Clear Sky Science · fr
Exploiter un empilement hybride en apprentissage par ensemble pour un diagnostic précis de l’embolie pulmonaire à partir de données cliniques tabulaires
Pourquoi cela compte pour la prise en charge des patients
L’embolie pulmonaire est un caillot de sang dans les poumons qui peut être mortel en quelques minutes s’il passe inaperçu. Les médecins s’appuient fortement sur des examens complexes et leur jugement pour le détecter à temps. Cette étude examine comment des systèmes informatiques intelligents peuvent utiliser des informations cliniques de routine, plutôt que les seules images, pour aider à signaler les patients susceptibles d’avoir un caillot caché, soutenant ainsi des décisions plus rapides et plus fiables dans des hôpitaux occupés.
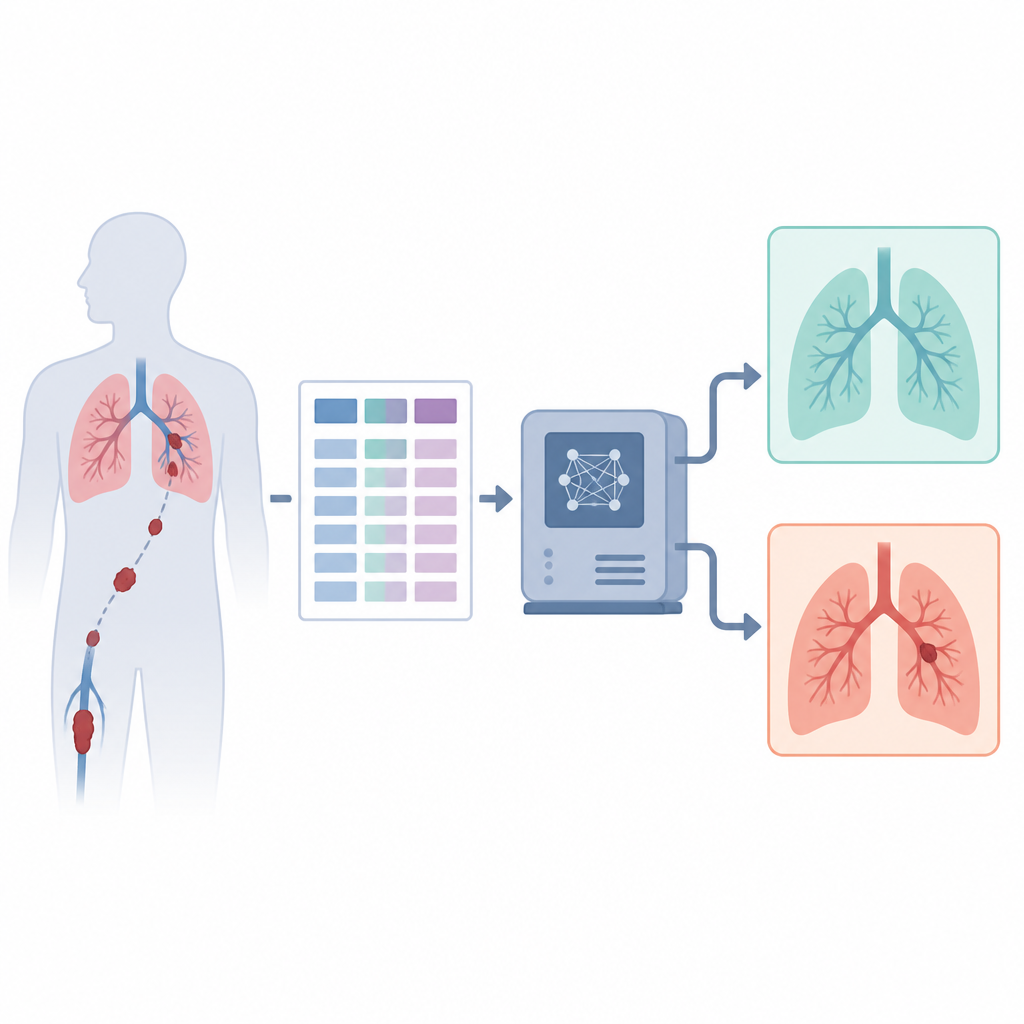
Le danger des caillots pulmonaires cachés
L’embolie pulmonaire est l’une des urgences cardiaques et pulmonaires mettant le plus en danger la vie, après les infarctus et les AVC. Les caillots qui se déplacent vers les poumons peuvent bloquer soudainement le flux sanguin, mettre à rude épreuve le côté droit du cœur et priver l’organisme d’oxygène. De nombreux patients décèdent avant que l’on comprenne ce qui se passe. Pourtant, lorsque l’affection est reconnue rapidement et traitée, les chances de survie s’améliorent considérablement. Cet écart entre un risque silencieux et une action salvatrice motive la recherche d’outils capables d’orienter les médecins vers le bon diagnostic plus tôt.
Limites des tests et scores actuels
Aujourd’hui, le principal examen pour l’embolie pulmonaire est un type particulier de scanner thoracique (CT). Bien que puissants, ces scanners requièrent des équipements coûteux, des lecteurs experts et du temps. Les scores cliniques standard et les modèles d’apprentissage automatique isolés utilisant des données patient de base ont aidé dans une certaine mesure, mais ils manquent souvent des motifs subtils présents dans de grands jeux de données cliniques hétérogènes. À mesure que les hôpitaux numérisent davantage leurs dossiers, le besoin de systèmes plus intelligents capables d’apprendre à partir de multiples indices cliniques simultanément tout en restant fiables et compréhensibles pour les cliniciens se fait sentir.
Une équipe de modèles qui travaillent ensemble
Les auteurs répondent à ce besoin en n’utilisant que les informations cliniques structurées associées à un large jeu de données public de CT, sans analyser les images elles‑mêmes. Ils construisent un empilement hybride (hybrid stacking ensemble), qu’il convient de voir comme un comité de modèles informatiques différents qui votent ensemble pour déterminer si un patient a un caillot. Le comité comprend deux modèles basés sur des arbres, un réseau de neurones classique et un modèle transformer moderne conçu pour des données de type tableau. Chaque modèle produit une probabilité de présence d’un caillot, et un modèle final simple apprend à combiner ces avis en une décision unique de façon à éviter le surapprentissage et à maintenir un comportement stable.
Laisser la nature guider l’optimisation
Pour tirer le meilleur parti de ce comité, les chercheurs utilisent une méthode de recherche inspirée de la nature appelée l’algorithme des prédateurs marins. Cette méthode explore de nombreuses combinaisons de paramètres internes pour chaque modèle et de nombreuses façons de pondérer leurs sorties, un peu comme des chasseurs virtuels explorant un vaste océan à la recherche des meilleurs bancs de poissons. En utilisant la validation croisée pour se prémunir contre les résultats dus au hasard, l’algorithme aboutit à une configuration qui améliore la capacité du système global à séparer les patients avec et sans caillots, comparativement à chaque modèle pris isolément ou à des schémas de vote plus simples.
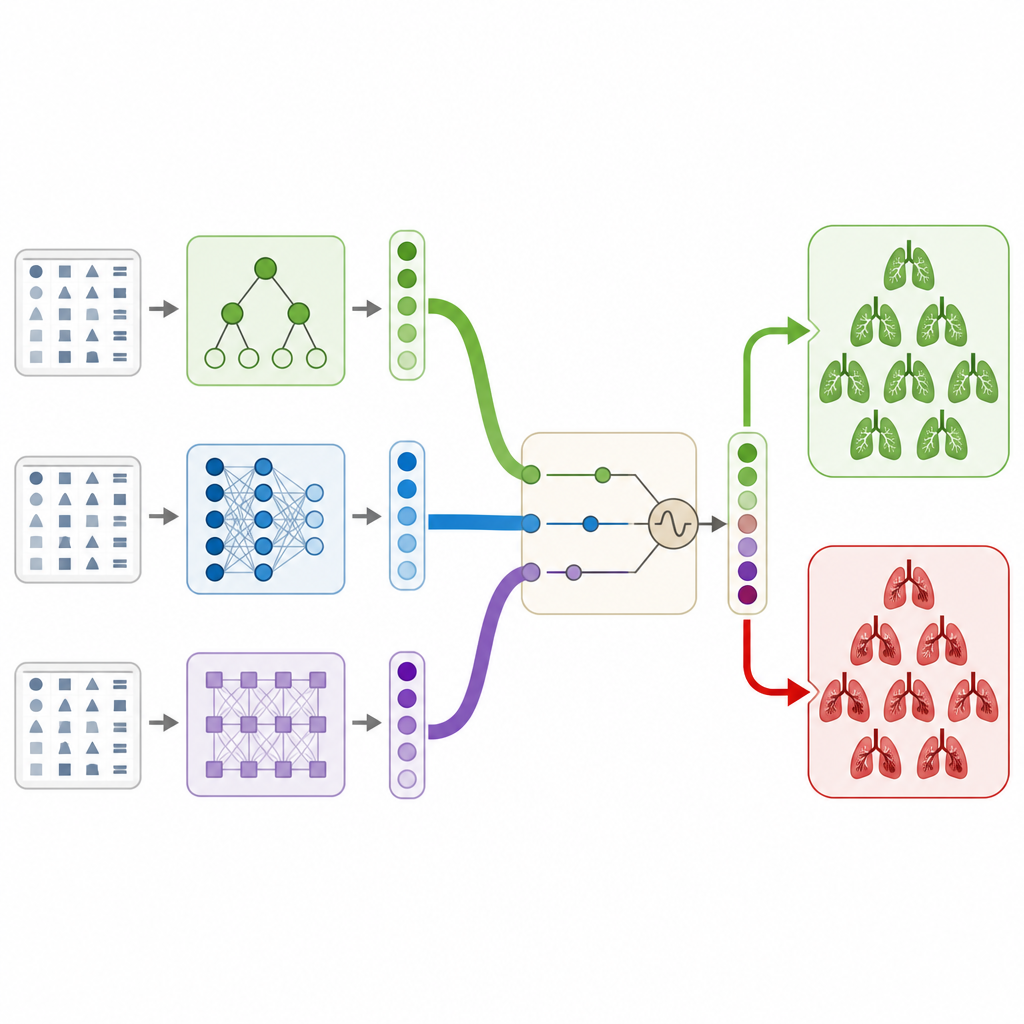
Performances du système et enseignements tirés
Sur le jeu de données public RSNA sur l’embolie pulmonaire, le système combiné atteint environ 92 % de précision globale et présente une forte capacité de discrimination entre cas positifs et négatifs. Cela surpasse tous les modèles individuels et plusieurs méthodes standard de combinaison. Les auteurs utilisent ensuite des outils d’explicabilité pour identifier les champs cliniques qui influencent le plus les prédictions. Les caractéristiques décrivant directement la présence et le côté du caillot, ainsi que des mesures de surcharge du côté droit du cœur, ont l’impact le plus important, tandis que les indicateurs techniques de qualité d’image ont peu d’effet. Ce schéma correspond aux connaissances médicales, ce qui suggère que le modèle se concentre sur des signaux cliniquement pertinents plutôt que sur du bruit.
Ce que cela signifie pour le diagnostic futur
En termes simples, ce travail montre qu’une équipe soigneusement optimisée de modèles divers peut utiliser des données cliniques ordinaires pour aider à détecter les caillots pulmonaires plus précisément que des méthodes isolées. Bien que le système doive encore être testé au‑delà du jeu de données utilisé ici et ne remplace pas les scanners ni les cliniciens, il offre une voie pragmatique vers des outils d’aide qui identifient plus tôt les patients à haut risque, réduisent les diagnostics manqués et valorisent mieux les données hospitalières existantes en conditions réelles.
Citation: Abdelhamid, A., Moustafa, H.ED., Nafea, H.B. et al. Harnessing hybrid stacking ensemble learning for accurate pulmonary embolism diagnosis using tabular clinical data. Sci Rep 16, 15051 (2026). https://doi.org/10.1038/s41598-026-49331-3
Mots-clés: embolie pulmonaire, données cliniques, apprentissage par ensemble, apprentissage automatique, diagnostic médical