Clear Sky Science · nl
SamplingDesign: RNA-ontwerp via continue optimalisatie met gekoppelde variabelen en Monte-Carlo-sampling
RNA ontwerpen als nieuw instrument voor de geneeskunde
RNA is niet alleen een passieve boodschapper van genetische informatie; het kan in ingewikkelde vormen vouwen die genen aansturen, reacties katalyseren en zelfs als basis voor vaccins dienen. Als onderzoekers betrouwbaar RNA-sequenties konden ontwerpen die in vooraf gekozen structuren vouwen, zouden ze op maat gemaakte moleculaire gereedschappen voor de geneeskunde kunnen bouwen — van slimmer ontworpen vaccins tot programmeerbare genetische schakelaars. Dit artikel introduceert SamplingDesign, een nieuwe computationele methode die de enorme moeilijkheid van RNA-ontwerp aanpakt door ideeën uit de natuurkunde, statistiek en moderne machine learning te combineren.
Waarom het ontwerpen van RNA-vormen zo lastig is
RNA ontwerpen is alsof je een reeks letters moet kiezen zodat die, wanneer hij wordt opgevouwen, precies de juiste origamivorm oplevert — en bijna geen andere. Voor een streng van lengte n zijn er 4n mogelijke sequenties, waardoor zelfs matige lengtes in astronomische aantallen exploderen. Daarbij kan elke sequentie in een enorme hoeveelheid alternatieve structuren vouwen die concurreren met de gewenste. Een bruikbaar ontwerp moet niet alleen de doelstructuur als laagste-energietoestand bevoordelen, maar ook concurrerende structuren veel onwaarschijnlijker maken, zodat in een zee van mogelijkheden de juiste structuur domineert. Traditionele zoekmethoden passen één of enkele posities per keer aan en raken snel vast in dit doolhof, vooral voor lange en complexe RNA's.
Een nieuwe manier om tegelijkertijd mogelijkheden te verkennen
In plaats van van het ene kandidaat-sequentie naar het volgende te lopen, denkt SamplingDesign in termen van een hele wolk van mogelijkheden. Het begint met een kansverdeling die over alle sequenties is verspreid die compatibel zijn met de doelstructuur — dat wil zeggen sequenties waarvan de gepaarde posities echte chemische basenparen kunnen vormen. De methode gebruikt vervolgens gradient-gebaseerde optimalisatie, een werkpaard uit de machine learning, om deze verdeling geleidelijk te hervormen zodat sequenties die waarschijnlijk goed in de doelstructuur vouwen meer kans krijgen en slechte kandidaten kans verliezen. Cruciaal is dat de auteurs niet één score voor één sequentie optimaliseren; ze optimaliseren de gemiddelde prestatie van alle sequenties onder de huidige verdeling, wat vroege brede verkenning en latere verfijning aanmoedigt.
Vastleggen hoe basen samenwerken
Kern van deze aanpak is een realistischer manier om te representeren hoe posities langs het RNA van elkaar afhankelijk zijn. In plaats van elke nucleotide als onafhankelijke keuze te behandelen, bundelt SamplingDesign bepaalde posities in “gekoppelde variabelen.” Voor elk basenpaar delen de twee partners een kleine gezamenlijke kansentabel over de zes chemisch toegestane paartypes, waarmee ongeldige combinaties automatisch worden uitgesloten. Vergelijkbare koppeling wordt gebruikt voor aangrenzende posities die elkaars energie beïnvloeden, zoals mismatch- en trimismatchgroepen rond lussen. Dit verkleint de ontwerpruimte tot alleen geldige sequenties en maakt de optimalisatie soepeler, omdat updates direct betrekking hebben op betekenisvolle basenpaar- en mismatchkeuzes in plaats van op geïsoleerde letters.
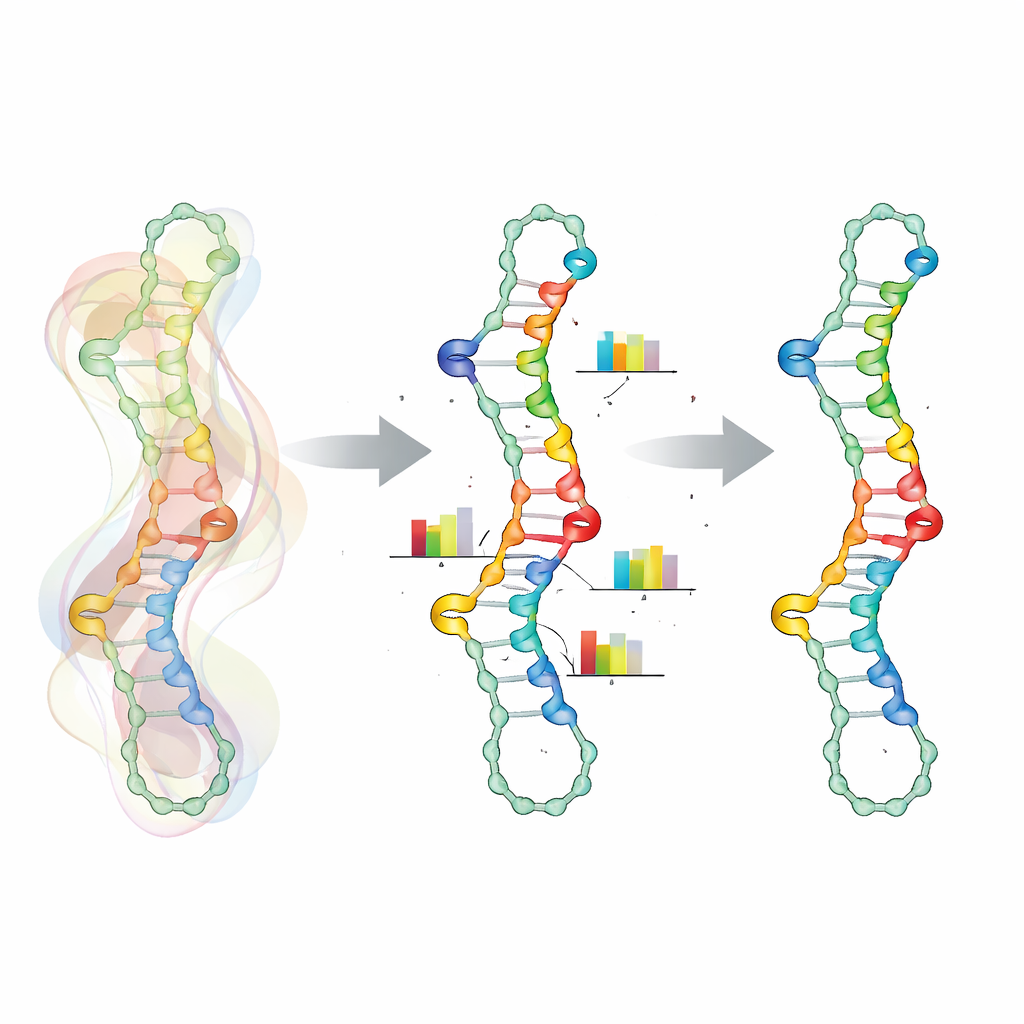
Toeval gebruiken om slimmere keuzes te sturen
Aangezien het onmogelijk is exacte gemiddelden uit te rekenen over de enorme ruimte van sequenties en vouwingen, vertrouwt SamplingDesign op Monte Carlo-sampling. Bij elke stap trekt het een beheersbaar aantal sequenties uit de huidige verdeling, evalueert hoe goed elk vouwt volgens thermodynamische modellen, en gebruikt deze monsters om zowel de gemiddelde doelstelling (zoals de kans op de doelstructuur) als hoe de verdeling moet worden aangepast te schatten. Over veel iteraties verschuift de kansmassa naar betere sequenties en wordt de verdeling scherper. In plaats van uiteindelijk simpelweg de meest waarschijnlijke enkele sequentie te nemen, houdt de methode alle waargenomen monsters bij en kiest degene die volgens de gekozen maatstaf werkelijk het beste presteert, waarmee de voordelen van brede verkenning behouden blijven zonder de focus te verliezen.
Betere prestaties dan bestaande tools op lastige puzzels
De auteurs testten SamplingDesign op verschillende standaardverzamelingen RNA-“puzzels”, waaronder de veelgebruikte Eterna100-benchmark, die varieert van eenvoudige haarspelden tot lange, ingewikkelde vormen van tot 400 nucleotiden. Over vrijwel alle maten die naar hele ensembles van structuren kijken — in het bijzonder de Boltzmann-kans van de doelstructuur en de “ensemble defect”, die bijhoudt hoe vaak nucleotiden verkeerd gevouwen zijn — versloeg SamplingDesign state-of-the-art ontwerp-tools die op lokale zoekmethoden of eenvoudigere continue methoden vertrouwen. Het voordeel was het duidelijkst bij de langste en moeilijkste puzzels, waar traditionele algoritmen vaak in slechte oplossingen vastlopen terwijl SamplingDesign door blijft vinden naar sequenties waarvan de doelstructuren duidelijk boven de concurrentie uitsteken.
Wat dit betekent voor toekomstige RNA-technologieën
Kort gezegd laat dit werk zien dat het behandelen van RNA-ontwerp als een geleide verkenning van veel sequenties tegelijk, in plaats van een stap-voor-stap bewerkingsspel, schonere en betrouwbaarder vouwpatronen kan opleveren — vooral voor grote en uitdagende doelen. Door te modelleren hoe basen in paren en groepen met elkaar interacteren en door sampling te gebruiken om een anderszins onhandelbaar landschap te navigeren, biedt SamplingDesign een flexibel kader dat verschillende ontwerpsdoelen kan optimaliseren. De auteurs suggereren dat het kan worden uitgebreid om boodschapper-RNA's voor vaccins of therapieën op maat te maken en om experimentele beperkingen te incorporeren. Naarmate verbeterde computationele ontwerpen samenkomen met laboratoriumtesten, kunnen zulke methoden helpen om abstracte RNA-blauwdrukken om te zetten in praktische moleculaire instrumenten voor de geneeskunde.
Bronvermelding: Tang, W.Y., Dai, N., Zhou, T. et al. SamplingDesign: RNA design via continuous optimization with coupled variables and Monte-Carlo sampling. Nat Commun 17, 2950 (2026). https://doi.org/10.1038/s41467-025-67901-3
Trefwoorden: RNA-ontwerp, inverse vouwing, Monte Carlo-sampling, continue optimalisatie, mRNA-therapieën