Clear Sky Science · fr
Des identités de séquences nucléotidiques en « éclats » entre génomes d’espèces très différentes facilitent la recombinaison illégitime
Motifs cachés dans le code génétique du vivant
Tous les êtres vivants, des virus et des bactéries au blé et aux baleines, stockent leurs instructions génétiques sous la forme de longues chaînes composées de quatre « lettres » chimiques. Cette étude pose une question apparemment simple : que se passe-t-il si l’on aligne le code génétique de deux organismes très différents et que l’on recherche des segments identiques ? La réponse se révèle étonnamment universelle — et pourrait aider à expliquer comment les génomes se réagencent en permanence, alimentant l’évolution et l’apparition de nouveaux agents pathogènes.
Courtes tranches identiques partout
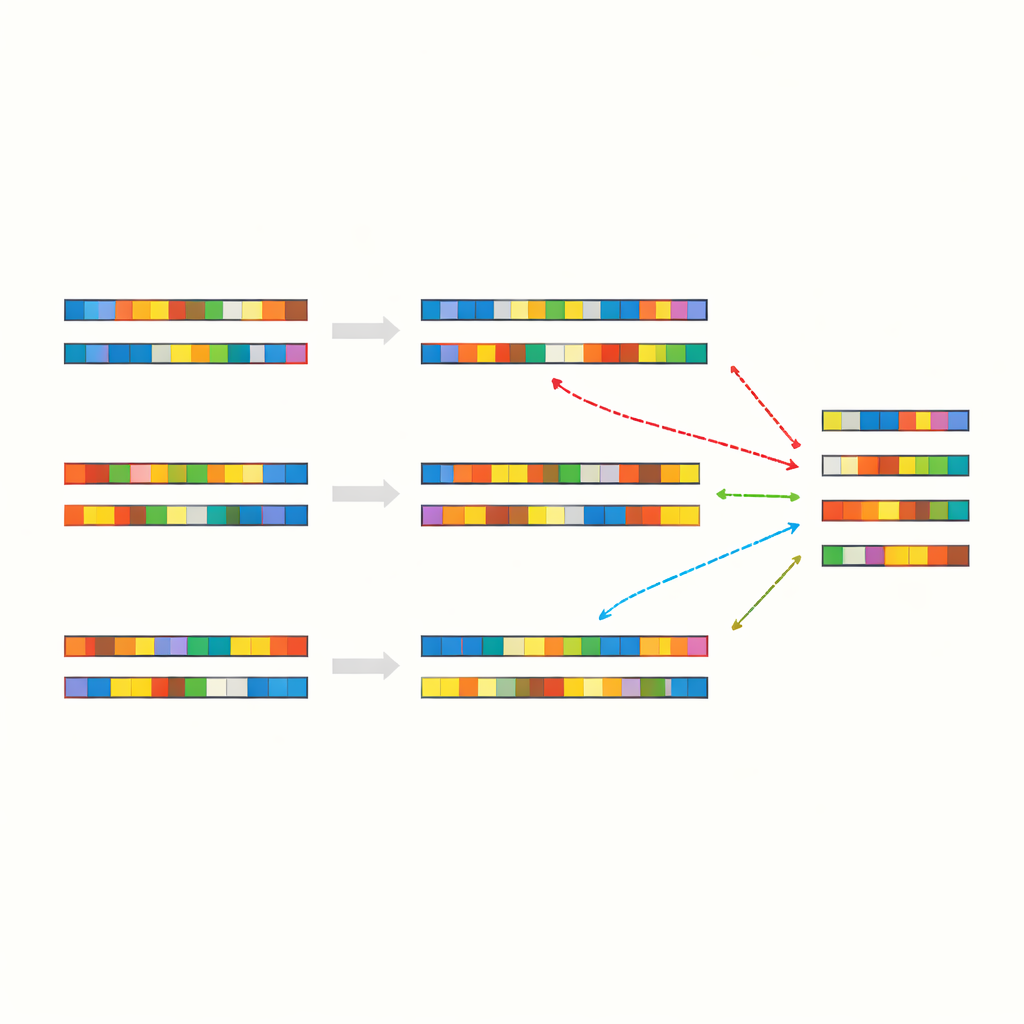
Les chercheurs ont commencé par comparer la séquence génétique complète du virus SARS-CoV-2 avec une variété d’autres génomes, incluant des chromosomes humains, d’autres virus, des bactéries, des plantes et des animaux. Plutôt que de rechercher de longs segments manifestement liés, ils ont porté leur attention sur des « patchs » : de courtes séries de lettres identiques interrompues par des divergences et des insertions/suppressions. Sur plus de 90 comparaisons inter-espèces, ils ont observé une régularité frappante : environ 40–50 % des positions s’alignaient en correspondances exactes, presque toujours organisées sous forme de ces tranches éparses et fragmentées. Cela se vérifiait même pour des organismes qui ne partagent pas d’ancêtre récent et remplissent des rôles biologiques complètement différents.
Un hasard qui se présente de la même façon
Pour déterminer si ces identités en patchs reflétaient des liens biologiques profonds ou quelque chose de plus fondamental, l’équipe a construit des séquences témoins artificielles. Ils ont mélangé de vrais génomes pour conserver la même composition en lettres tout en brouillant leur ordre, et ont aussi généré des chaînes d’ADN entièrement aléatoires avec des fréquences de bases similaires ou fixes. Lorsqu’ils ont aligné ces séquences synthétiques entre elles ou avec des génomes réels, ils ont observé essentiellement le même motif : de nombreuses courtes correspondances exactes réparties de façon irrégulière, avec une identité globale se situant à nouveau autour de la quarantaine de pourcents. Ils ont répété les tests avec différents programmes d’alignement et paramètres de score, et le résultat est à peine affecté. La conclusion est que l’alphabet à quatre lettres lui‑même, combiné aux tailles typiques des génomes et aux fréquences des bases, garantit presque cette structure en patchs.
Quand le hasard devient un signal utile
Les correspondances en patchs dans l’ADN ne sont pas qu’une curiosité. Des études antérieures, y compris des travaux du même groupe, ont montré que des motifs similaires apparaissent souvent précisément là où du matériel génétique étranger devient inséré de façon permanente dans un génome hôte — par exemple lorsque certains virus ou éléments mobiles d’ADN s’intègrent dans des cellules animales. Ces événements reposent sur la « recombinaison illégitime », un terme générique pour des opérations de couper-coller ou copier-coller qui ne requièrent pas de longues régions parfaitement appariées. L’étude actuelle renforce l’idée que les identités en patchs omniprésentes, produites par des statistiques élémentaires, peuvent servir de points d’ancrage commodes pour la machinerie cellulaire qui joint des fragments d’ADN. Les auteurs identifient même des régions locales rares où l’identité dépasse largement les attentes aléatoires, les signalant comme des points chauds potentiels où une telle recombinaison est particulièrement probable.
Façonner les génomes au fil de l’évolution
Parce que ces motifs en patchs apparaissent à la fois dans des régions codantes et non codantes, dans des éléments répétitifs et à travers des espèces très disparates, les auteurs soutiennent qu’il s’agit d’une caractéristique intrinsèque de l’ADN plutôt que d’un effet secondaire de gènes particuliers. Au cours de l’évolution, ce fond constant de courtes tranches correspondantées a pu faciliter les échanges, réarrangements ou insertions de nouveaux segments parmi les premiers génomes, bien avant l’apparition d’enzymes hautement spécialisées et de mécanismes de copie stricts. Chez les organismes modernes, y compris les virus à ARN à évolution rapide comme le SARS‑CoV‑2, cette même charpente statistique peut encore favoriser des échanges rares mais importants de matériel génétique avec d’autres virus ou même avec des cellules hôtes, conduisant potentiellement à l’émergence de nouveaux variants au comportement modifié.
Ce que cela signifie à grande échelle
Pour un non‑spécialiste, le message clé est que le code à quatre lettres de l’ADN porte deux types d’informations simultanément. Une couche dicte les gènes et les instructions régulatrices. L’autre, plus subtile, est statistique : simplement en utilisant quatre lettres avec des fréquences biaisées sur de longues étendues, les génomes partagent inévitablement de nombreuses courtes correspondances éparses. Cette étude suggère que l’évolution a exploité cette seconde couche, transformant des motifs d’apparence aléatoire en points d’accrochage pratiques pour le remaniement génétique. Autrement dit, les mêmes règles simples qui donnent aux séquences un air patchy à travers l’arbre du vivant peuvent aussi aider les systèmes vivants à réécrire et adapter continuellement leurs propres plans.
Citation: Weber, S., Ramirez, C.M. & Doerfler, W. Patch type nucleotide sequence identities between genomes from many different species facilitate illegitimate recombination. Sci Rep 16, 10524 (2026). https://doi.org/10.1038/s41598-026-44124-0
Mots-clés: recombinaison du génome, motifs de séquence d’ADN, évolution génétique, génétique du SARS-CoV-2, plasticité du génome