Clear Sky Science · fr
Sensibilité de la taille du mini-lot dans les réseaux résiduels profonds pour la prévision de charge à court terme : une étude empirique
Pourquoi cette recherche compte pour les utilisateurs d’électricité au quotidien
Maintenir l’électricité allumée à un prix raisonnable dépend de la capacité des entreprises d’énergie à estimer la demande d’électricité de demain. Cette étude examine un choix d’entraînement étonnamment simple au sein des modèles d’intelligence artificielle modernes qui prédisent la demande : combien d’exemples montrer au modèle à la fois. En testant soigneusement cette « taille de mini-lot », les auteurs montrent qu’un bon réglage de ce paramètre peut rendre les prévisions plus précises et plus fiables dans des climats très différents.
Comment la demande d’électricité est prédite aujourd’hui
La demande d’électricité varie selon l’heure de la journée, la saison et la météo, et même de petites améliorations de la précision des prévisions peuvent économiser des millions de dollars par an pour les grands fournisseurs. Les méthodes de prévision plus anciennes reposaient sur des formules statistiques qui peinaient à capter les schémas d’usage complexes d’aujourd’hui. Les modèles de deep learning plus récents gèrent mieux les comportements non linéaires et bruités mais peuvent être difficiles à entraîner. En particulier, les réseaux résiduels profonds, qui font circuler l’information via des chemins de raccourci, sont devenus populaires pour la prévision à court terme car ils peuvent apprendre des motifs profonds sans devenir instables.
Deux réseaux, deux climats, une question
Pour voir comment les choix d’entraînement affectent ces modèles, les auteurs étudient deux systèmes électriques réels. Le premier est en Nouvelle-Angleterre aux États-Unis, avec de fortes variations saisonnières dues au chauffage en hiver et à la climatisation en été. L’autre se situe en Malaisie tropicale, où les saisons sont moins marquées et où de courts épisodes météorologiques et de pluie jouent un rôle plus important. Pour la Nouvelle-Angleterre, ils utilisent un réseau résiduel qui prend en entrée la demande passée et la température. Pour la Malaisie, ils testent ce modèle et une variante qui compresse de nombreuses mesures météorologiques en une poignée de caractéristiques combinées clés à l’aide d’une technique mathématique, réduisant la redondance tout en conservant l’essentiel de l’information climatique utile. 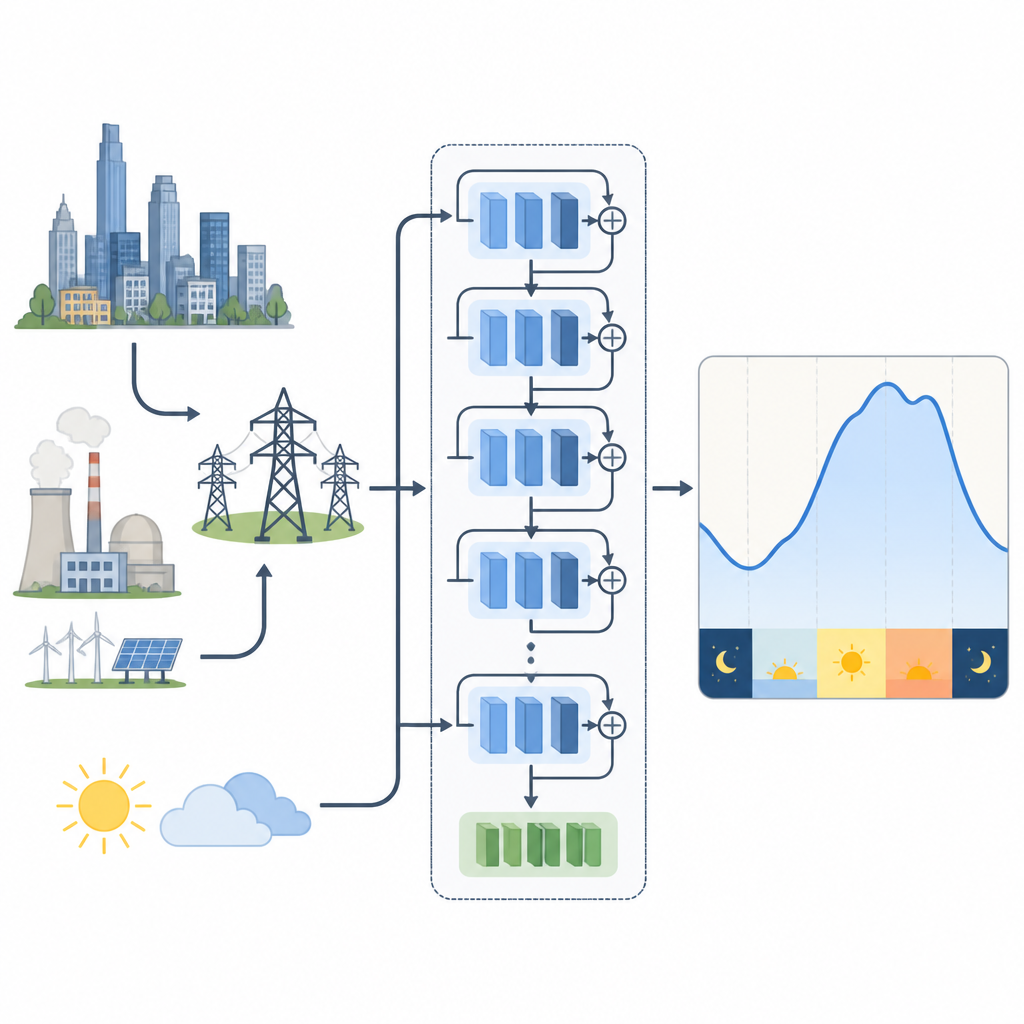
Ce que contrôle réellement la taille du mini-lot
Entraîner un modèle de deep learning signifie ajuster des millions de paramètres internes pour réduire l’écart entre la demande prédite et la demande réelle. La taille du mini-lot est le nombre de points temporels que le modèle voit avant chaque ajustement. De petits lots rendent les mises à jour bruyantes et aléatoires, ce qui peut aider le modèle à explorer mais aussi rendre l’entraînement instable. Des lots très grands donnent des mises à jour plus lisses mais peuvent pousser le modèle vers des solutions qui s’ajustent trop aux données d’entraînement et se généralisent mal. La question clé est de savoir s’il existe un point optimal pour ces réseaux résiduels utilisés en prévision électrique, et si ce point est le même selon les climats et selon la richesse des entrées météorologiques.
Ce que les expériences ont révélé
Dans un dispositif strictement contrôlé où seule la taille du mini-lot variait, les auteurs ont testé des valeurs allant de très petites à très grandes. Pour les deux systèmes, Nouvelle-Angleterre et Malaisie, ils ont constaté que des lots de taille moyenne donnaient les meilleures prévisions. Concrètement, une taille de lot de 64 a produit de façon régulière les erreurs les plus faibles, 32 arrivant juste derrière. Les petits lots rendaient l’entraînement moins stable et moins précis, tandis que les grands lots dégradaient progressivement la performance. En comparant leurs réseaux résiduels à d’autres architectures populaires de deep learning basées sur des convolutions, des unités récurrentes, l’attention ou des hybrides, les modèles résiduels se sont montrés supérieurs. La version compressant plusieurs mesures météo en un résumé compact a donné les meilleurs résultats dans le cas tropical. 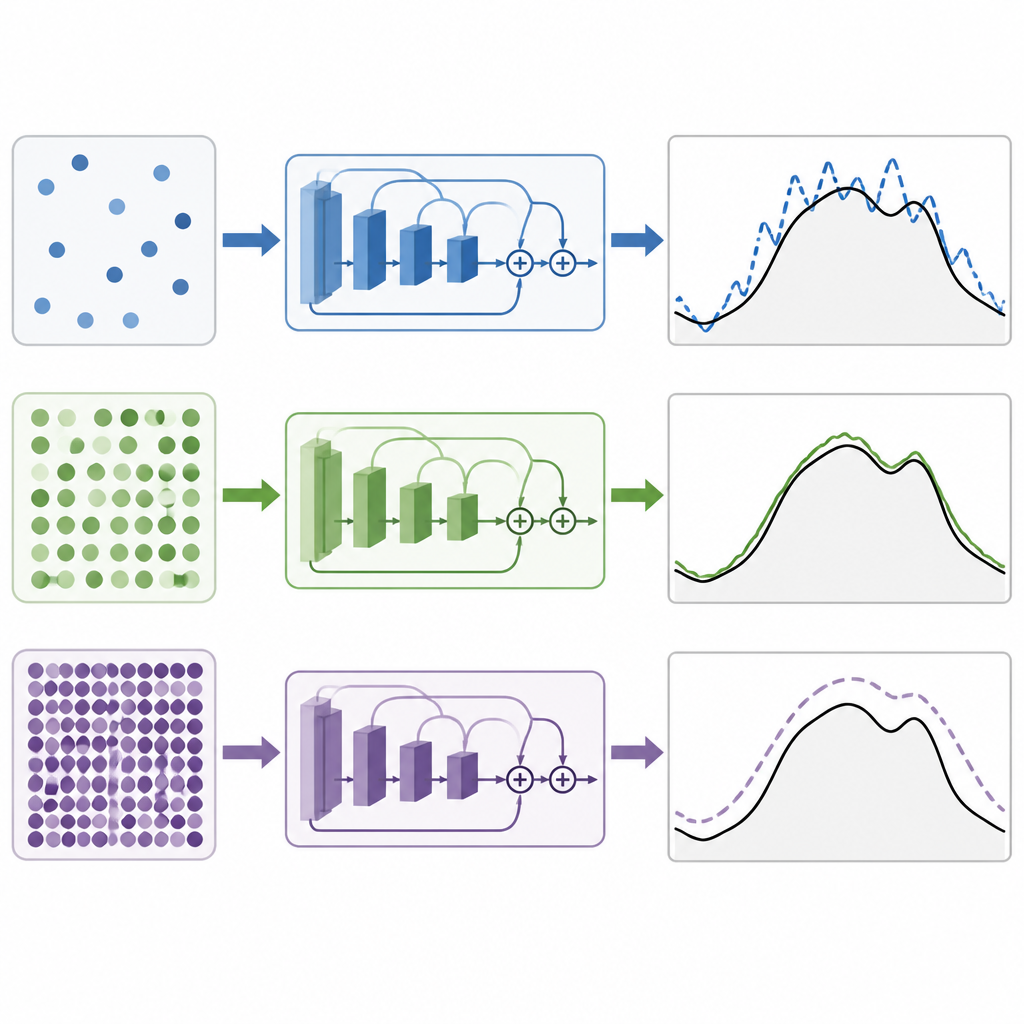
Comment les auteurs ont vérifié leurs résultats
Pour s’assurer que ces tendances n’étaient pas des artefacts dus au hasard, l’étude a utilisé une technique de rééchantillonnage appelée bootstrap. Cette méthode recalculer de façon répétée les différences de performance en utilisant des versions reshufflées des erreurs afin d’estimer la probabilité que les améliorations observées soient dues au hasard. L’analyse a montré que les gains obtenus en utilisant une taille de lot de 64 plutôt que 32 étaient statistiquement significatifs, et que le modèle avec météo compressée surpassait de façon constante et fiable le réseau résiduel de base dans les mêmes conditions d’entraînement.
Ce que cela signifie pour la planification électrique
Pour les non-spécialistes, le message principal est que des choix d’entraînement apparemment mineurs dans les modèles d’intelligence artificielle peuvent modifier de façon notable notre capacité à prévoir la demande électrique de demain. Ce travail montre que, pour les réseaux résiduels profonds utilisés en prévision de charge à court terme, des tailles de lot intermédiaires offrent un bon compromis entre stabilité et flexibilité d’apprentissage, et que l’apport d’informations météorologiques bien compressées peut affiner encore les prévisions. Ensemble, ces enseignements fournissent des orientations pratiques pour les services publics et les ingénieurs souhaitant construire des réseaux plus intelligents et plus efficaces sans repenser leurs modèles de A à Z.
Citation: Liu, J., Ahmad, F.A., Samsudin, K. et al. Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study. Sci Rep 16, 14996 (2026). https://doi.org/10.1038/s41598-026-45002-5
Mots-clés: prévision de charge à court terme, réseaux résiduels profonds, taille du mini-lot, demande d’électricité, données météorologiques