Clear Sky Science · nl
Gevoeligheid voor mini-batchgrootte in diepe residuele netwerken voor kortetermijnvraagprognoses: een empirische studie
Waarom dit onderzoek belangrijk is voor alledaagse energiekopers
De lichten brandend houden tegen een redelijke prijs hangt af van hoe goed energiebedrijven de elektriciteitsvraag van morgen kunnen inschatten. Deze studie richt zich op een verrassend eenvoudige trainingskeuze binnen moderne kunstmatige-intelligentiemodellen die de vraag voorspellen: hoeveel voorbeelden het model tegelijk te zien krijgt. Door de "mini-batchgrootte" zorgvuldig te testen, laten de auteurs zien dat het correct instellen van dit detail prognoses aanzienlijk accurater en betrouwbaarder kan maken in zeer verschillende klimaten.
Hoe de vraag naar stroom tegenwoordig wordt voorspeld
De elektriciteitsvraag varieert met tijdstip van de dag, seizoen en weer; zelfs kleine verbeteringen in voorspelnauwkeurigheid kunnen energiebedrijven miljoenen dollars per jaar besparen. Oudere voorspellingsmethoden leunden op statistische formules die moeite hadden met de complexe gebruikspatronen van nu. Nieuwere deep learning‑modellen gaan beter om met rommelig, niet-lineair gedrag maar zijn lastiger te trainen. In het bijzonder zijn diepe residuele netwerken, die informatie via shortcut-paden doorgeven, populair geworden voor kortetermijnvoorspellingen omdat ze diepe patronen kunnen leren zonder instabiel te worden.
Twee netten, twee klimaten, één vraag
Om te onderzoeken hoe trainingskeuzes deze modellen beïnvloeden, bestuderen de auteurs twee reële elektriciteitssystemen. Het ene bevindt zich in New England (Verenigde Staten), met sterke seizoensschommelingen door verwarming in de winter en koeling in de zomer. Het andere ligt in tropisch Maleisië, waar seizoenen minder uitgesproken zijn en korte weers- en regenbuien belangrijker zijn. Voor New England gebruiken ze een residueel netwerk dat vroegere vraag en temperatuur verwerkt. Voor Maleisië testen ze zowel dit model als een variant die veel weersmetingen comprimeert tot een handvol gecombineerde kernkenmerken met een wiskundige techniek, waardoor redundantie wordt verminderd terwijl het meeste bruikbare klimaatinformatie behouden blijft. 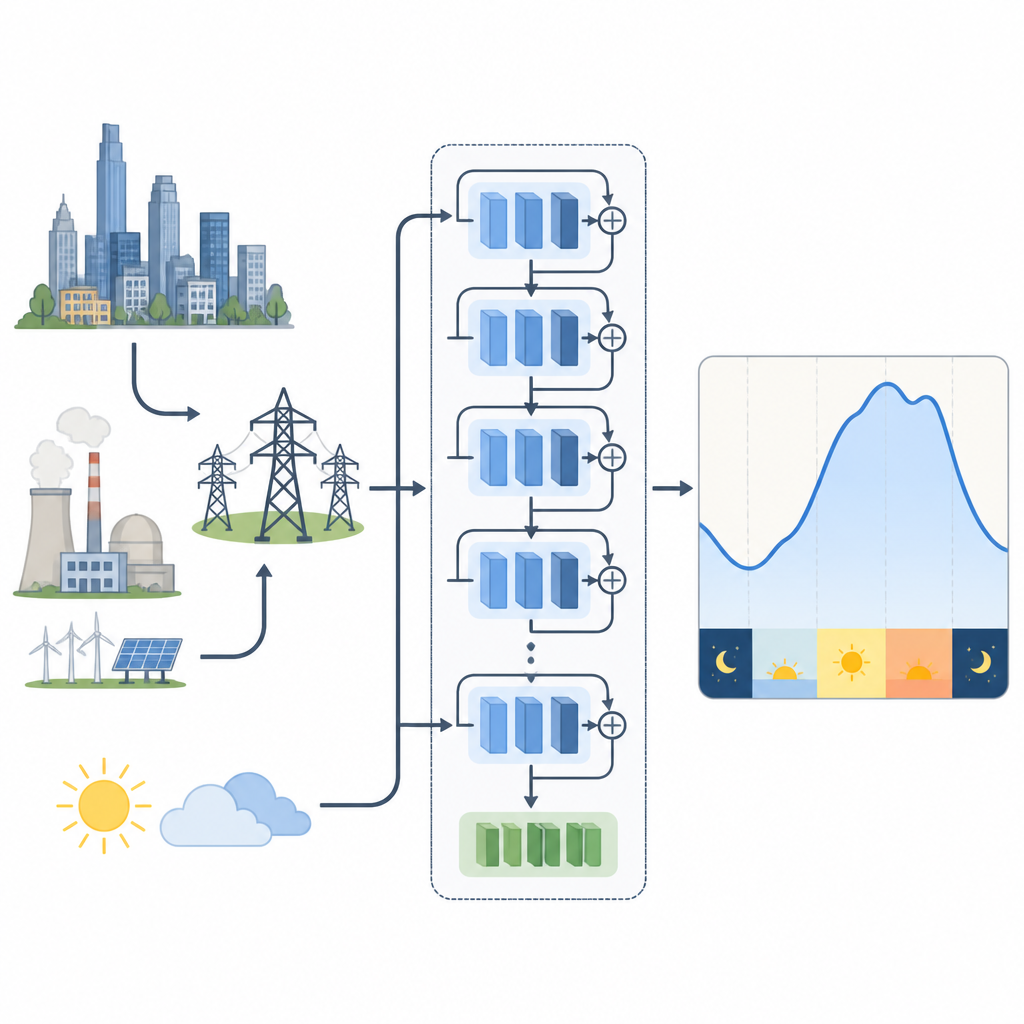
Wat de mini-batchgrootte eigenlijk regelt
Het trainen van een deep learning‑model betekent het aanpassen van miljoenen interne parameters om het verschil tussen voorspelde en werkelijke vraag te verkleinen. De mini-batchgrootte is het aantal tijdstippen dat het model ziet voordat het een update uitvoert. Kleine batches maken updates rumoeriger en meer willekeurig, wat het model kan helpen te verkennen maar de training ook onstabiel maakt. Zeer grote batches geven gladdere updates maar kunnen het model richting oplossingen duwen die te strak op de trainingsdata passen en slecht generaliseren. De kernvraag is of er een gulden middenweg bestaat voor deze residuele netwerken die voor vraagvoorspelling worden gebruikt, en of die plek hetzelfde is in verschillende klimaten en met rijkere weersinput.
Wat de experimenten onthulden
Onder een strikt gecontroleerde opzet waarbij alleen de mini-batchgrootte werd aangepast, probeerden de auteurs waarden van zeer klein tot zeer groot. In zowel de New England‑ als de Maleisische systemen bleek dat middelgrote batches de beste voorspellingen opleverden. In de praktijk gaf een batchgrootte van 64 consequent de laagste fouten, met 32 daar kort achter. Kleinere batches maakten de training minder stabiel en minder precies, terwijl grotere batches de prestaties gestaag verslechterden. Bij vergelijking van hun residuele netwerken met andere gangbare deep learning‑ontwerpen op basis van convoluties, recurrente eenheden, attention of hybride vormen daarvan, kwamen de residuele modellen als winnaar uit de bus. De versie die meerdere weersmetingen tot een compacte samenvatting combineerde presteerde in het tropische geval het beste. 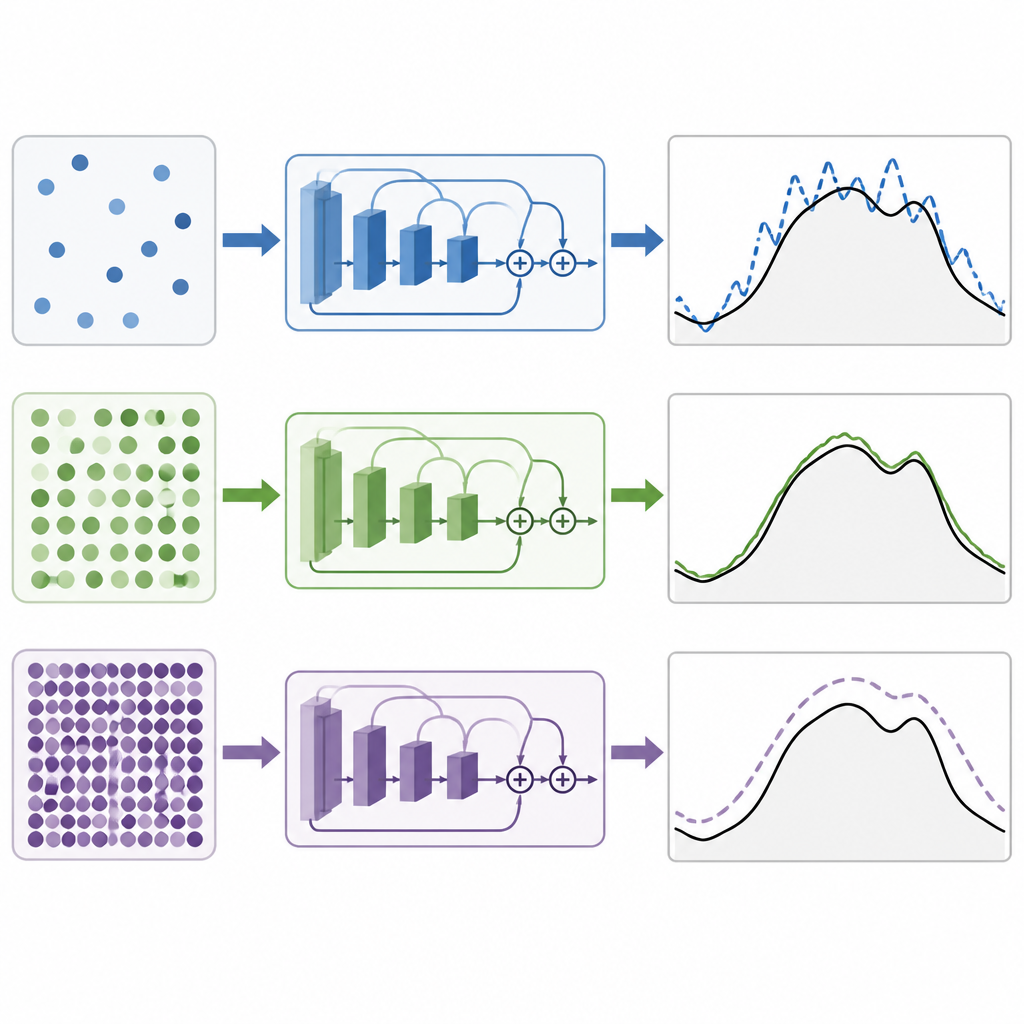
Hoe de auteurs hun resultaten controleerden
Om zeker te zijn dat deze patronen geen toevalstreffers waren, gebruikte de studie een hersamplingstechniek genaamd bootstrapping. Deze methode herberekent herhaaldelijk prestatieverschillen met geschudde versies van de fouten om te schatten hoe waarschijnlijk het is dat de waargenomen verbeteringen door toeval zijn. De analyse wees uit dat de winst bij het gebruik van batchgrootte 64 in plaats van 32 statistisch significant was, en dat het met weerscompressie verrijkte model consequent en betrouwbaar beter presteerde dan het basale residuele netwerk onder dezelfde trainingscondities.
Wat dit betekent voor energieplanning
Voor niet‑specialisten is de kernboodschap dat schijnbaar kleine trainingskeuzes binnen AI‑modellen merkbaar kunnen beïnvloeden hoe goed we de elektriciteitsvraag van morgen kunnen voorspellen. Dit werk laat zien dat voor diepe residuele netwerken in kortetermijnvraagvoorspelling middengrote batchgroottes een goede balans bieden tussen leerstabiliteit en flexibiliteit, en dat het invoeren van goed gecomprimeerde weersinformatie voorspellingen verder kan scherpen. Gezamenlijk bieden deze inzichten praktische richtlijnen voor netbeheerders en ingenieurs die slimmere, efficiëntere netten willen bouwen zonder hun modellen helemaal opnieuw te ontwerpen.
Bronvermelding: Liu, J., Ahmad, F.A., Samsudin, K. et al. Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study. Sci Rep 16, 14996 (2026). https://doi.org/10.1038/s41598-026-45002-5
Trefwoorden: kortetermijnvraagvoorspelling, diepe residuele netwerken, mini-batchgrootte, elektriciteitsvraag, weersgegevens