Clear Sky Science · en
Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study
Why this research matters for everyday power users
Keeping the lights on at a fair price depends on how well power companies can guess tomorrow’s electricity demand. This study looks at a surprisingly simple training choice inside modern artificial intelligence models that forecast demand: how many examples to show the model at once. By testing this “mini-batch size” carefully, the authors show that getting this detail right can make forecasts more accurate and more reliable across very different climates.
How power demand is predicted today
Electricity demand changes with time of day, season, and weather, and even small gains in forecast accuracy can save big utilities millions of dollars each year. Older forecasting methods relied on statistical formulas that struggled with today’s complex usage patterns. Newer deep learning models handle messy, nonlinear behavior better but can be hard to train. In particular, deep residual networks, which pass information forward through shortcut paths, have become popular for predicting short-term demand because they can learn deep patterns without becoming unstable.
Two grids, two climates, one question
To see how training choices affect these models, the authors study two real-world power systems. One is in New England in the United States, with strong seasonal swings from winter heating and summer cooling. The other is in tropical Malaysia, where seasons are less pronounced and short bursts of weather and rain matter more. For New England they use a residual network that takes past demand and temperature. For Malaysia they test both this model and a variant that compresses many weather measurements into a handful of key combined features using a mathematical technique, cutting redundancy while keeping most of the useful climate information. 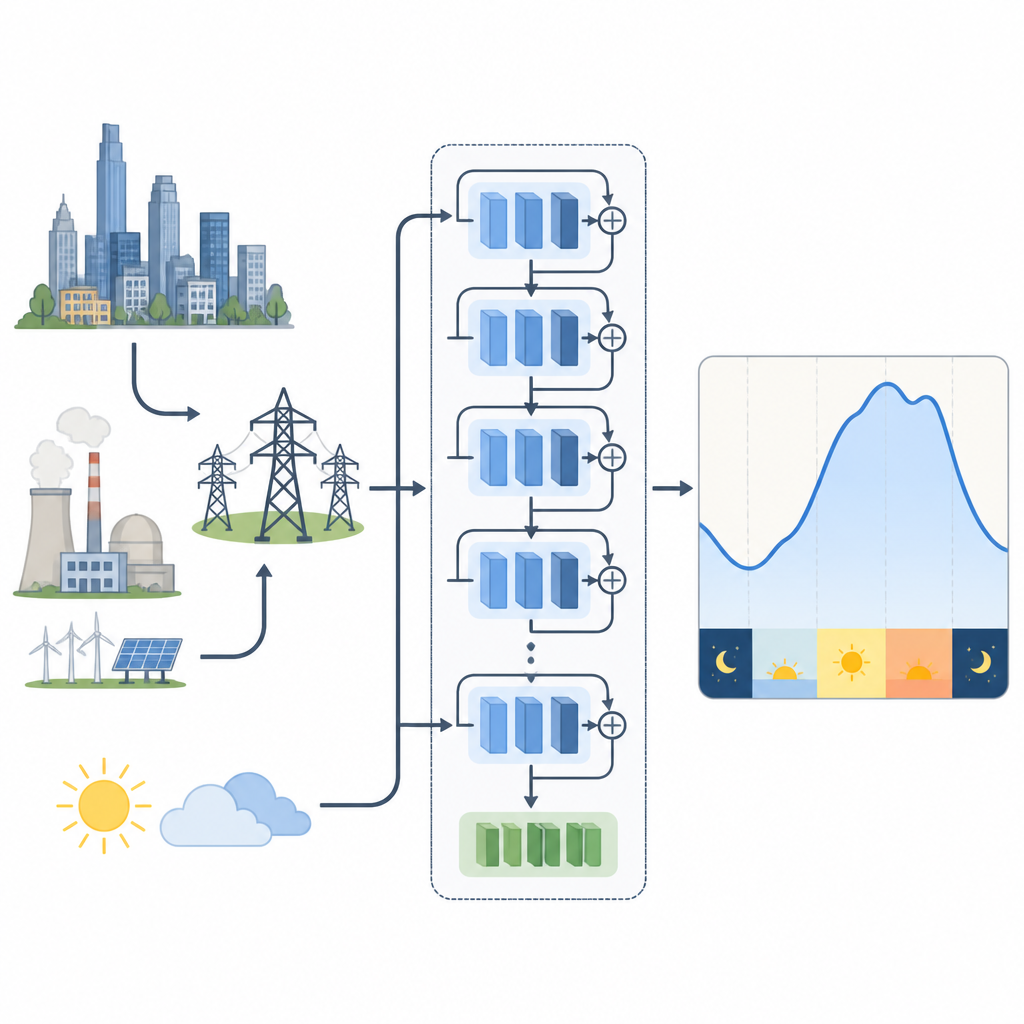
What mini-batch size actually controls
Training a deep learning model means adjusting millions of internal settings to reduce the gap between predicted and actual demand. The mini-batch size is the number of time points the model sees before each adjustment. Small batches make updates noisy and random, which can help the model explore but also make training jumpy. Very large batches give smoother updates but can push the model toward solutions that fit the training data too tightly and generalize poorly. The key question is whether there is a sweet spot for these residual networks used in power forecasting, and whether that spot is the same in different climates and with richer weather inputs.
What the experiments revealed
Under a tightly controlled setup where only the mini-batch size was changed, the authors tried values from very small to very large. On both the New England and Malaysian systems, they found that medium-sized batches gave the best forecasts. In practice, a batch size of 64 consistently produced the lowest errors, with 32 close behind. Smaller batches made training less stable and less accurate, while larger batches steadily worsened performance. When they compared their residual networks to other popular deep learning designs based on convolutions, recurrent units, attention, or hybrids of these, the residual models came out ahead. The version that combined multiple weather measurements into a compact summary performed best of all in the tropical case. 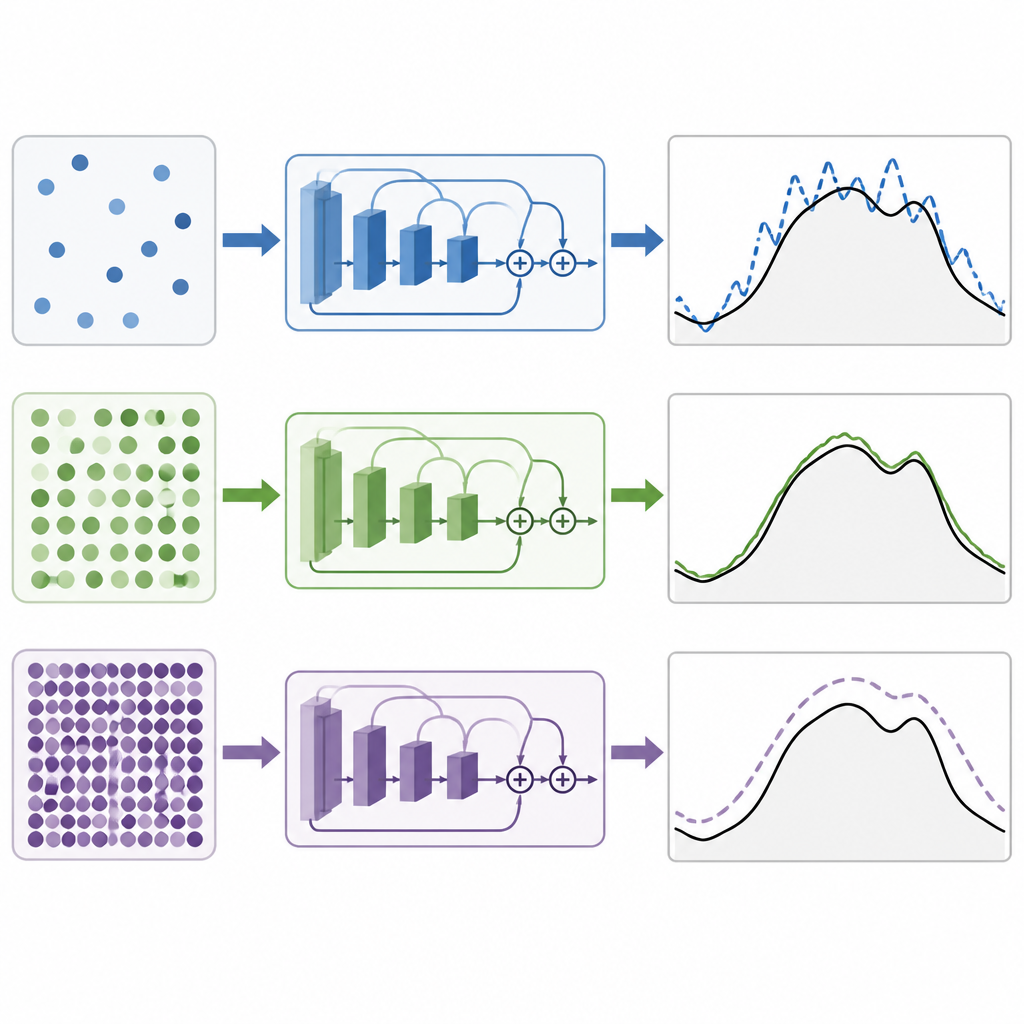
How the authors checked their results
To make sure these patterns were not just lucky runs, the study used a resampling technique called bootstrapping. This method repeatedly recomputes performance differences using shuffled versions of the errors to estimate how likely the observed improvements are to happen by chance. The analysis showed that the gains from using a batch size of 64 instead of 32 were statistically significant, and that the weather-compressed model consistently and reliably outperformed the basic residual network under the same training conditions.
What this means for power planning
For non-specialists, the core message is that seemingly minor training choices inside artificial intelligence models can noticeably change how well we can predict tomorrow’s electricity demand. This work shows that, for deep residual networks used in short-term load forecasting, mid-range batch sizes offer a good balance between learning stability and flexibility, and that feeding in well-compressed weather information can further sharpen forecasts. Together these insights provide practical guidance for utilities and engineers aiming to build smarter, more efficient grids without redesigning their models from scratch.
Citation: Liu, J., Ahmad, F.A., Samsudin, K. et al. Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study. Sci Rep 16, 14996 (2026). https://doi.org/10.1038/s41598-026-45002-5
Keywords: short term load forecasting, deep residual networks, mini batch size, electricity demand, weather data