Clear Sky Science · pt
Identidades de sequência de nucleotídeos em trechos facilitam recombinação ilegítima entre genomas de muitas espécies diferentes
Padrões Ocultos no Código Genético da Vida
Todo ser vivo, de vírus e bactérias a trigo e baleias, armazena suas instruções genéticas em longas cadeias de quatro “letras” químicas. Este estudo faz uma pergunta enganadoramente simples: o que acontece quando você alinha o código genético de dois organismos muito diferentes e procura trechos coincidentes? A resposta revela-se surpreendentemente universal — e pode ajudar a explicar como os genomas se remodelam constantemente, alimentando a evolução e o surgimento de novos patógenos.
Trechos Curtos Correspondentes por Toda Parte
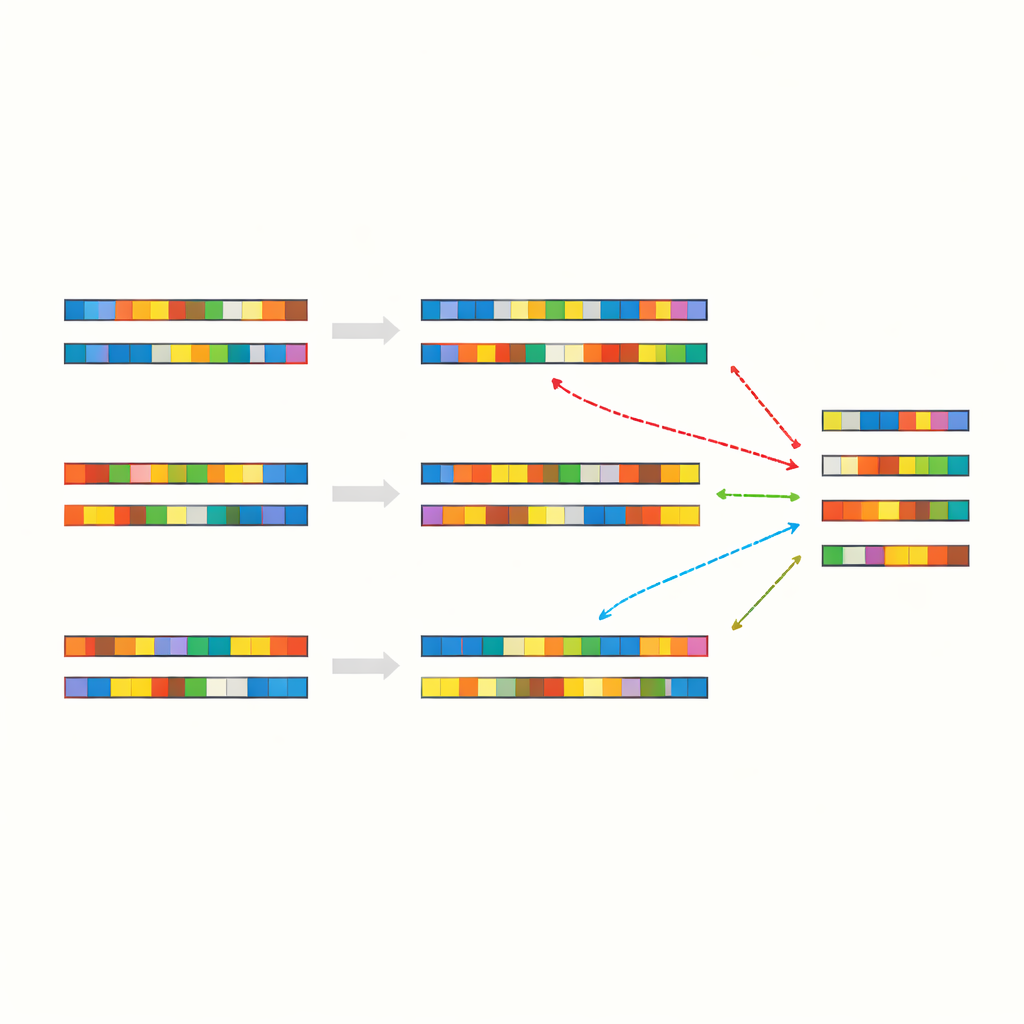
Os pesquisadores começaram comparando a sequência genética completa do vírus SARS-CoV-2 com uma variedade de outros genomas, incluindo cromossomos humanos, outros vírus, bactérias, plantas e animais. Em vez de buscar segmentos longos e obviamente relacionados, deram atenção a “patches” — curtas sequências de letras idênticas interrompidas por discordâncias e lacunas. Em mais de 90 comparações entre espécies, encontraram uma regularidade marcante: cerca de 40–50% das posições alinhadas eram correspondências exatas, quase sempre organizadas como esses trechos esparsos e em mosaico. Isso se manteve mesmo para organismos que não compartilham ancestralidade recente e desempenham papéis biológicos completamente diferentes.
Uma Aleatoriedade que Parece Igual
Para verificar se essas identidades em mosaico refletiam relações biológicas profundas ou algo mais básico, a equipe criou sequências de controle artificiais. Embaralharam genomas reais para manter a mesma composição geral de letras, mas desordenar sua ordem, e também geraram cadeias de DNA totalmente aleatórias com frequências de bases similares ou fixas. Quando alinharam essas sequências sintéticas entre si ou com genomas reais, observaram essencialmente o mesmo padrão: muitas correspondências exatas curtas espalhadas de forma irregular, com identidade global novamente agrupando-se em torno da faixa de meados dos 40%. Repetiram os testes com diferentes programas de alinhamento e parâmetros de pontuação, e o resultado praticamente não mudou. A conclusão é que o próprio alfabeto de quatro letras, combinado com tamanhos típicos de genoma e frequências de letras, praticamente garante esse padrão em mosaico.
Quando o Acaso se Torna um Sinal Útil
Correspondências em mosaico no DNA não são apenas uma curiosidade. Estudos anteriores, incluindo trabalhos do mesmo grupo, mostraram que padrões semelhantes frequentemente aparecem exatamente onde material genético estrangeiro se integra permanentemente ao genoma hospedeiro — por exemplo, quando certos vírus ou elementos móveis de DNA se inserem em células animais. Esses eventos dependem da “recombinação ilegítima”, termo guarda‑chuva para eventos de recortar-e-colar ou copiar-e-colar que não exigem trechos longos e perfeitamente coincidentes. O estudo atual fortalece a ideia de que as identidades em mosaico onipresentes produzidas por estatísticas básicas podem atuar como pontos de apoio convenientes para a maquinaria celular que une pedaços de material genético. Os autores até identificam regiões locais raras onde a identidade dispara muito acima do esperado ao acaso, assinalando‑as como potenciais pontos quentes onde essa recombinação é especialmente provável.
Moldando Genomas ao Longo da Evolução
Como esses padrões em mosaico surgem tanto em regiões codificantes quanto não codificantes, em elementos repetitivos e em espécies extremamente diferentes, os autores argumentam que se tratam de uma característica intrínseca do DNA, e não um efeito colateral de genes particulares. Ao longo do tempo evolutivo, esse fundo constante de curtas correspondências pode ter facilitado que genomas primitivos trocassem, rearranjassem ou inserissem novos trechos, muito antes do surgimento de enzimas altamente especializadas e mecanismos de cópia rigorosos. Em organismos modernos, incluindo vírus de RNA de rápida evolução como o SARS-CoV-2, a mesma estrutura estatística pode ainda facilitar trocas raras mas consequentes de material genético com outros vírus ou até com células hospedeiras, possivelmente dando origem a novos variantes com comportamento alterado.
O Que Isso Significa para o Panorama Geral
Para um não especialista, a mensagem central é que o código de quatro letras do DNA carrega dois tipos de informação ao mesmo tempo. Uma camada soletra genes e instruções regulatórias. A outra, mais sutil, é estatística: simplesmente por usar quatro letras com frequências enviesadas ao longo de longos trechos, os genomas inevitavelmente compartilham muitas correspondências curtas e dispersas. Este estudo sugere que a evolução aproveitou essa segunda camada, transformando padrões de aparência aleatória em pontos práticos de ancoragem para a reorganização genética. Em outras palavras, as mesmas regras simples que fazem sequências parecerem semelhante em mosaico pela árvore da vida podem também ajudar os sistemas vivos a reescrever e adaptar continuamente seus próprios projetos.
Citação: Weber, S., Ramirez, C.M. & Doerfler, W. Patch type nucleotide sequence identities between genomes from many different species facilitate illegitimate recombination. Sci Rep 16, 10524 (2026). https://doi.org/10.1038/s41598-026-44124-0
Palavras-chave: recombinação genômica, padrões de sequência de DNA, evolução genética, genética do SARS-CoV-2, plasticidade genômica