Clear Sky Science · de
SamplingDesign: RNA-Design durch kontinuierliche Optimierung mit gekoppelten Variablen und Monte-Carlo-Sampling
RNA entwerfen als neues Werkzeug der Medizin
RNA ist nicht nur ein passiver Bote genetischer Information; sie kann sich in komplexe Formen falten, die Gene steuern, Reaktionen katalysieren und sogar als Grundlage von Impfstoffen dienen. Wenn Forschende zuverlässig RNA-Sequenzen entwerfen könnten, die in vorgegebene Formen falten, ließen sich maßgeschneiderte molekulare Werkzeuge für die Medizin bauen — von intelligenteren Impfstoffen bis zu programmierbaren genetischen Schaltern. Diese Arbeit stellt SamplingDesign vor, eine neue rechnerische Methode, die die enorme Herausforderung des RNA-Designs angeht, indem sie Ideen aus Physik, Statistik und moderner maschineller Lernverfahren verknüpft.
Warum das Entwerfen von RNA-Formen so schwierig ist
RNA-Design ist wie der Versuch, eine Buchstabenfolge so zu wählen, dass sie, einmal zusammengeknüllt, genau die richtige Origami-Figur bildet — und kaum etwas anderes. Für eine Kette der Länge n gibt es 4n mögliche Sequenzen, sodass selbst mittlere Längen in astronomische Möglichkeiten explodieren. Darüber hinaus kann jede Sequenz in eine enorme Anzahl alternativer Formen falten, die mit der gewünschten Struktur konkurrieren. Ein brauchbares Design muss nicht nur die Zielstruktur als energieärmste Form begünstigen, sondern konkurrierende Formen deutlich unwahrscheinlicher machen, sodass in der Menge der Möglichkeiten die korrekte Struktur dominiert. Traditionelle Suchmethoden verändern eine oder wenige Positionen zugleich und geraten schnell in dieses Optionslabyrinth, insbesondere bei langen und komplexen RNAs.
Eine neue Art, Möglichkeiten gleichzeitig zu erkunden
Anstatt von einer Kandidatensequenz zur nächsten zu hüpfen, denkt SamplingDesign in Begriffen einer ganzen Wolke von Möglichkeiten. Es beginnt mit einer Wahrscheinlichkeitsverteilung, die sich über alle Sequenzen erstreckt, die mit der Zielstruktur kompatibel sind — also Sequenzen, deren gepaarten Positionen tatsächlich chemische Basenpaare bilden können. Die Methode verwendet dann gradientenbasierte Optimierung, ein Standardwerkzeug des maschinellen Lernens, um diese Verteilung schrittweise so zu formen, dass Sequenzen, die wahrscheinlich gut in die Zielstruktur falten, an Wahrscheinlichkeit gewinnen, während schlechte Kandidaten verlieren. Entscheidend ist, dass die Autorinnen und Autoren nicht eine einzelne Punktbewertung für eine einzelne Sequenz optimieren; sie optimieren die durchschnittliche Leistung aller Sequenzen unter der aktuellen Verteilung, was früh weite Exploration und späteres Feintuning begünstigt.
Abbilden, wie Basen zusammenwirken
Wesentlich für diesen Ansatz ist eine realistischere Darstellung der Abhängigkeiten zwischen Positionen entlang der RNA. Anstatt jede Nukleotidposition als unabhängige Wahl zu behandeln, fasst SamplingDesign bestimmte Positionen zu „gekoppelten Variablen“ zusammen. Für jedes Basenpaar teilen sich die beiden Partner eine kleine gemeinsame Wahrscheinlichkeitsmatrix über die sechs chemisch erlaubten Paartypen, wodurch automatisch ungültige Kombinationen ausgeschlossen werden. Ähnliche Kopplungen werden für benachbarte Positionen verwendet, die gegenseitig ihre Energie beeinflussen, etwa Mismatch- und Trimismatch-Gruppen um Schleifen herum. Das verkleinert den Entwurfsraum auf nur gültige Sequenzen und macht die Optimierung glatter, weil Aktualisierungen direkt sinnvolle Basenpaar- und Mismatch-Entscheidungen betreffen statt isolierte Buchstaben.
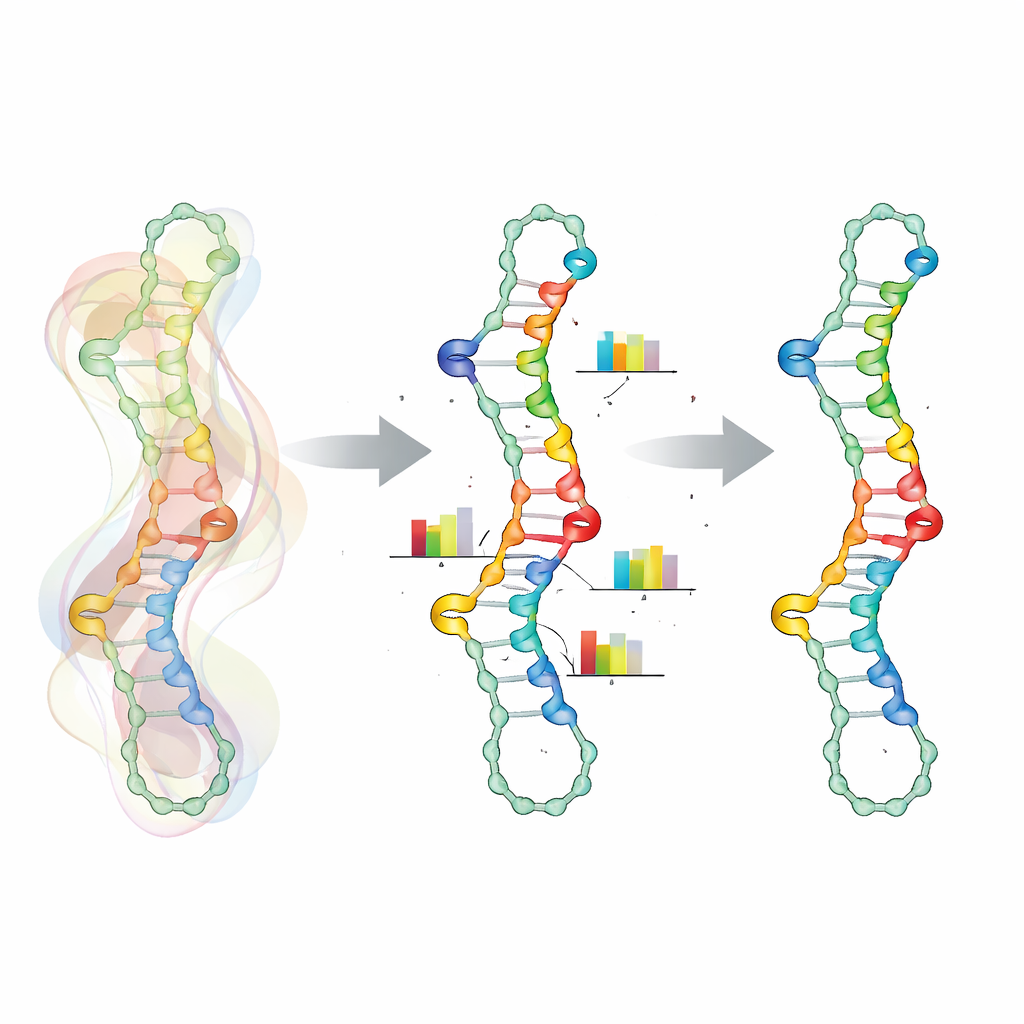
Zufall als Leitfaden für klügere Entscheidungen
Da es unmöglich ist, exakte Mittelwerte über den riesigen Raum von Sequenzen und Faltungen zu berechnen, stützt sich SamplingDesign auf Monte-Carlo-Sampling. In jedem Schritt zieht es eine überschaubare Anzahl von Sequenzen aus der aktuellen Verteilung, bewertet, wie gut jede gemäß thermodynamischer Modelle faltet, und nutzt diese Stichproben, um sowohl die durchschnittliche Zielgröße (etwa die Wahrscheinlichkeit der Zielstruktur) als auch die Richtung zur Anpassung der Verteilung zu schätzen. Über viele Iterationen verschiebt sich die Wahrscheinlichkeitsmasse zu besseren Sequenzen und die Verteilung wird schärfer. Anstatt am Ende einfach die eine wahrscheinlichste Sequenz zu nehmen, behält die Methode alle gesehenen Stichproben im Blick und wählt diejenige aus, die nach der gewählten Bewertungsmetrik tatsächlich am besten abschneidet — so profitiert sie von breiter Exploration, ohne die Zielgerichtetheit zu verlieren.
Beste Leistung bei schwierigen Rätseln
Die Autorinnen und Autoren testeten SamplingDesign an mehreren Standardkollektionen von RNA-„Rätseln“, darunter das weit verbreitete Eterna100-Benchmark, das von einfachen Haarnadeln bis zu langen, komplexen Formen mit bis zu 400 Nukleotiden reicht. Über fast alle Maße, die Ensembles von Strukturen betrachten — insbesondere die Boltzmann-Wahrscheinlichkeit der Zielstruktur und den „Ensemble-Defekt“, der nachverfolgt, wie oft Nukleotide falsch gefaltet sind — übertraf SamplingDesign state-of-the-art-Designwerkzeuge, die auf lokalen Suchverfahren oder einfacheren kontinuierlichen Methoden beruhen. Der Vorteil war am auffälligsten bei den längsten und härtesten Rätseln, wo traditionelle Algorithmen oft in schlechten Lösungen stecken bleiben, während SamplingDesign weiterhin Sequenzen findet, deren Zielstrukturen sich klar von Konkurrenzstrukturen abheben.
Was das für künftige RNA-Technologien bedeutet
Einfach ausgedrückt zeigt diese Arbeit, dass das Betrachten des RNA-Designs als geführte Exploration vieler Sequenzen gleichzeitig — statt als schrittweises Editierspiel — sauberere, verlässlichere Faltungen erzeugen kann, insbesondere für große und herausfordernde Ziele. Indem sie modelliert, wie Basen paarweise und in Gruppen interagieren, und Sampling nutzt, um eine sonst unüberschaubare Landschaft zu durchqueren, bietet SamplingDesign einen flexiblen Rahmen, der verschiedene Designziele optimieren kann. Die Autorinnen und Autoren schlagen vor, dass sich die Methode erweitern lässt, um Boten-RNAs für Impfstoffe oder Therapien maßzuschneidern und experimentelle Einschränkungen zu integrieren. Wenn verbesserte rechnerische Gestaltung auf Labortests trifft, könnten solche Methoden abstrakte RNA-Entwürfe in praktikable molekulare Werkzeuge für die Medizin verwandeln.
Zitation: Tang, W.Y., Dai, N., Zhou, T. et al. SamplingDesign: RNA design via continuous optimization with coupled variables and Monte-Carlo sampling. Nat Commun 17, 2950 (2026). https://doi.org/10.1038/s41467-025-67901-3
Schlüsselwörter: RNA-Design, inverse Faltung, Monte-Carlo-Sampling, kontinuierliche Optimierung, mRNA-Therapeutika