Clear Sky Science · pl
Wrażliwość rozmiaru mini-batchy w głębokich sieciach resztkowych dla krótkoterminowego prognozowania obciążenia: badanie empiryczne
Dlaczego to badanie ma znaczenie dla codziennych użytkowników energii
Utrzymanie dostaw energii przy uczciwych cenach zależy od tego, jak dobrze firmy energetyczne potrafią przewidzieć zapotrzebowanie na energię na jutro. W niniejszym badaniu przeanalizowano zaskakująco prosty wybór w procesie trenowania współczesnych modeli sztucznej inteligencji służących do prognozowania popytu: ile przykładów pokazywać modelowi jednocześnie. Dokładne przetestowanie tego „rozmiaru mini-batcha” pokazuje, że dopracowanie tego szczegółu może uczynić prognozy bardziej precyzyjnymi i bardziej niezawodnymi w bardzo różnych klimatach.
Jak dziś przewiduje się zapotrzebowanie na energię
Zapotrzebowanie na energię zmienia się w ciągu dnia, sezonu i pod wpływem pogody, a nawet niewielkie poprawy dokładności prognoz mogą przynieść wielkim przedsiębiorstwom energetycznym milionowe oszczędności rocznie. Starsze metody prognostyczne opierały się na formułach statystycznych, które miały trudności z dzisiejszymi złożonymi wzorcami zużycia. Nowsze modele głębokiego uczenia lepiej radzą sobie z chaotycznymi, nieliniowymi zachowaniami, ale bywają trudne w trenowaniu. W szczególności głębokie sieci resztkowe, które przekazują informacje naprzód przez ścieżki skrótowe, zyskały popularność w prognozowaniu krótkoterminowego zapotrzebowania, ponieważ potrafią uczyć głębokie wzorce bez niestabilności.
Dwie sieci, dwa klimaty, jedno pytanie
Aby sprawdzić, jak wybory treningowe wpływają na te modele, autorzy zbadali dwa rzeczywiste systemy elektroenergetyczne. Jeden znajduje się w Nowej Anglii w Stanach Zjednoczonych, z wyraźnymi wahaniami sezonowymi spowodowanymi ogrzewaniem zimą i chłodzeniem latem. Drugi leży w tropikalnej Malezji, gdzie sezony są słabiej zaznaczone, a krótkotrwałe zjawiska pogodowe i opady mają większe znaczenie. Dla Nowej Anglii użyto sieci resztkowej przyjmującej przeszłe zapotrzebowanie i temperaturę. Dla Malezji przetestowano zarówno ten model, jak i wariant, który kompresuje wiele pomiarów pogodowych do kilku kluczowych zbiorczych cech za pomocą techniki matematycznej, redukując redundancję przy zachowaniu większości użytecznej informacji klimatycznej. 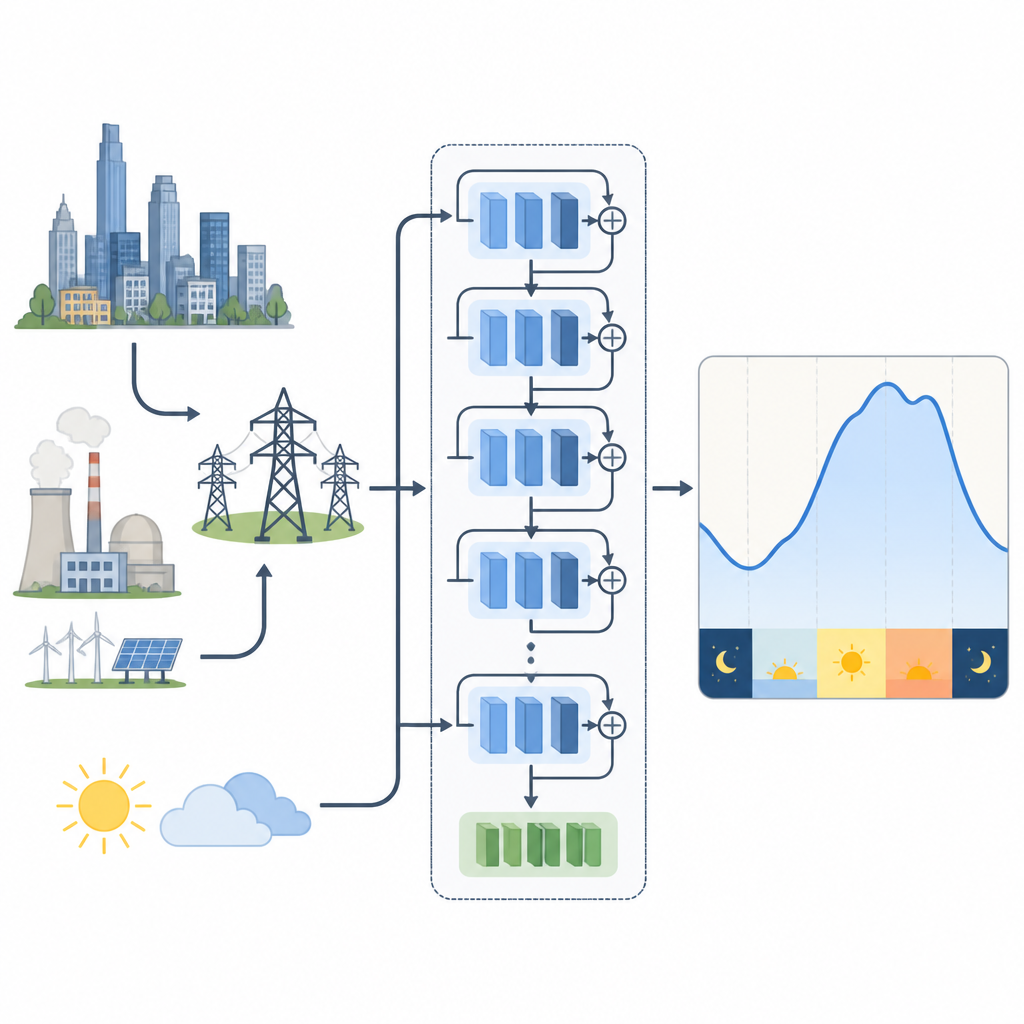
Co właściwie kontroluje rozmiar mini-batcha
Trenowanie modelu głębokiego uczenia oznacza dostosowywanie milionów wewnętrznych ustawień, aby zmniejszyć różnicę między prognozami a rzeczywistym popytem. Rozmiar mini-batcha to liczba punktów czasowych, które model widzi przed każdą korektą. Małe partie powodują hałaśliwe, losowe aktualizacje, co może pomóc modelowi eksplorować, ale też uczynić trening niestabilnym. Bardzo duże partie dają gładsze aktualizacje, ale mogą skierować model ku rozwiązaniom, które zbyt ściśle dopasowują się do danych treningowych i słabo uogólniają. Kluczowe pytanie brzmi, czy istnieje optymalny punkt dla tych sieci resztkowych stosowanych w prognozowaniu energii i czy ten punkt jest taki sam w różnych klimatach i przy bogatszych wejściach pogodowych.
Co wykazały eksperymenty
W ściśle kontrolowanym ustawieniu, gdzie zmieniano tylko rozmiar mini-batcha, autorzy testowali wartości od bardzo małych do bardzo dużych. Zarówno dla systemów w Nowej Anglii, jak i w Malezji stwierdzili, że partie o średnim rozmiarze dawały najlepsze prognozy. W praktyce rozmiar partii równy 64 konsekwentnie przynosił najmniejsze błędy, przy czym 32 było blisko drugiego miejsca. Mniejsze partie powodowały mniej stabilne i mniej dokładne trenowanie, podczas gdy większe partie stopniowo pogarszały wyniki. Porównując sieci resztkowe z innymi popularnymi architekturami głębokiego uczenia opartymi na konwolucjach, jednostkach rekurencyjnych, mechanizmach uwagi lub ich hybrydach, modele resztkowe wypadały lepiej. Wariant łączący wiele pomiarów pogodowych w zwartą reprezentację osiągnął najlepsze wyniki w przypadku tropikalnym. 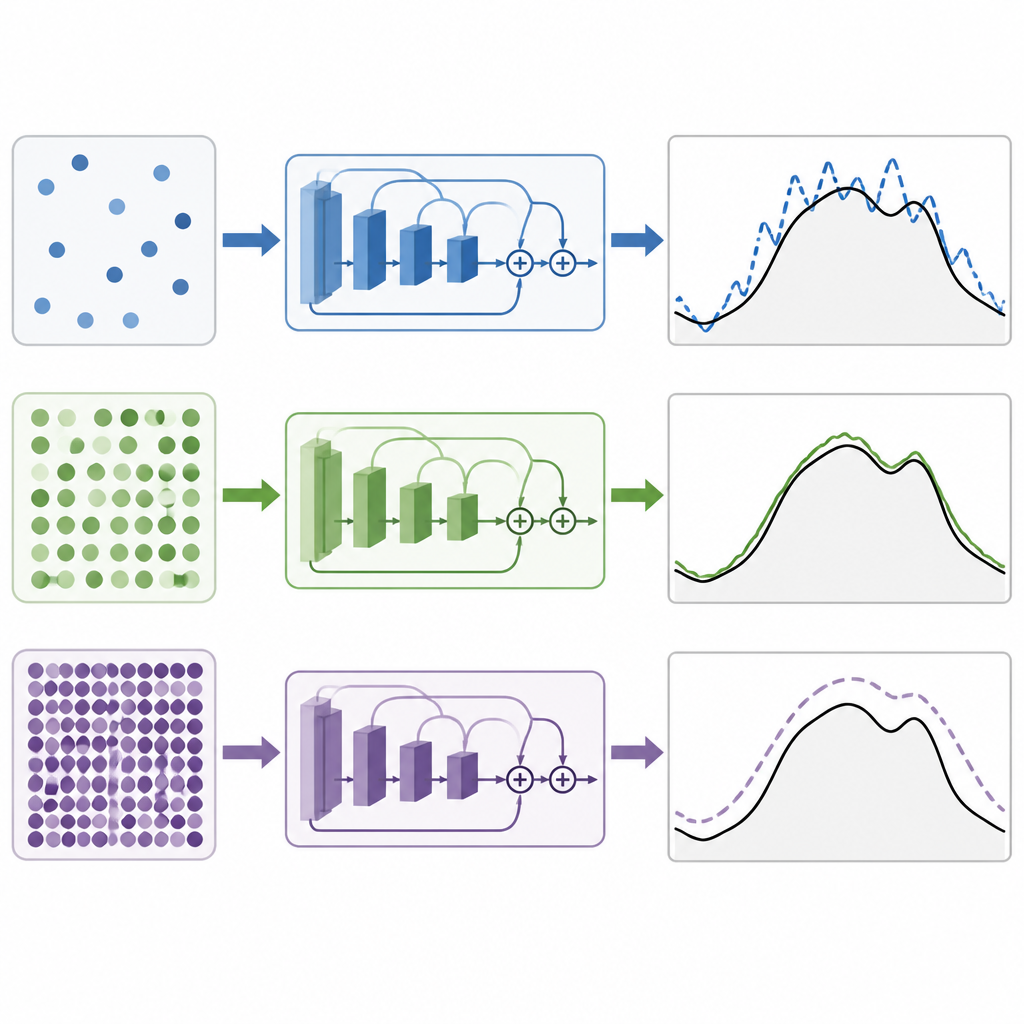
Jak autorzy weryfikowali swoje wyniki
Aby upewnić się, że zaobserwowane wzorce nie były przypadkowe, badanie zastosowało technikę resamplingu zwaną bootstrappingiem. Metoda ta wielokrotnie przelicza różnice wydajności używając przetasowanych wersji błędów, aby oszacować, jak prawdopodobne jest, że obserwowane ulepszenia wystąpiły przypadkowo. Analiza wykazała, że zyski wynikające z użycia rozmiaru partii 64 zamiast 32 były istotne statystycznie, a model ze skompresowanymi danymi pogodowymi konsekwentnie i niezawodnie przewyższał podstawową sieć resztkową przy tych samych warunkach treningowych.
Co to oznacza dla planowania energetycznego
Dla osób nietechnicznych główny przekaz jest taki, że pozornie drobne decyzje dotyczące treningu modeli sztucznej inteligencji mogą wyraźnie zmienić, jak dobrze potrafimy przewidzieć zapotrzebowanie na energię na jutro. Praca ta pokazuje, że dla głębokich sieci resztkowych stosowanych w krótkoterminowym prognozowaniu obciążenia rozmiary partii ze średniego zakresu oferują dobrą równowagę między stabilnością uczenia a elastycznością, a dobrze skompresowane informacje pogodowe mogą dodatkowo poprawić jakość prognoz. Razem te wnioski dostarczają praktycznych wskazówek dla przedsiębiorstw energetycznych i inżynierów dążących do budowy inteligentniejszych, wydajniejszych sieci bez konieczności całkowitej przebudowy modeli.
Cytowanie: Liu, J., Ahmad, F.A., Samsudin, K. et al. Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study. Sci Rep 16, 14996 (2026). https://doi.org/10.1038/s41598-026-45002-5
Słowa kluczowe: krótkoterminowe prognozowanie obciążenia, głębokie sieci resztkowe, rozmiar mini-batch, zapotrzebowanie na energię elektryczną, dane pogodowe