Clear Sky Science · it
SamplingDesign: progettazione di RNA tramite ottimizzazione continua con variabili accoppiate e campionamento Monte Carlo
Progettare l’RNA come nuovo strumento per la medicina
L’RNA non è solo un messaggero passivo dell’informazione genetica; può ripiegarsi in forme complesse che controllano geni, catalizzano reazioni e persino costituire la base dei vaccini. Se gli scienziati potessero progettare in modo affidabile sequenze di RNA che si ripiegano nelle forme volute, potrebbero costruire strumenti molecolari su misura per la medicina, da vaccini più intelligenti a interruttori genetici programmabili. Questo articolo presenta SamplingDesign, un nuovo metodo computazionale che affronta la difficile sfida della progettazione dell’RNA combinando idee dalla fisica, dalla statistica e dall’apprendimento automatico moderno.
Perché progettare le forme dell’RNA è così difficile
Progettare RNA è come cercare una sequenza di lettere tale che, quando viene accartocciata, formi esattamente la figura di origami desiderata—e quasi nient’altro. Per una catena di lunghezza n esistono 4n sequenze possibili, quindi anche lunghezze moderate esplodono in possibilità astronomiche. Inoltre, ogni sequenza può ripiegarsi in un numero enorme di forme alternative che competono con quella desiderata. Un progetto utile deve non solo favorire la forma obiettivo come stato a energia più bassa, ma anche rendere le strutture concorrenti molto meno probabili, in modo che, tra la moltitudine di possibilità, la struttura corretta domini. I metodi di ricerca tradizionali modificano una o poche posizioni alla volta e si impantanano rapidamente in questo labirinto di opzioni, soprattutto per RNA lunghi e complessi.
Un nuovo modo di esplorare le possibilità tutte insieme
Anziché passare da una sequenza candidata alla successiva, SamplingDesign ragiona in termini di un intero insieme probabilistico di possibilità. Parte da una distribuzione di probabilità che copre tutte le sequenze compatibili con la struttura obiettivo—cioè sequenze i cui posizionamenti accoppiati possono formare vere coppie di basi chimiche. Il metodo poi utilizza l’ottimizzazione basata sul gradiente, uno strumento consolidato dell’apprendimento automatico, per rimodellare progressivamente questa distribuzione in modo che le sequenze con maggiore probabilità di ripiegarsi correttamente acquisiscano peso mentre i candidati scadenti lo perdano. Fondamentalmente, gli autori non ottimizzano un singolo punteggio per una singola sequenza; ottimizzano la prestazione media di tutte le sequenze secondo la distribuzione corrente, il che favorisce una esplorazione ampia nelle fasi iniziali e una rifinitura nelle fasi successive.
Cogliere come le basi lavorano insieme
Elemento chiave di questo approccio è un modo più realistico di rappresentare le dipendenze tra posizioni lungo l’RNA. Invece di trattare ogni nucleotide come una scelta indipendente, SamplingDesign raggruppa certe posizioni in “variabili accoppiate”. Per ogni coppia di basi, i due partner condividono una piccola tabella di probabilità congiunta sulle sei tipologie di coppie chimicamente ammesse, escludendo automaticamente le combinazioni invalide. Un accoppiamento simile è usato per posizioni vicine che influenzano l’energia reciproca, come i gruppi di mismatch e trimismatch attorno alle loop. Questo riduce lo spazio di progettazione alle sole sequenze valide e rende l’ottimizzazione più fluida, perché gli aggiornamenti agiscono direttamente su scelte significative relative a coppie di basi e mismatch invece che su singole lettere isolate.
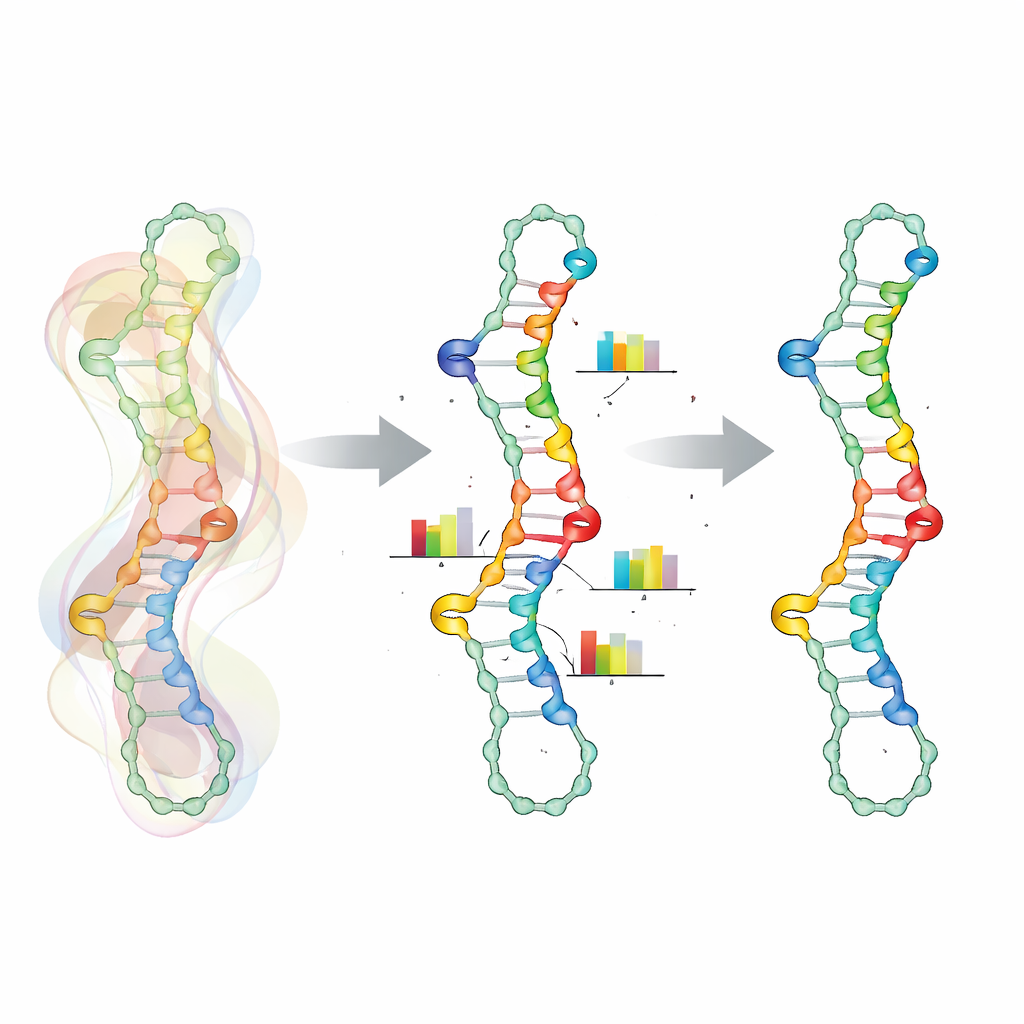
Lasciare che la casualità guidi scelte più intelligenti
Poiché è impossibile calcolare esattamente le medie sul vasto spazio di sequenze e ripiegamenti, SamplingDesign si affida al campionamento Monte Carlo. A ogni passo estrae un numero gestibile di sequenze dalla distribuzione corrente, valuta quanto ciascuna si ripiega secondo modelli termodinamici e usa questi campioni per stimare sia l’obiettivo medio (ad esempio la probabilità della struttura obiettivo) sia come aggiustare la distribuzione. Nel corso di molte iterazioni, la massa di probabilità si sposta verso sequenze migliori e la distribuzione diventa più netta. Invece di scegliere semplicemente la singola sequenza più probabile alla fine, il metodo conserva tutti i campioni osservati e seleziona quella che realmente rende meglio secondo la metrica scelta, ottenendo i benefici di una vasta esplorazione senza perdere il focus.
Prestazioni superiori agli strumenti esistenti su enigmi difficili
Gli autori hanno testato SamplingDesign su diverse collezioni standard di “puzzle” di RNA, incluso il noto benchmark Eterna100, che spazia da semplici forcine a forme lunghe e intricate fino a 400 nucleotidi. Su quasi tutte le misure che valutano intere insiemi di strutture—in particolare la probabilità di Boltzmann della struttura obiettivo e il “difetto di ensemble”, che monitora quanto spesso i nucleotidi sono mal ripiegati—SamplingDesign ha superato gli strumenti di progettazione allo stato dell’arte che si basano su ricerca locale o su metodi continui più semplici. Il vantaggio è stato più evidente per i puzzle più lunghi e difficili, dove gli algoritmi tradizionali spesso restano bloccati in soluzioni scadenti mentre SamplingDesign continua a trovare sequenze la cui struttura obiettivo si distingue chiaramente dalle concorrenti.
Cosa significa per le future tecnologie basate sull’RNA
In termini chiari, questo lavoro dimostra che trattare la progettazione dell’RNA come un’esplorazione guidata di molte sequenze contemporaneamente, piuttosto che come un gioco di modifica passo-passo, può produrre ripiegamenti più netti e più affidabili—soprattutto per obiettivi grandi e impegnativi. Modellando come le basi interagiscono in coppie e in gruppi, e usando il campionamento per navigare in un panorama altrimenti intrattabile, SamplingDesign fornisce un quadro flessibile che può ottimizzare diversi obiettivi di progettazione. Gli autori suggeriscono che potrebbe essere esteso per personalizzare RNA messaggeri per vaccini o terapie e per incorporare vincoli sperimentali. Con un miglioramento della progettazione computazionale che incontra la sperimentazione di laboratorio, tali metodi potrebbero aiutare a trasformare progetti astratti di RNA in strumenti molecolari pratici per la medicina.
Citazione: Tang, W.Y., Dai, N., Zhou, T. et al. SamplingDesign: RNA design via continuous optimization with coupled variables and Monte-Carlo sampling. Nat Commun 17, 2950 (2026). https://doi.org/10.1038/s41467-025-67901-3
Parole chiave: progettazione RNA, ripiegamento inverso, campionamento Monte Carlo, ottimizzazione continua, terapeutici mRNA