Clear Sky Science · nl
Hybride stacked-ensemble learning benutten voor nauwkeurige diagnose van longembolie met tabelvormige klinische gegevens
Waarom dit belangrijk is voor de patiëntenzorg
Longembolie is een bloedstolsel in de longen dat binnen minuten dodelijk kan zijn als het wordt gemist. Artsen vertrouwen sterk op complexe scans en hun eigen beoordelingsvermogen om het op tijd te detecteren. Deze studie onderzoekt hoe slimme computersystemen routineklinische informatie, in plaats van alleen beelden, kunnen gebruiken om patiënten te signaleren die mogelijk een verborgen stolsel hebben, en zo snellere en betrouwbaarder beslissingen in drukke ziekenhuizen ondersteunen.
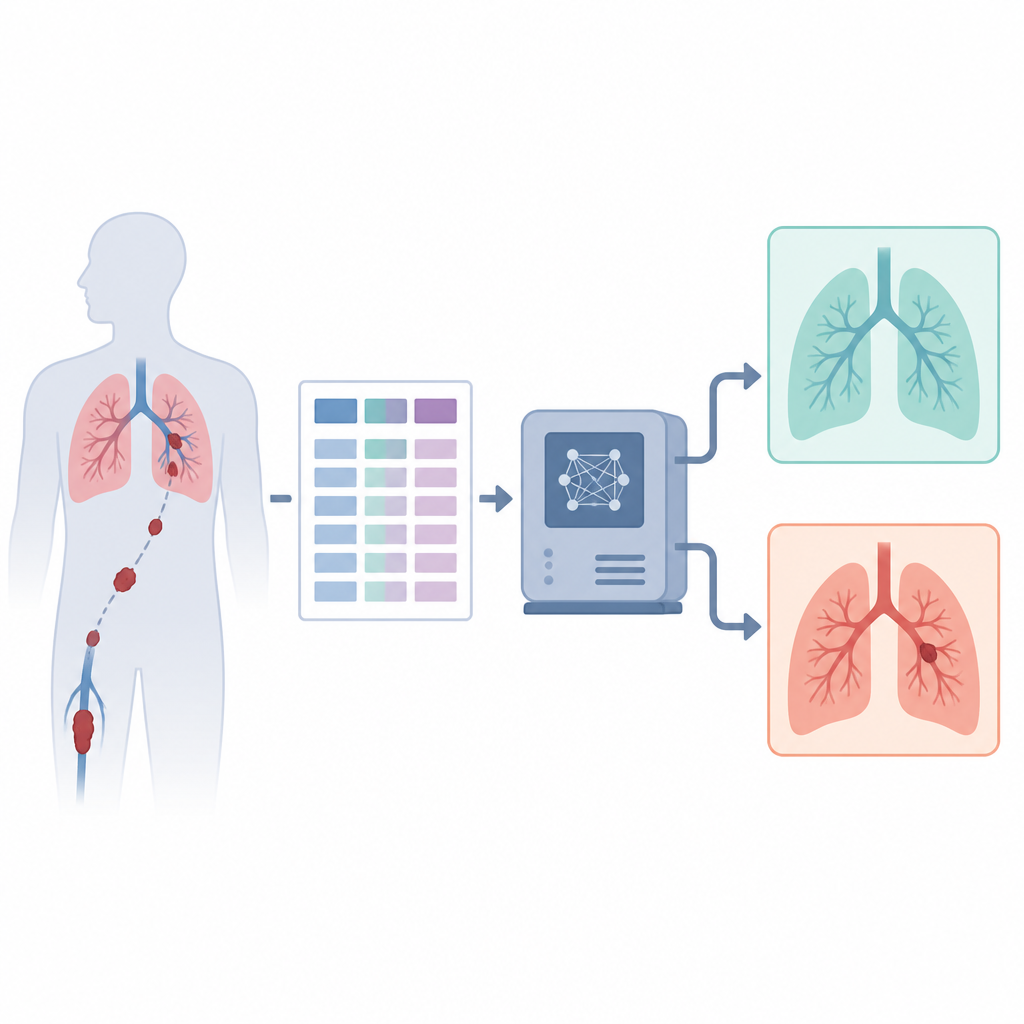
Het gevaar van verhulde longstolsels
Longembolie is een van de meest voorkomende levensbedreigende hart- en longnoodgevallen, na hartaanvallen en beroertes. Stolsels die naar de longen reizen kunnen plotseling de bloedstroom blokkeren, de rechterkant van het hart belasten en het lichaam van zuurstof beroven. Veel patiënten overlijden voordat iemand begrijpt wat er gebeurt. Wanneer de aandoening echter snel wordt herkend en behandeld, neemt de overlevingskans sterk toe. Deze kloof tussen stille risico’s en levensreddende actie drijft de zoektocht naar hulpmiddelen die artsen eerder naar de juiste diagnose kunnen leiden.
Beperkingen van huidige tests en scores
Vandaag is de belangrijkste test voor longembolie een speciaal soort CT-scan van de borst. Hoewel krachtig, vergen deze scans dure apparatuur, deskundige lezers en tijd. Standaard klinische score-systemen en enkele machinelearningmodellen die basale patiëntgegevens gebruiken hebben enigszins geholpen, maar ze missen vaak subtiele patronen in grote, heterogene klinische datasets. Nu ziekenhuizen meer digitale dossiers verzamelen, groeit de behoefte aan slimmere systemen die uit veel verschillende klinische aanwijzingen tegelijk kunnen leren en toch betrouwbaar en begrijpelijk voor clinici blijven.
Een team van modellen dat samenwerkt
De auteurs spelen hierop in door alleen de gestructureerde klinische informatie uit een grote openbare CT-dataset te gebruiken, zonder naar de beelden zelf te kijken. Ze bouwen een hybride stacked-ensemble, het best te zien als een commissie van verschillende computermodellen die gezamenlijk stemmen over de vraag of een patiënt een stolsel heeft. De commissie omvat twee boomgebaseerde modellen, een klassiek neuraal netwerk en een moderne transformer ontworpen voor tabelachtige data. Elk model levert een kansschatting dat er een stolsel aanwezig is, en een eenvoudig uiteindelijk model leert hoe het deze meningen samen te voegen tot één beslissing op een manier die overfitting vermijdt en het gedrag stabiel houdt.
Natuur als gids voor afstemming
Om het meeste uit deze commissie te halen, gebruiken de onderzoekers een door de natuur geïnspireerde zoekmethode genaamd het marine predators-algoritme. Deze methode verkent vele combinaties van interne instellingen voor elk model en vele manieren om hun uitkomsten te wegen, vergelijkbaar met virtuele jagers die een grote oceaan afzoeken naar de beste visgronden. Met behulp van cross-validatie om toevallige bevindingen tegen te gaan, komt het algoritme tot een configuratie die verbetert hoe goed het volledige systeem patiënten met en zonder stolsels scheidt, vergeleken met elk individueel model of eenvoudigere stemschema’s.
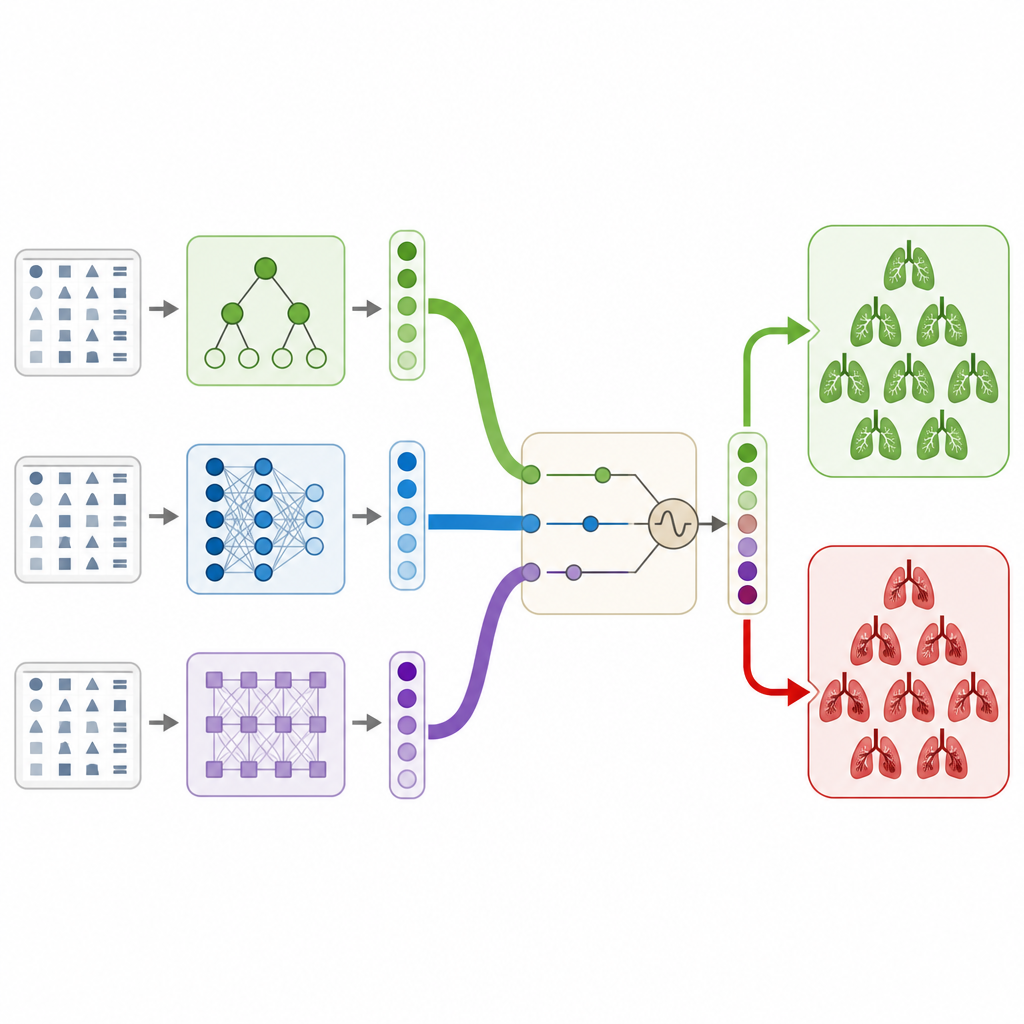
Prestaties van het systeem en wat het leert
Op de openbare RSNA-longembolie-dataset bereikt het gecombineerde systeem ongeveer 92 procent totale nauwkeurigheid en een sterke maat voor discriminatie tussen positieve en negatieve gevallen. Dit overtreft alle individuele modellen en verschillende standaardmanieren om ze te combineren. De auteurs gebruiken vervolgens verklaringshulpmiddelen om te bekijken welke klinische velden de voorspellingen het meest beïnvloeden. Kenmerken die direct de aanwezigheid en zijde van een stolsel beschrijven, samen met metingen van belasting aan de rechterkant van het hart, hebben de grootste impact, terwijl technische kwaliteitsflags van beelden weinig effect hebben. Dit patroon komt overeen met medische kennis, wat suggereert dat het model zich richt op klinisch relevante signalen in plaats van ruis.
Wat dit betekent voor toekomstige diagnoses
In gewone taal laat dit werk zien dat een zorgvuldig afgestemd team van diverse computermodellen gewone klinische gegevens kan gebruiken om longstolsels nauwkeuriger op te sporen dan individuele methoden. Hoewel het systeem nog getest moet worden buiten de gebruikte dataset en het geen scans of artsen vervangt, biedt het een praktische route naar ondersteunende hulpmiddelen die hoogrisicopatiënten eerder signaleren, gemiste diagnoses verminderen en bestaande ziekenhuisdata in de praktijk beter benutten.
Bronvermelding: Abdelhamid, A., Moustafa, H.ED., Nafea, H.B. et al. Harnessing hybrid stacking ensemble learning for accurate pulmonary embolism diagnosis using tabular clinical data. Sci Rep 16, 15051 (2026). https://doi.org/10.1038/s41598-026-49331-3
Trefwoorden: longembolie, klinische gegevens, ensemble learning, machine learning, medische diagnose