Clear Sky Science · it
Sfruttare un ensemble ibrido a stacking per una diagnosi accurata dell’embolia polmonare usando dati clinici tabulari
Perché è importante per l’assistenza ai pazienti
L’embolia polmonare è un coagulo di sangue nei polmoni che può uccidere in pochi minuti se non viene riconosciuto. I medici dipendono in larga misura da esami complessi e dal loro giudizio per individuarla in tempo. Questo studio esplora come sistemi informatici intelligenti possano usare informazioni cliniche di routine, piuttosto che solo immagini, per aiutare a segnalare i pazienti che potrebbero avere un coagulo nascosto, supportando decisioni più rapide e affidabili in ospedali affollati.
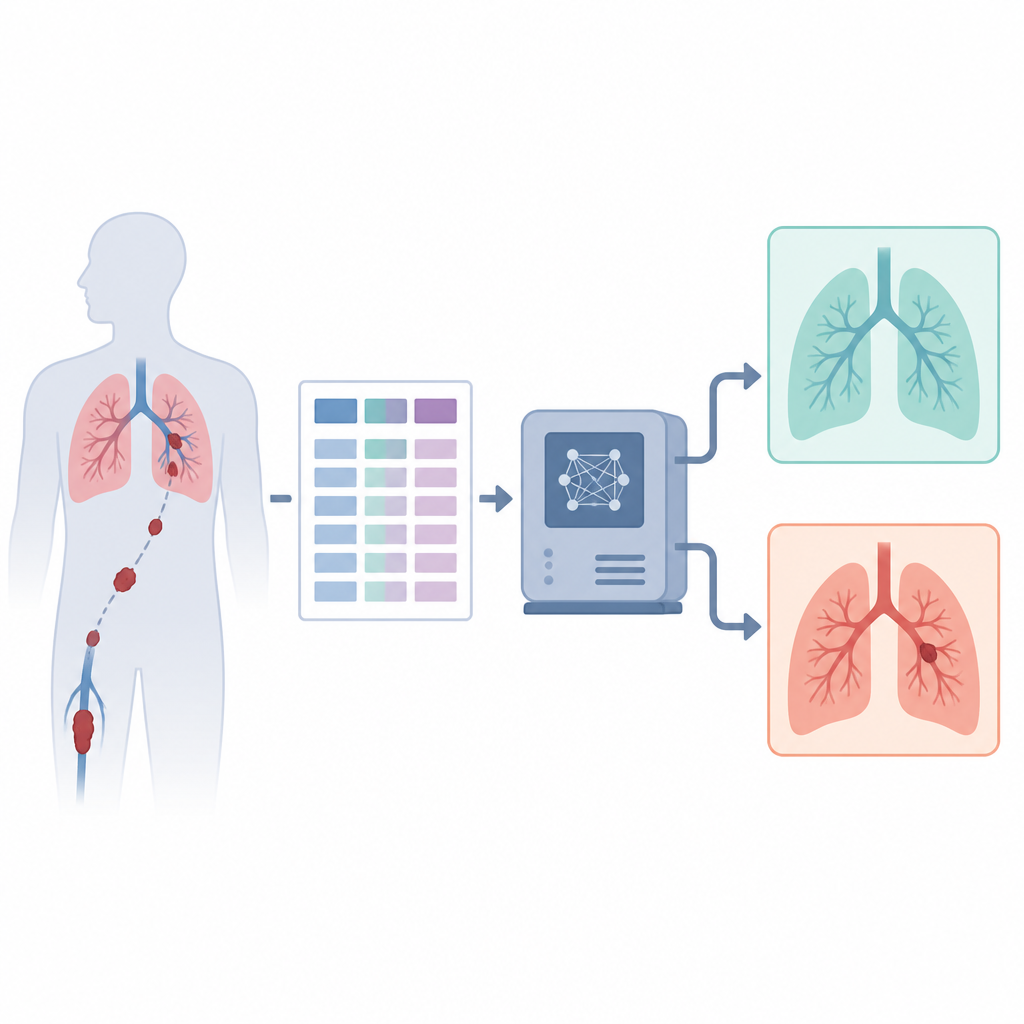
Il pericolo dei coaguli polmonari nascosti
L’embolia polmonare è una delle emergenze cardiache e polmonari più comuni e letali, dopo infarti e ictus. I coaguli che raggiungono i polmoni possono improvvisamente bloccare il flusso sanguigno, sforzare il lato destro del cuore e privare l’organismo di ossigeno. Molti pazienti muoiono prima che qualcuno capisca cosa sta succedendo. Tuttavia, quando la condizione viene riconosciuta rapidamente e trattata, le probabilità di sopravvivenza migliorano drasticamente. Questo divario tra rischio silenzioso e azione salvavita motiva la ricerca di strumenti che possano indirizzare i medici verso la diagnosi corretta prima possibile.
Limiti dei test e dei punteggi attuali
Oggi il test principale per l’embolia polmonare è un particolare tipo di TAC del torace. Pur essendo potenti, queste scansioni richiedono apparecchiature costose, valutatori esperti e tempo. I sistemi di punteggio clinico standard e singoli modelli di machine learning che usano dati di base del paziente hanno aiutato in qualche misura, ma spesso non colgono pattern sottili in dataset clinici ampi e misti. Con l’aumentare della raccolta di cartelle cliniche digitali, cresce la necessità di sistemi più intelligenti che possano apprendere da molti tipi di indizi clinici contemporaneamente e rimanere comunque affidabili e interpretabili dai clinici.
Una squadra di modelli che lavora insieme
Gli autori rispondono a questa esigenza utilizzando solo le informazioni cliniche strutturate presenti in un grande dataset pubblico di TAC, senza analizzare le immagini stesse. Costruiscono un ensemble ibrido a stacking, che può essere pensato come un comitato di diversi modelli informatici che votano insieme per stabilire se un paziente ha un coagulo. Il comitato include due modelli basati su alberi, una rete neurale classica e un modello transformer moderno progettato per dati tabulari. Ciascun modello produce una probabilità di presenza del coagulo, e un modello finale semplice impara a combinare queste opinioni in una decisione unica in modo da evitare overfitting e mantenere il comportamento stabile.
Lascare che la natura guidi la messa a punto
Per ottenere il massimo da questo comitato, i ricercatori utilizzano un metodo di ricerca ispirato alla natura chiamato algoritmo dei predatori marini. Questo metodo esplora molte combinazioni di parametri interni per ogni modello e molte modalità di pesare i loro output, un po’ come cacciatori virtuali che esplorano un grande oceano alla ricerca dei migliori fondali di pesca. Usando la cross-validation per proteggersi da risultati dovuti al caso, l’algoritmo converge su una configurazione che migliora la capacità del sistema nel separare i pazienti con e senza coaguli, rispetto a ciascun modello individuale o a schemi di voto più semplici.
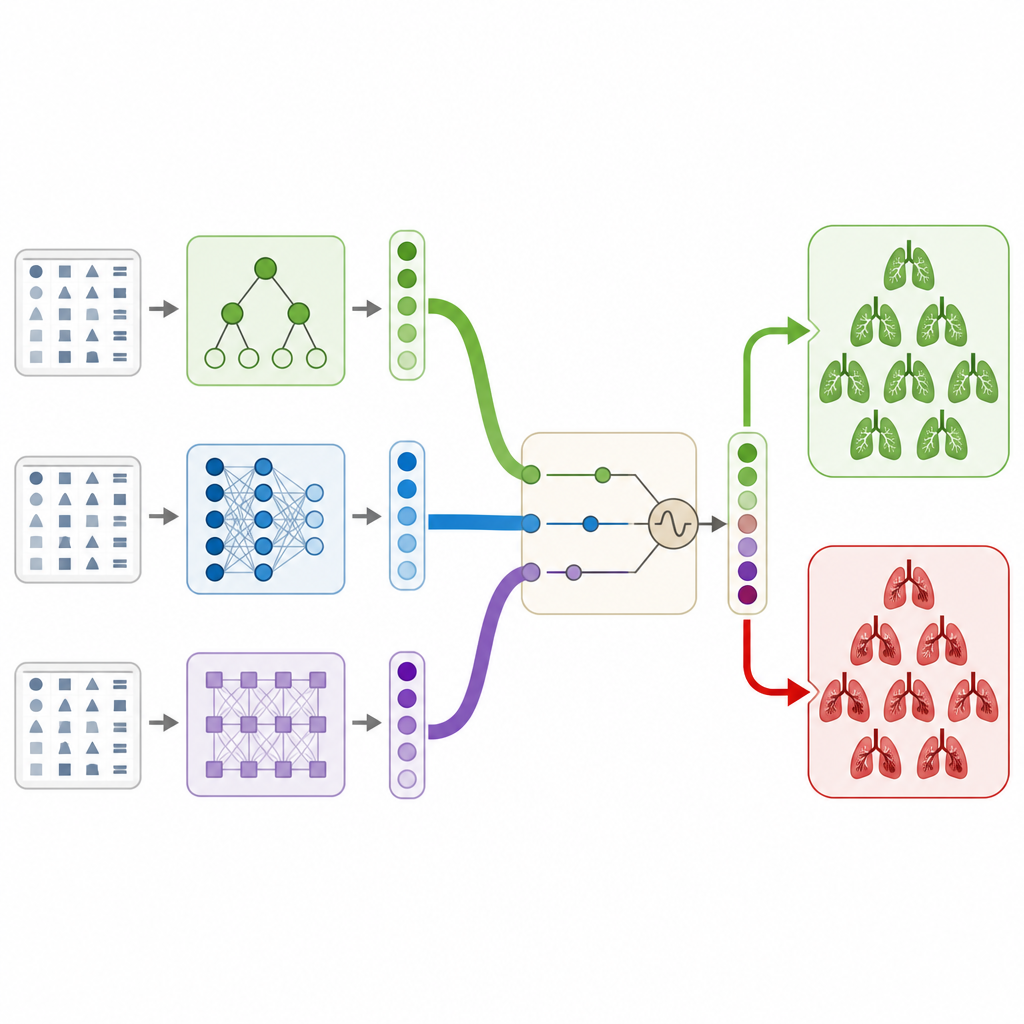
Quanto bene funziona il sistema e cosa apprende
Sul dataset pubblico RSNA per l’embolia polmonare, il sistema combinato raggiunge circa il 92 percento di accuratezza complessiva e una forte capacità di discriminazione tra casi positivi e negativi. Questo supera tutti i modelli individuali e diverse modalità standard di combinazione. Gli autori usano poi strumenti di spiegazione per vedere quali campi clinici influenzano maggiormente le predizioni. Caratteristiche che descrivono direttamente la presenza e il lato del coagulo, insieme a misure di sforzo del lato destro del cuore, hanno l’impatto maggiore, mentre indicatori tecnici sulla qualità dell’immagine influiscono poco. Questo schema è coerente con le conoscenze mediche, suggerendo che il modello si concentra su segnali clinicamente significativi piuttosto che sul rumore.
Cosa significa per la diagnosi futura
In termini pratici, questo lavoro dimostra che un team accuratamente tarato di modelli diversi può usare dati clinici ordinari per aiutare a individuare i coaguli polmonari in modo più accurato rispetto a metodi singoli. Pur richiedendo ancora test oltre il dataset utilizzato e senza sostituire le scansioni o i medici, offre una strada pratica verso strumenti di supporto che evidenziano prima i pazienti ad alto rischio, riducono le diagnosi mancate e sfruttano meglio i dati ospedalieri esistenti in contesti reali.
Citazione: Abdelhamid, A., Moustafa, H.ED., Nafea, H.B. et al. Harnessing hybrid stacking ensemble learning for accurate pulmonary embolism diagnosis using tabular clinical data. Sci Rep 16, 15051 (2026). https://doi.org/10.1038/s41598-026-49331-3
Parole chiave: embolia polmonare, dati clinici, ensemble learning, machine learning, diagnosi medica