concuerda con el conocimiento médico, lo que sugiere que el modelo se centra en señales clínicamente significativas en lugar de ruido.
Qué significa esto para el diagnóstico futuro
En términos sencillos, este trabajo muestra que un equipo cuidadosamente ajustado de modelos diversos puede usar datos clínicos ordinarios para ayudar a detectar coágulos pulmonares con mayor precisión que los métodos individuales. Aunque el sistema aún necesita pruebas fuera del conjunto de datos utilizado aquí y no reemplaza a las exploraciones ni a los médicos, ofrece un camino práctico hacia herramientas de apoyo que destaquen a los pacientes de alto riesgo antes, reduzcan los diagnósticos perdidos y aprovechen mejor los datos hospitalarios existentes en entornos clínicos reales.
Cita: Abdelhamid, A., Moustafa, H.ED., Nafea, H.B. et al. Harnessing hybrid stacking ensemble learning for accurate pulmonary embolism diagnosis using tabular clinical data. Sci Rep 16, 15051 (2026). https://doi.org/10.1038/s41598-026-49331-3
Palabras clave: embolia pulmonar, datos clínicos, aprendizaje en ensamblaje, aprendizaje automático, diagnóstico médico