Clear Sky Science · pt
SamplingDesign: Projeto de RNA via otimização contínua com variáveis acopladas e amostragem Monte Carlo
Projetando RNA como uma nova ferramenta para a medicina
O RNA não é apenas um mensageiro passivo da informação genética; ele pode se dobrar em formas complexas que controlam genes, catalisam reações e até servem de base para vacinas. Se os cientistas conseguirem projetar de forma confiável sequências de RNA que se dobrem nas formas desejadas, poderão construir ferramentas moleculares customizadas para a medicina, desde vacinas mais inteligentes até interruptores genéticos programáveis. Este artigo apresenta o SamplingDesign, um novo método computacional que enfrenta a difícil tarefa do projeto de RNA ao combinar ideias da física, estatística e aprendizado de máquina moderno.
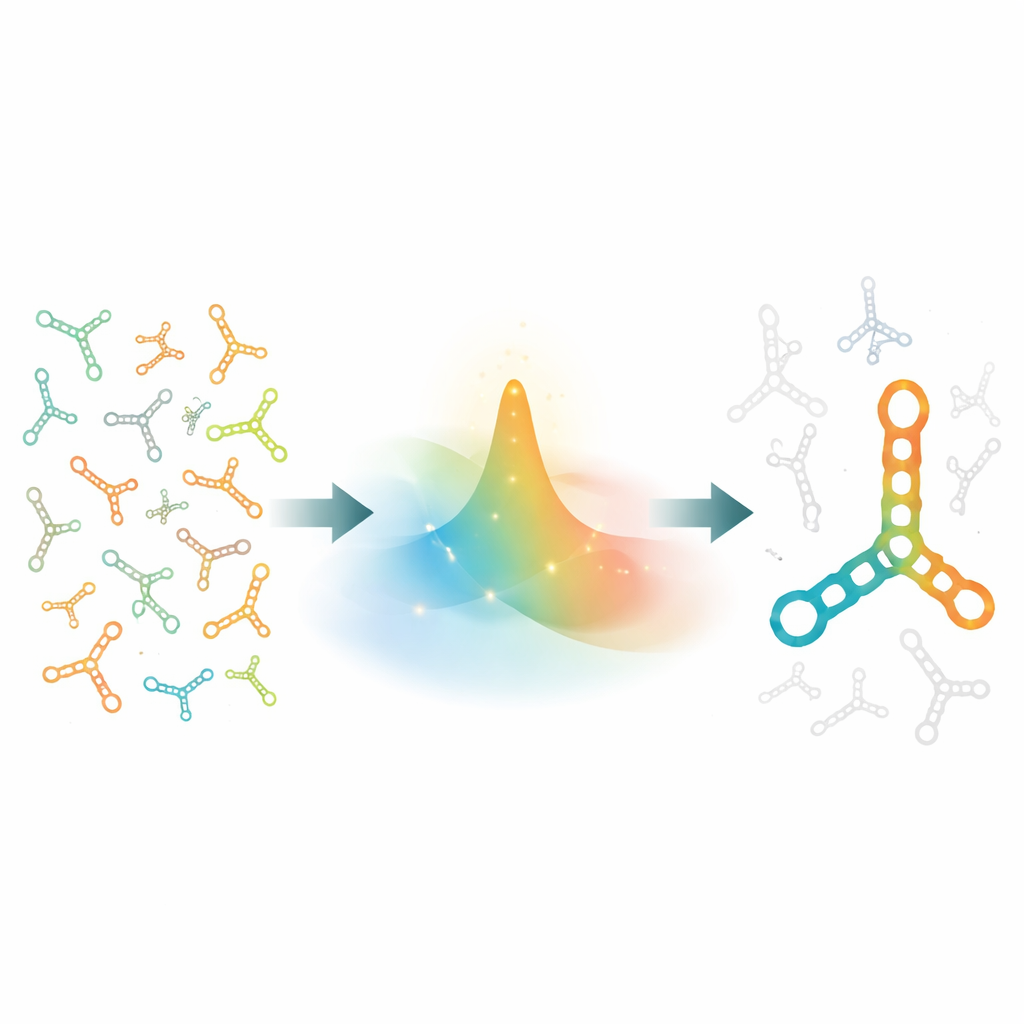
Por que projetar formas de RNA é tão difícil
Projetar RNA é como tentar escolher uma sequência de letras que, quando amassada, forme exatamente a figura de origami certa — e quase nenhuma outra. Para uma cadeia de comprimento n, existem 4n sequências possíveis, de modo que mesmo comprimentos moderados explodem em possibilidades astronômicas. Além disso, cada sequência pode se dobrar em um enorme número de formas alternativas que competem com a desejada. Um projeto útil não deve apenas favorecer a forma alvo como sua conformação de menor energia, mas também tornar as formas concorrentes muito menos prováveis, de modo que, entre muitas possibilidades, a estrutura correta prevaleça. Métodos de busca tradicionais mexem em uma ou poucas posições por vez e rapidamente se perdem nesse labirinto de opções, especialmente para RNAs longos e complexos.
Uma nova maneira de explorar possibilidades de uma só vez
Em vez de saltar de uma sequência candidata para a próxima, o SamplingDesign pensa em termos de uma nuvem inteira de possibilidades. Ele começa com uma distribuição de probabilidade espalhada por todas as sequências que são compatíveis com a forma alvo — isto é, sequências cujas posições pareadas podem formar pares de bases quimicamente reais. O método então usa otimização baseada em gradiente, um motor do aprendizado de máquina, para remodelar continuamente essa distribuição, de modo que sequências propensas a se dobrar bem na estrutura alvo ganhem probabilidade enquanto candidatos ruins perdem. De forma crucial, os autores não otimizam uma única pontuação para uma única sequência; eles otimizam o desempenho médio de todas as sequências sob a distribuição atual, o que incentiva uma exploração ampla no início e um ajuste fino mais tarde.
Capturando como as bases atuam em conjunto
Elemento-chave desta abordagem é uma maneira mais realista de representar como posições ao longo do RNA dependem umas das outras. Em vez de tratar cada nucleotídeo como uma escolha independente, o SamplingDesign agrupa certas posições em “variáveis acopladas”. Para cada par de bases, os dois parceiros compartilham uma pequena tabela de probabilidade conjunta sobre os seis tipos de pares permitidos quimicamente, excluindo automaticamente combinações inválidas. Acoplamentos semelhantes são usados para posições vizinhas que afetam a energia umas das outras, como grupos de mismatch e trimismatch ao redor de alças. Isso reduz o espaço de projeto para apenas sequências válidas e suaviza a otimização, porque as atualizações atuam diretamente em escolhas significativas de pares de bases e mismatches em vez de letras isoladas.
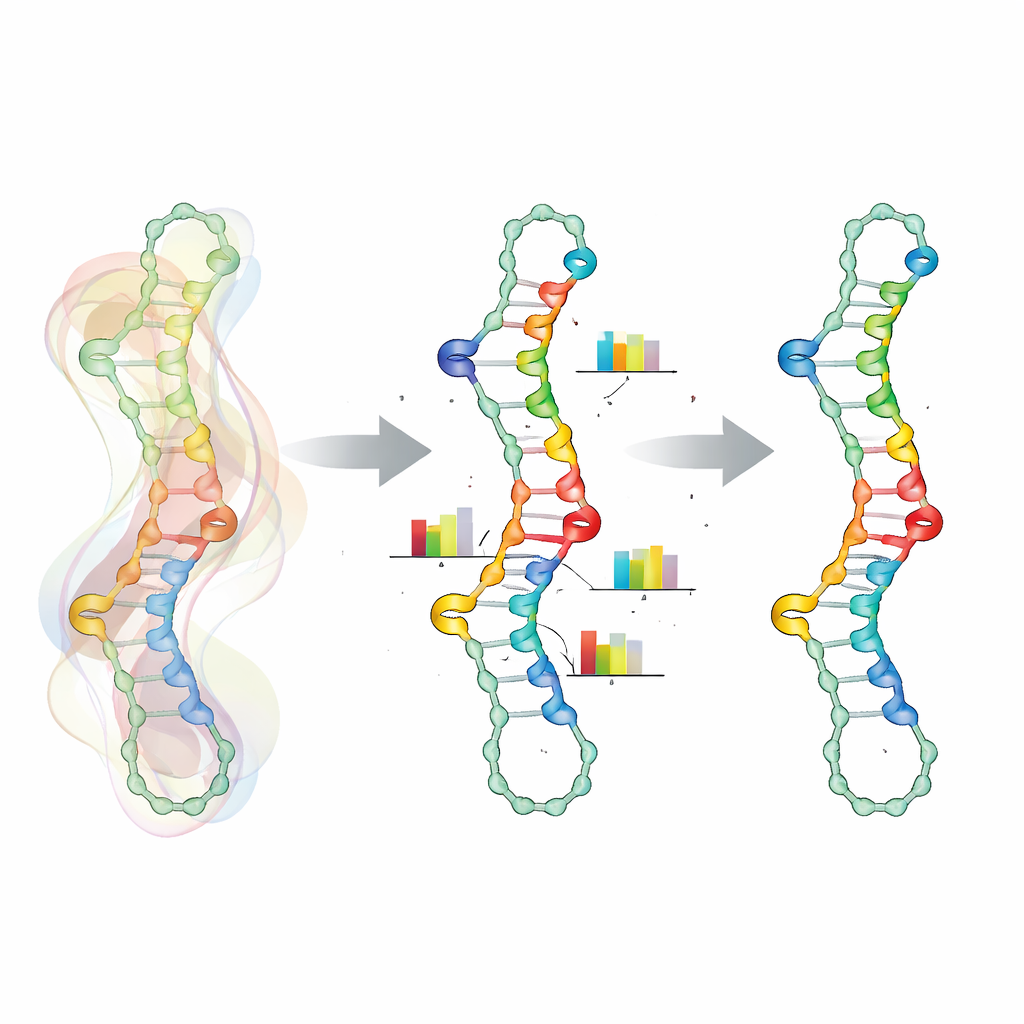
Deixando o acaso guiar escolhas mais inteligentes
Como é impossível calcular médias exatas sobre o enorme espaço de sequências e dobras, o SamplingDesign depende da amostragem Monte Carlo. Em cada passo, ele extrai um número manejável de sequências da distribuição atual, avalia quão bem cada uma se dobra segundo modelos termodinâmicos e usa essas amostras para estimar tanto o objetivo médio (como a probabilidade da estrutura alvo) quanto como ajustar a distribuição. Ao longo de muitas iterações, a massa de probabilidade se desloca em direção a sequências melhores e a distribuição se torna mais aguda. Em vez de simplesmente escolher a sequência mais provável no fim, o método mantém registro de todas as amostras observadas e seleciona aquela que realmente performa melhor segundo a métrica escolhida, obtendo os benefícios da exploração ampla sem perder o foco.
Superando ferramentas existentes em problemas difíceis
Os autores testaram o SamplingDesign em várias coleções padrão de “puzzles” de RNA, incluindo o amplamente usado benchmark Eterna100, que vai de alfinetes simples a formas longas e intrincadas de até 400 nucleotídeos. Em praticamente todas as medidas que consideram ensembles inteiros de estruturas — especialmente a probabilidade de Boltzmann da forma alvo e o “defeito do ensemble”, que monitora com que frequência nucleotídeos ficam mal dobrados — o SamplingDesign superou ferramentas de projeto de ponta que dependem de busca local ou de métodos contínuos mais simples. A vantagem foi mais marcante nos puzzles mais longos e difíceis, onde algoritmos tradicionais frequentemente ficam presos em soluções ruins enquanto o SamplingDesign continua a encontrar sequências cujas formas alvo se destacam claramente das concorrentes.
O que isso significa para futuras tecnologias de RNA
Em termos simples, este trabalho mostra que tratar o projeto de RNA como uma exploração guiada de muitas sequências de uma só vez, em vez de um jogo de edição passo a passo, pode produzir dobras mais limpas e confiáveis — especialmente para alvos grandes e desafiadores. Ao modelar como as bases interagem em pares e grupos, e ao usar amostragem para navegar por um espaço de busca de outro modo intratável, o SamplingDesign fornece um arcabouço flexível que pode otimizar diferentes objetivos de projeto. Os autores sugerem que ele poderia ser estendido para adaptar RNAs mensageiros para vacinas ou terapias e incorporar restrições experimentais. À medida que um desenho computacional melhorado encontra testes em laboratório, tais métodos poderiam ajudar a transformar plantas abstratas de RNA em ferramentas moleculares práticas para a medicina.
Citação: Tang, W.Y., Dai, N., Zhou, T. et al. SamplingDesign: RNA design via continuous optimization with coupled variables and Monte-Carlo sampling. Nat Commun 17, 2950 (2026). https://doi.org/10.1038/s41467-025-67901-3
Palavras-chave: Projeto de RNA, dobramento inverso, amostragem Monte Carlo, otimização contínua, terapêuticas de mRNA