Clear Sky Science · es
Identidades de secuencias nucleotídicas en parches entre genomas de muchas especies facilitan la recombinación ilegítima
Patrones ocultos en el código genético de la vida
Cada ser vivo, desde virus y bacterias hasta trigo y ballenas, almacena sus instrucciones genéticas en largas cadenas formadas por cuatro “letras” químicas. Este estudio plantea una pregunta aparentemente simple: ¿qué ocurre cuando alineas el código genético de dos organismos muy diferentes y buscas tramos coincidentes? La respuesta resulta ser sorprendentemente universal y puede ayudar a explicar cómo los genomas se remodelan constantemente, impulsando la evolución y la aparición de nuevos patógenos.
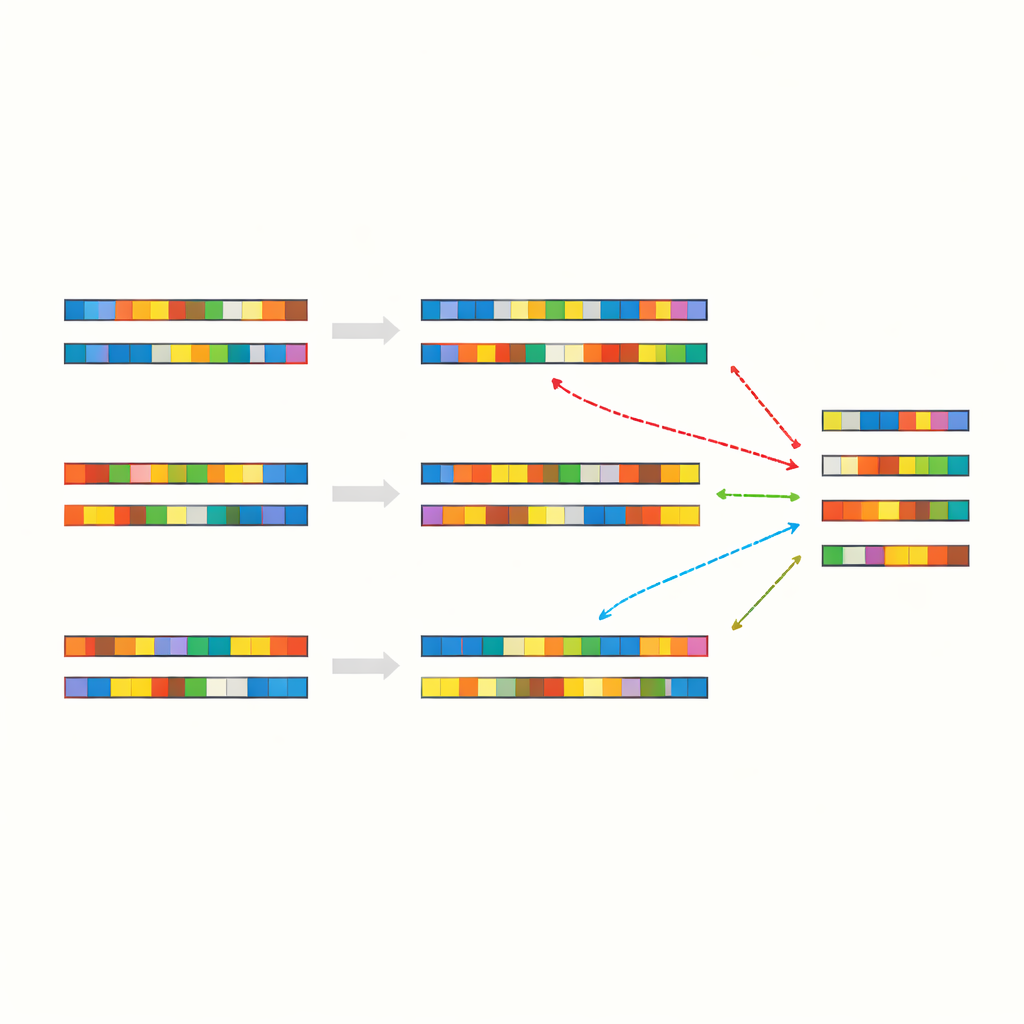
Pequeños tramos coincidentes por todas partes
Los investigadores empezaron comparando la secuencia genética completa del virus SARS-CoV-2 con una variedad de otros genomas, incluidos cromosomas humanos, otros virus, bacterias, plantas y animales. En lugar de buscar segmentos largos y obviamente relacionados, prestaron atención a “parches”: cortas sucesiones de letras idénticas interrumpidas por desajustes y huecos. En más de 90 comparaciones entre especies observaron una regularidad sorprendente: alrededor del 40–50% de las posiciones se alineaban como coincidencias exactas, casi siempre dispuestas como esos tramos parcheados y dispersos. Esto se mantenía incluso para organismos que no comparten una ascencia reciente y desempeñan funciones biológicas completamente diferentes.
Aleatoriedad que parece igual
Para comprobar si estas identidades parcheadas reflejaban relaciones biológicas profundas o algo más básico, el equipo creó secuencias de control artificiales. Barajaron genomas reales para conservar la misma composición global de letras pero alterar su orden, y también generaron cadenas de ADN completamente aleatorias con frecuencias de bases similares o fijas. Cuando alinearon estas secuencias sintéticas entre sí o con genomas reales, observaron esencialmente el mismo patrón: muchas coincidencias cortas exactas distribuidas de forma irregular, con una identidad global que de nuevo se agrupaba alrededor del rango medio del 40%. Repetieron las pruebas con distintos programas de alineamiento y configuraciones de puntuación, y el resultado apenas varió. La conclusión es que el propio alfabeto de cuatro letras, combinado con los tamaños típicos de genoma y las frecuencias de letras, casi garantiza este patrón parcheado.
Cuando la azarosa coincidencia se vuelve una señal útil
Las coincidencias parcheadas en el ADN no son solo una curiosidad. Estudios anteriores, incluido trabajo del mismo grupo, han mostrado que patrones similares suelen aparecer precisamente donde material genético extranjero queda insertado de forma permanente en un genoma huésped —por ejemplo, cuando ciertos virus o elementos móviles de ADN se integran en células animales. Estos eventos dependen de la “recombinación ilegítima”, un término general para procesos de cortar-y-pegar o copiar-y-pegar que no requieren tramos largos y perfectamente coincidentes. El estudio actual refuerza la idea de que las identidades parcheadas, siempre presentes por razones estadísticas básicas, pueden actuar como puntos de apoyo convenientes para la maquinaria celular que une fragmentos de material genético. Los autores incluso identifican regiones locales raras donde la identidad se dispara muy por encima de lo esperado al azar, marcándolas como posibles puntos calientes donde dicha recombinación es especialmente probable.
Moldeando los genomas a lo largo de la evolución
Dado que estos patrones de parches aparecen tanto en regiones codificantes como no codificantes, en elementos repetitivos y en especies muy distintas, los autores sostienen que son una característica intrínseca del ADN más que un efecto secundario de genes particulares. A lo largo del tiempo evolutivo, este fondo constante de cortos tramos coincidentes podría haber facilitado que los genomas primitivos intercambiaran, reorganizaran o insertaran nuevas piezas, mucho antes de que evolucionaran enzimas altamente especializadas y mecanismos de copiado estrictos. En organismos modernos, incluidos virus de ARN de rápida evolución como el SARS-CoV-2, esa misma estructura estadística puede aún favorecer intercambios raros pero significativos de material genético con otros virus o incluso con células hospedadoras, lo que potencialmente da lugar a nuevas variantes con comportamiento alterado.
Qué significa esto a grandes rasgos
Para un público no especializado, el mensaje clave es que el código de cuatro letras del ADN transporta dos tipos de información a la vez. Una capa especifica genes e instrucciones regulatorias. La otra, más sutil, es estadística: simplemente por usar cuatro letras con frecuencias sesgadas en tramos largos, los genomas comparten inevitablemente muchas coincidencias cortas dispersas. Este estudio sugiere que la evolución ha aprovechado esa segunda capa, convirtiendo patrones de apariencia aleatoria en puntos de acoplamiento prácticos para la reordenación genética. En otras palabras, las mismas reglas simples que hacen que las secuencias parezcan parcheadas y similares a lo largo del árbol de la vida pueden también ayudar a los sistemas vivos a reescribir y adaptar continuamente sus propios planos.
Cita: Weber, S., Ramirez, C.M. & Doerfler, W. Patch type nucleotide sequence identities between genomes from many different species facilitate illegitimate recombination. Sci Rep 16, 10524 (2026). https://doi.org/10.1038/s41598-026-44124-0
Palabras clave: recombinación genómica, patrones de secuencia del ADN, evolución genética, genética del SARS-CoV-2, plasticidad genómica