Clear Sky Science · it
Sensibilità della dimensione del mini-batch nelle reti residuali profonde per la previsione a breve termine del carico: uno studio empirico
Perché questa ricerca è importante per gli utenti comuni
Mantenere le luci accese a un prezzo equo dipende da quanto bene le aziende elettriche riescono a stimare la domanda di elettricità del giorno successivo. Questo studio analizza una scelta di addestramento sorprendentemente semplice all’interno dei moderni modelli di intelligenza artificiale che prevedono la domanda: quante istanze mostrare al modello in una volta. Testando con cura questa “dimensione del mini-batch”, gli autori dimostrano che curare questo dettaglio può rendere le previsioni più accurate e più affidabili in climi molto diversi.
Come viene prevista oggi la domanda di energia
La domanda di elettricità varia con l’ora del giorno, la stagione e il meteo, e anche piccoli miglioramenti nell’accuratezza delle previsioni possono far risparmiare alle grandi utility milioni di dollari ogni anno. I metodi di previsione più vecchi si basavano su formule statistiche che faticavano a rappresentare i complessi schemi di consumo odierni. I più recenti modelli di deep learning gestiscono meglio comportamenti disordinati e non lineari ma possono essere difficili da addestrare. In particolare, le reti residuali profonde, che trasferiscono informazioni in avanti tramite percorsi di shortcut, sono diventate popolari per prevedere la domanda a breve termine perché possono apprendere pattern profondi senza diventare instabili.
Due reti, due climi, una domanda
Per capire come le scelte di addestramento influenzino questi modelli, gli autori studiano due sistemi elettrici reali. Uno si trova nel New England negli Stati Uniti, con forti variazioni stagionali dovute al riscaldamento in inverno e al raffrescamento in estate. L’altro è nella Malesia tropicale, dove le stagioni sono meno marcate e brevi scrosci di meteo e pioggia contano di più. Per il New England viene utilizzata una rete residuale che prende in input la domanda passata e la temperatura. Per la Malesia testano sia questo modello sia una variante che comprime molte misure meteorologiche in poche caratteristiche chiave combinate tramite una tecnica matematica, riducendo la ridondanza mantenendo la maggior parte dell’informazione climatica utile. 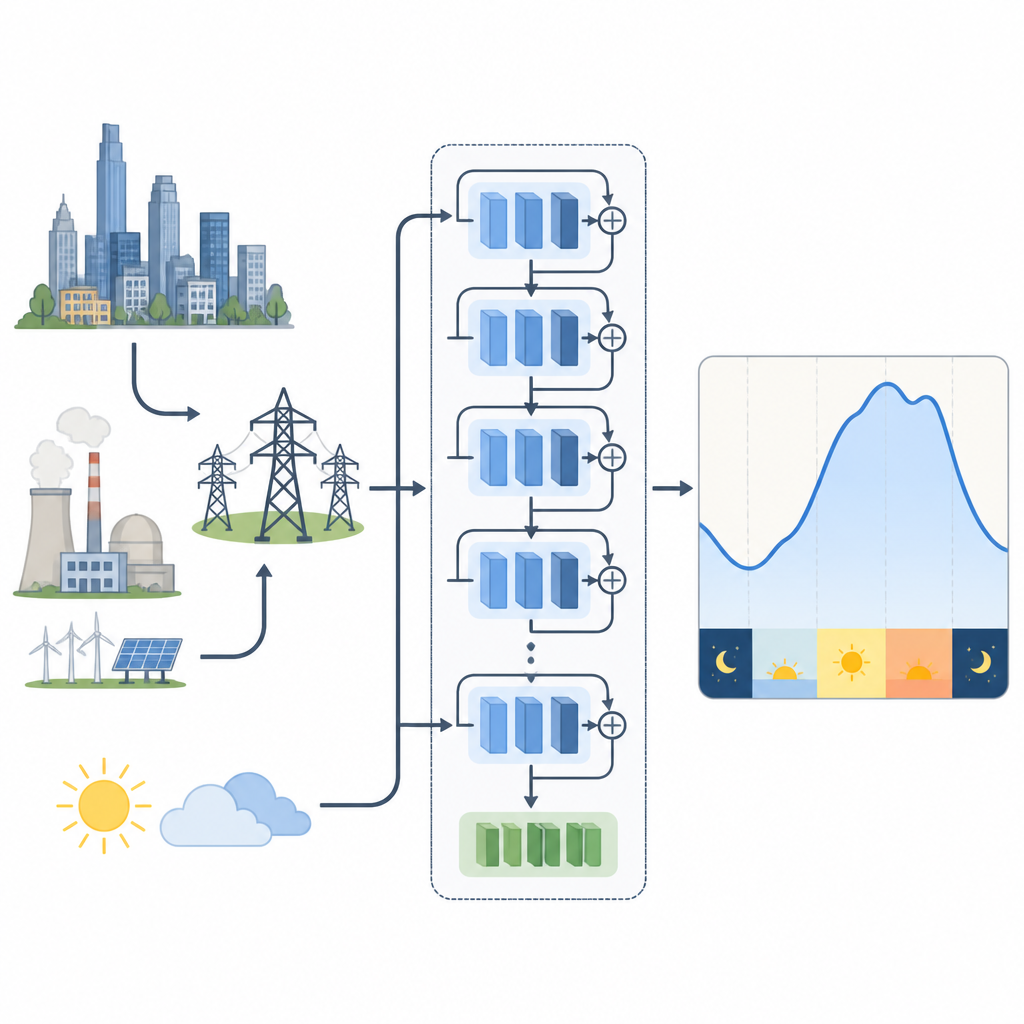
Cosa controlla davvero la dimensione del mini-batch
Addestrare un modello di deep learning significa regolare milioni di parametri interni per ridurre la differenza tra domanda prevista e reale. La dimensione del mini-batch è il numero di istanti temporali che il modello vede prima di ogni aggiornamento. Batch piccoli rendono gli aggiornamenti rumorosi e casuali, il che può aiutare il modello a esplorare ma anche rendere l’addestramento instabile. Batch molto grandi offrono aggiornamenti più lisci ma possono spingere il modello verso soluzioni che si adattano troppo ai dati di addestramento e generalizzano male. La domanda chiave è se esista un punto ottimale per queste reti residuali usate nella previsione del carico, e se questo punto sia lo stesso in climi diversi e con input meteorologici più ricchi.
Cosa hanno rivelato gli esperimenti
In un setting strettamente controllato in cui è stata variata solo la dimensione del mini-batch, gli autori hanno provato valori dal molto piccolo al molto grande. Sia nei sistemi del New England sia in quelli malesi hanno riscontrato che batch di dimensione media davano le migliori previsioni. In pratica, una dimensione di batch pari a 64 ha prodotto costantemente gli errori più bassi, con 32 appena dietro. Batch più piccoli hanno reso l’addestramento meno stabile e meno accurato, mentre batch più grandi hanno peggiorato le prestazioni in modo costante. Nel confronto tra le reti residuali e altri design popolari di deep learning basati su convoluzioni, unità ricorrenti, attention o ibridi di questi, i modelli residuali sono risultati migliori. La versione che combinava più misure meteorologiche in un sommario compatto ha avuto le migliori prestazioni nel caso tropicale. 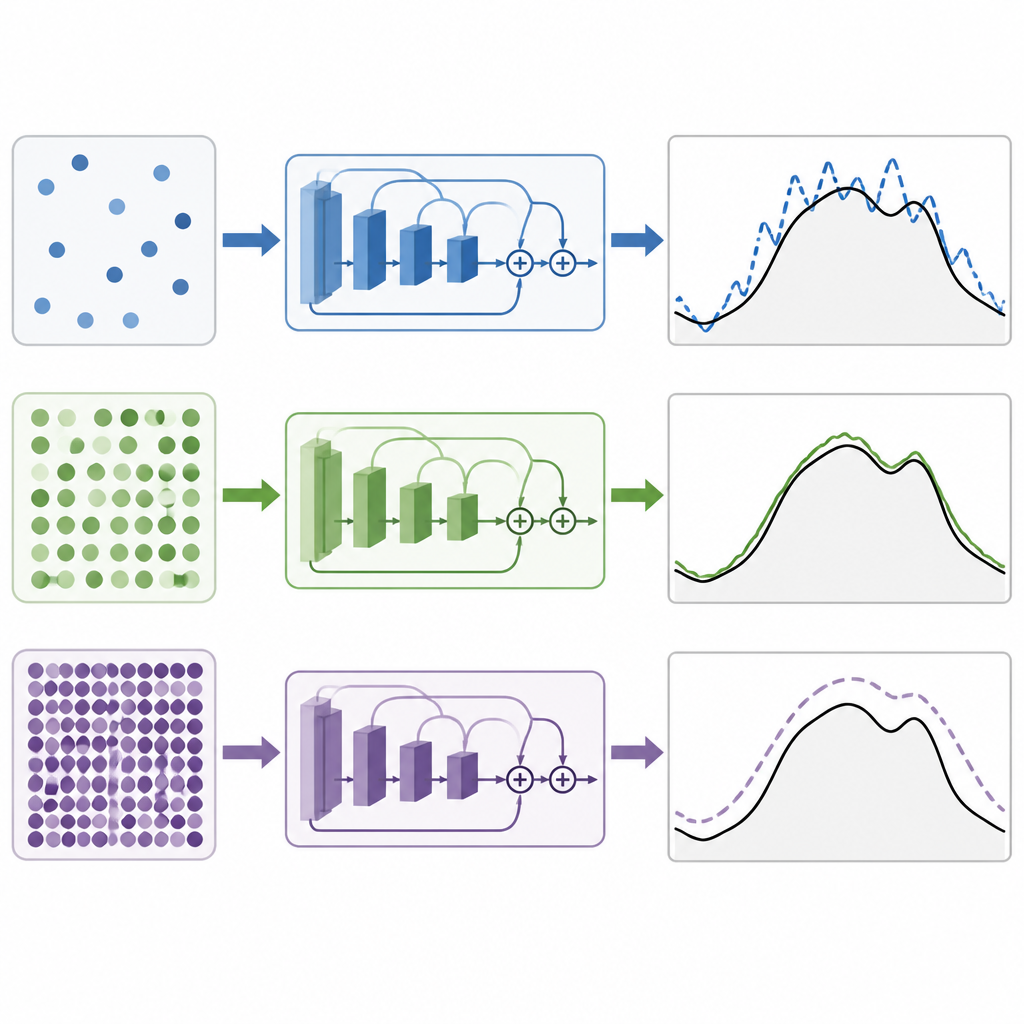
Come gli autori hanno verificato i risultati
Per assicurarsi che questi andamenti non fossero dovuti al caso, lo studio ha utilizzato una tecnica di campionamento chiamata bootstrapping. Questo metodo ricalcola ripetutamente le differenze di performance usando versioni rimescolate degli errori per stimare quanto sia probabile che i miglioramenti osservati si verifichino per caso. L’analisi ha mostrato che i guadagni ottenuti usando un batch di dimensione 64 invece di 32 erano statisticamente significativi, e che il modello con dati meteorologici compressi ha sistematicamente e in modo affidabile superato la rete residuale di base nelle stesse condizioni di addestramento.
Cosa significa per la pianificazione energetica
Per i non specialisti, il messaggio principale è che scelte di addestramento apparentemente minime all’interno dei modelli di intelligenza artificiale possono cambiare in modo sensibile quanto bene riusciamo a prevedere la domanda di elettricità del giorno successivo. Questo lavoro mostra che, per le reti residuali profonde usate nella previsione del carico a breve termine, dimensioni di batch di gamma media offrono un buon equilibrio tra stabilità e flessibilità nell’apprendimento, e che l’inserimento di informazioni meteorologiche ben compresse può ulteriormente affinare le previsioni. Insieme, queste indicazioni forniscono orientamenti pratici per utility e ingegneri che vogliono costruire reti più intelligenti ed efficienti senza dover riprogettare i loro modelli da zero.
Citazione: Liu, J., Ahmad, F.A., Samsudin, K. et al. Mini-batch size sensitivity in deep residual networks for short-term load forecasting: an empirical study. Sci Rep 16, 14996 (2026). https://doi.org/10.1038/s41598-026-45002-5
Parole chiave: previsione del carico a breve termine, reti residuali profonde, dimensione del mini-batch, domanda di elettricità, dati meteorologici