Clear Sky Science · pt
Sensibilidade ao tamanho do mini-lote em redes residuais profundas para previsão de carga de curto prazo: um estudo empírico
Por que esta pesquisa importa para os consumidores de energia
Manter as luzes acesas a um preço justo depende de quão bem as empresas de energia conseguem estimar a demanda de eletricidade do dia seguinte. Este estudo examina uma escolha de treinamento surpreendentemente simples dentro de modelos modernos de inteligência artificial que prevêem a demanda: quantos exemplos mostrar ao modelo de uma vez. Ao testar cuidadosamente esse “tamanho do mini-lote”, os autores mostram que acertar esse detalhe pode tornar as previsões mais precisas e mais confiáveis em climas muito diferentes.
Como a demanda de energia é prevista hoje
A demanda por eletricidade varia com a hora do dia, a estação e o tempo, e até pequenos ganhos na precisão das previsões podem economizar milhões de dólares por ano para grandes concessionárias. Métodos mais antigos dependiam de fórmulas estatísticas que tinham dificuldade com os padrões de uso complexos atuais. Modelos de deep learning mais recentes lidam melhor com comportamentos não lineares e ruido, mas podem ser difíceis de treinar. Em particular, redes residuais profundas, que passam informação adiante por caminhos de atalho, tornaram-se populares para prever demanda de curto prazo porque conseguem aprender padrões profundos sem se tornarem instáveis.
Duas redes, dois climas, uma pergunta
Para entender como escolhas de treinamento afetam esses modelos, os autores estudam dois sistemas elétricos reais. Um está na Nova Inglaterra, nos Estados Unidos, com grandes oscilações sazonais devido ao aquecimento no inverno e ao resfriamento no verão. O outro fica na Malásia tropical, onde as estações são menos pronunciadas e rajadas de tempo e chuva têm mais influência. Para a Nova Inglaterra, eles usam uma rede residual que recebe séries históricas de demanda e temperatura. Para a Malásia, testam esse modelo e uma variante que comprime muitas medições meteorológicas em poucas características combinadas usando uma técnica matemática, reduzindo redundância ao mesmo tempo que preserva a maior parte da informação climática útil. 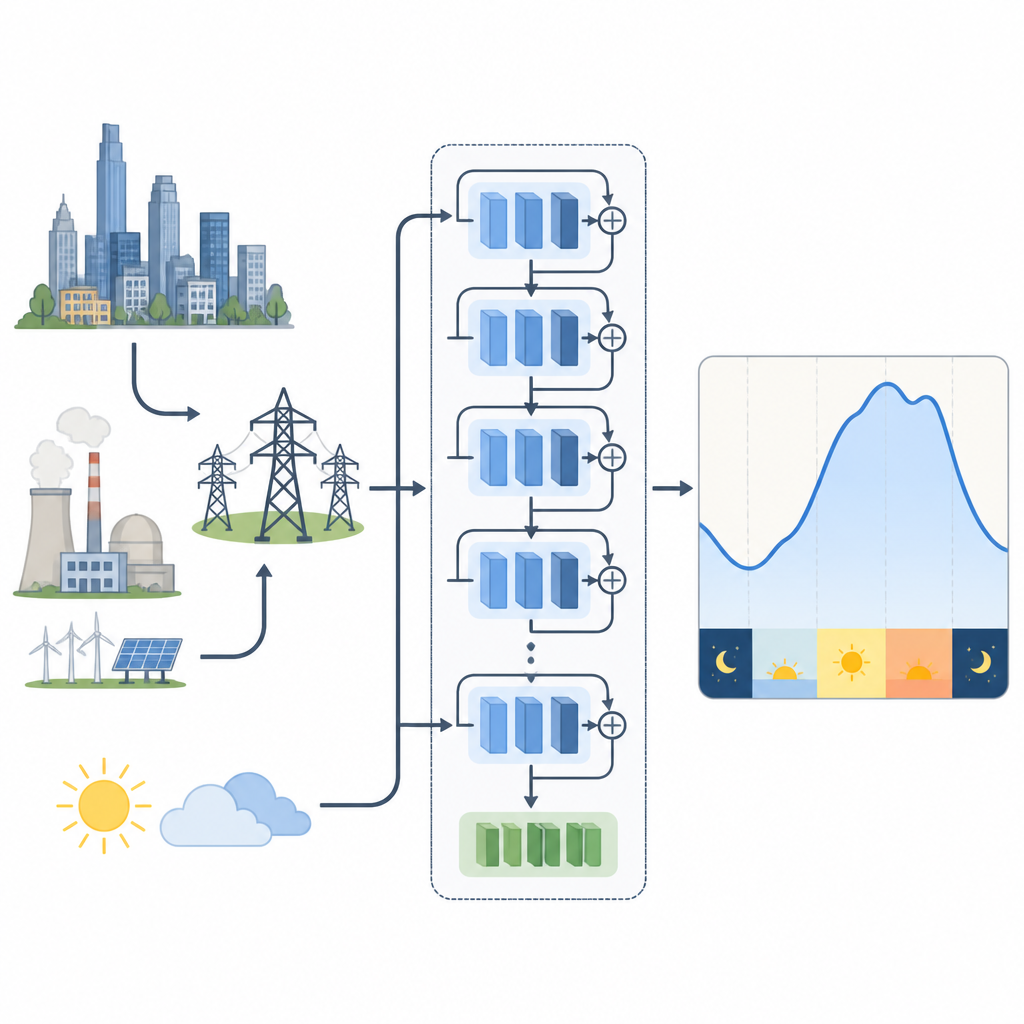
O que o tamanho do mini-lote controla na prática
Treinar um modelo de deep learning significa ajustar milhões de parâmetros internos para reduzir a diferença entre a demanda prevista e a real. O tamanho do mini-lote é o número de pontos no tempo que o modelo vê antes de cada ajuste. Lotes pequenos tornam as atualizações ruidosas e aleatórias, o que pode ajudar o modelo a explorar, mas também deixar o treinamento instável. Lotes muito grandes produzem atualizações mais suaves, mas podem empurrar o modelo para soluções que se ajustam demais aos dados de treinamento e generalizam mal. A questão central é se existe um ponto ideal para essas redes residuais usadas na previsão de energia, e se esse ponto é o mesmo em climas diferentes e com entradas meteorológicas mais ricas.
O que os experimentos revelaram
Em um cenário fortemente controlado em que apenas o tamanho do mini-lote foi alterado, os autores testaram valores desde muito pequenos até muito grandes. Em ambos os sistemas, Nova Inglaterra e Malásia, descobriram que lotes de tamanho médio produziram as melhores previsões. Na prática, um tamanho de lote de 64 consistentemente gerou os menores erros, com 32 ficando logo atrás. Lotes menores tornaram o treinamento menos estável e menos preciso, enquanto lotes maiores degradaram o desempenho de forma contínua. Ao comparar suas redes residuais com outros projetos populares de deep learning baseados em convoluções, unidades recorrentes, atenção ou híbridos desses, os modelos residuais saíram na frente. A versão que combinou múltiplas medições meteorológicas em um resumo compacto teve o melhor desempenho no caso tropical. 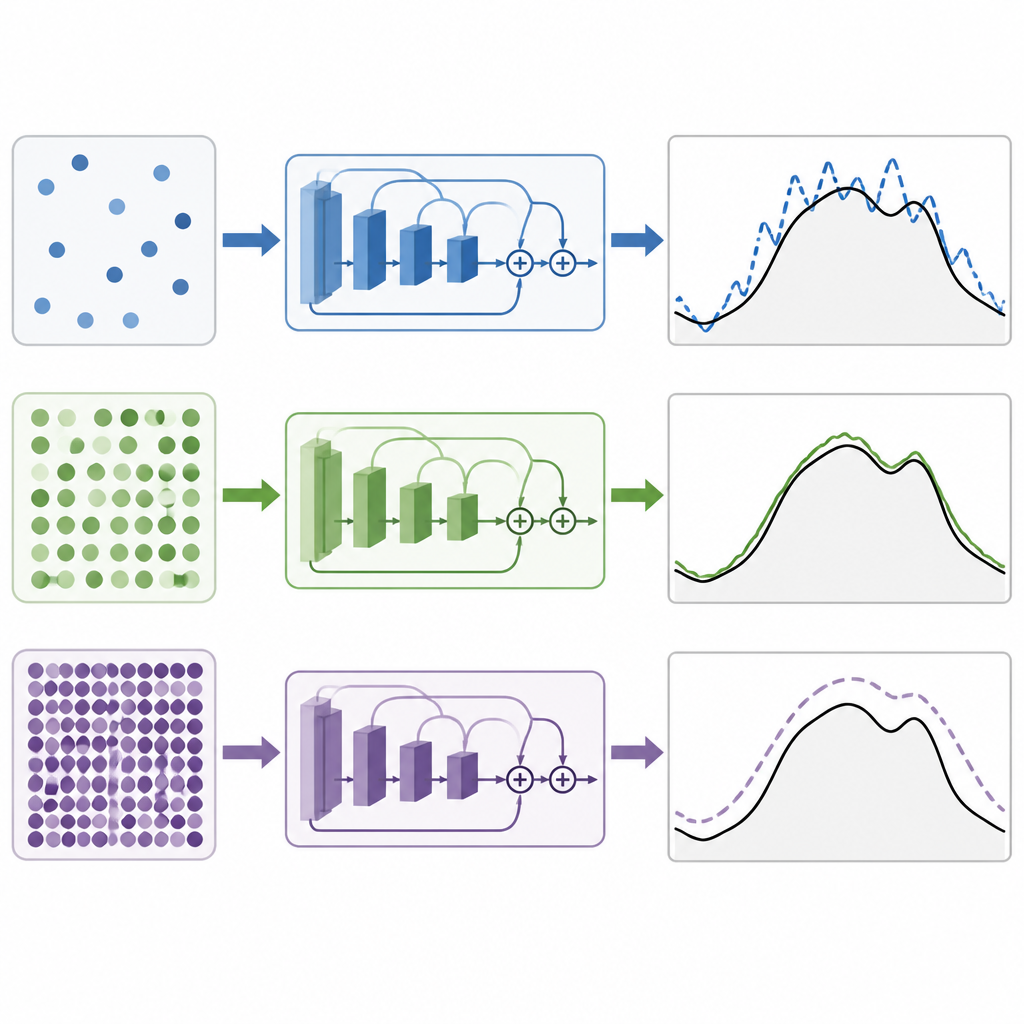
Como os autores verificaram os resultados
Para garantir que esses padrões não fossem apenas sorte, o estudo usou uma técnica de reamostragem chamada bootstrap. Esse método recalcula repetidamente as diferenças de desempenho usando versões embaralhadas dos erros para estimar quão provável é que as melhorias observadas ocorram por acaso. A análise mostrou que os ganhos ao usar um tamanho de lote de 64 em vez de 32 foram estatisticamente significativos, e que o modelo com compressão dos dados meteorológicos superou de forma consistente e confiável a rede residual básica sob as mesmas condições de treinamento.
O que isso significa para o planejamento energético
Para não-especialistas, a mensagem principal é que escolhas de treinamento aparentemente pequenas dentro de modelos de inteligência artificial podem mudar de forma perceptível o quão bem conseguimos prever a demanda de eletricidade do dia seguinte. Este trabalho mostra que, para redes residuais profundas usadas em previsão de carga de curto prazo, tamanhos de lote intermediários oferecem um bom equilíbrio entre estabilidade e flexibilidade do aprendizado, e que fornecer informações meteorológicas bem comprimidas pode afiar ainda mais as previsões. Em conjunto, esses insights oferecem orientação prática para concessionárias e engenheiros que buscam construir redes mais inteligentes e eficientes sem redesenhar completamente seus modelos.
Citação: Liu, J., Ahmad, F.A., Samsudin, K. et al. Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study. Sci Rep 16, 14996 (2026). https://doi.org/10.1038/s41598-026-45002-5
Palavras-chave: previsão de carga de curto prazo, redes residuais profundas, tamanho do mini-lote, demanda de eletricidade, dados meteorológicos