Clear Sky Science · pl
Prognozowanie kradzieży w mieście za pomocą przestrzenno‑czasowego transformera wspieranego LLM
Dlaczego mieszkańcy miast powinni się tym zainteresować
Dla każdego, kto mieszka, pracuje lub robi zakupy w dużym mieście, kradzieże to więcej niż statystyka; wpływają na poczucie bezpieczeństwa na ulicy, w sklepach i w transporcie publicznym. To badanie koncentruje się na Nowym Jorku i stawia praktyczne pytanie: czy można wykorzystać współczesną sztuczną inteligencję, by godzinę po godzinie i blok po bloku wskazywać miejsca, gdzie kradzieże są najbardziej prawdopodobne, nie powielając przy tym starych uprzedzeń policyjnych? Odpowiedź mogłaby pomóc miastom chronić ludzi i mienie, jednocześnie bardziej rozważnie wykorzystując ograniczone zasoby policyjne.
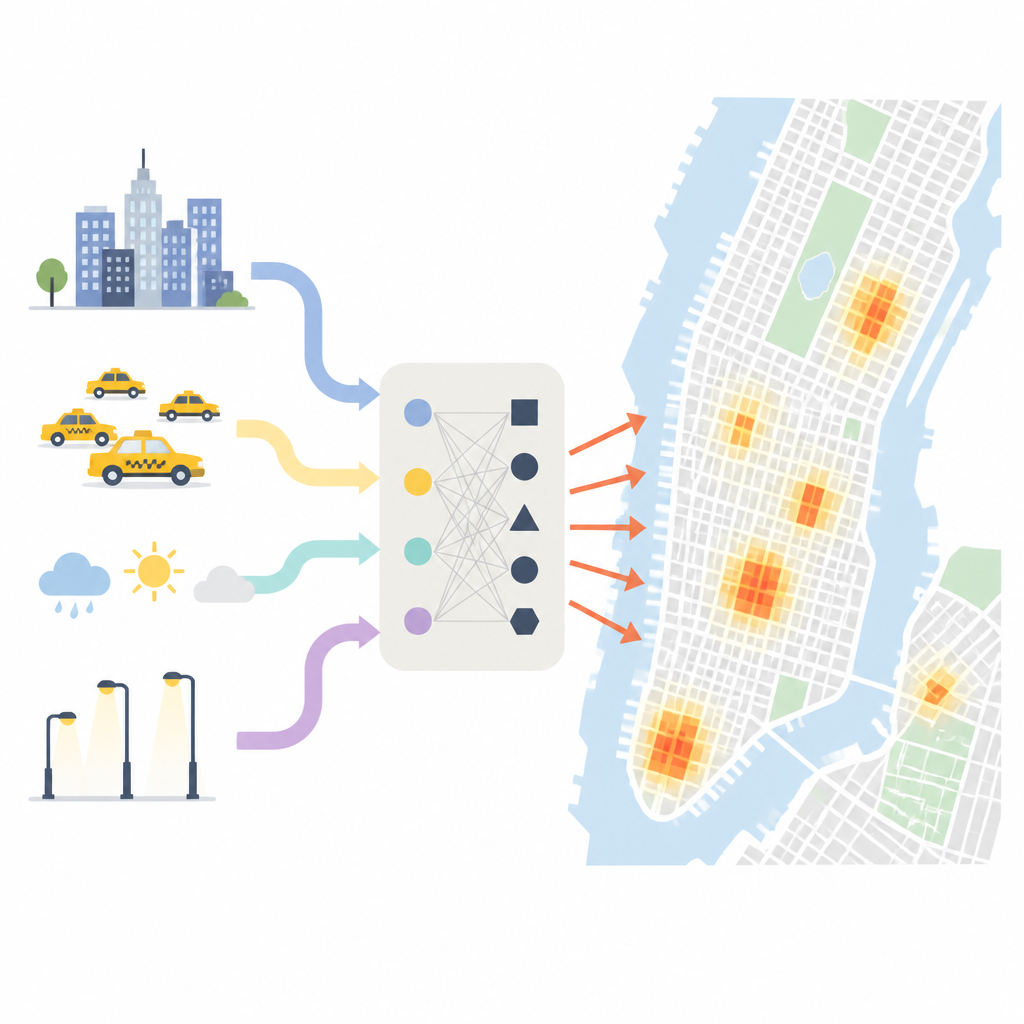
Gdzie i kiedy kradzieże naprawdę się skupiają
Naukowcy zaczynają od pokazania, jak nierównomiernie rozłożone są kradzieże w Nowym Jorku. Przy użyciu drobnej siatki pokrywającej miasto stwierdzają, że niektóre niewielkie obszary doświadczają setek razy więcej kradzieży niż inne. Około połowa wszystkich przypadków kradzieży koncentruje się na niewielkim ułamku bloków miejskich, zwłaszcza w gęstych strefach handlowych, takich jak Midtown Manhattan. Ważny jest też czas w roku i pora dnia: cieplejsze miesiące, okresy zakupów świątecznych i intensywne godziny dojazdów przyciągają więcej ludzi na ulice i do sklepów, tworząc więcej okazji do kradzieży. Pogoda, oświetlenie i typ sąsiedztwa wprowadzają kolejne zmienne — wyraźne, suche noce w tętniących życiem dzielnicach biznesowych wyróżniają się jako szczególnie ryzykowne momenty.
Przekształcanie życia miasta w dane
Aby ująć ten złożony obraz, zespół łączy pięć rodzajów informacji. Wykorzystują szczegółowe policyjne zapisy przeszłych kradzieży, godzinowe odbiory i wysiadki taksówek jako przybliżenie ruchu i gromadzenia się ludzi, mapy sklepów, domów, parków i stacji komunikacji, zdjęcia satelitarne nocnego oświetlenia oraz podstawowe dane pogodowe i spisowe. Na tej podstawie budują dziesiątki wskaźników: jak często przestępstwa powtarzają się w każdej komórce siatki, jak zatłoczone stają się strefy handlowe wczesnym wieczorem, jak ryzyko kradzieży w jednym bloku przenosi się na sąsiednie, oraz jak wskaźniki przestępczości rosną lub maleją wraz ze zmianami opadów czy temperatury. Mierzą też, ile czasu upłynęło od ostatniej kradzieży w danym miejscu — to okazuje się silną wskazówką, czy kolejna kradzież jest prawdopodobna wkrótce.
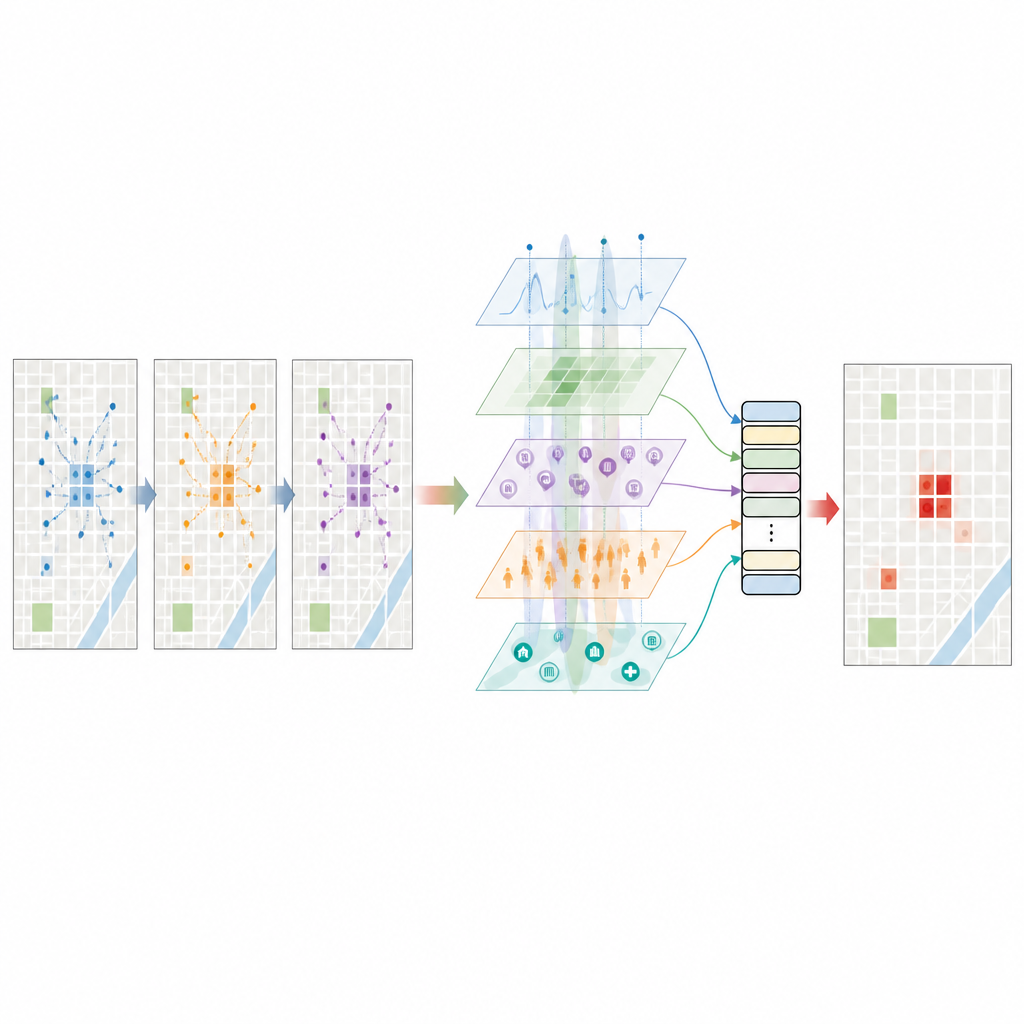
Nadanie modelowi językowemu poczucia miasta
Kluczowym krokiem jest poproszenie dużego modelu językowego o przeczytanie krótkich, ustrukturyzowanych opisów każdego miejsca i momentu: gdzie znajduje się blok, jakie typy miejsc się w nim znajdują, jak jasne jest nocne oświetlenie, ilu pasażerów taksówek właśnie przybyło, jaka jest pogoda i jak często wcześniej zdarzały się tam kradzieże. Model odpowiada szacunkiem ryzyka kradzieży i innymi semantycznymi wskazówkami o tym, jak funkcja, zatłoczenie i czas wzajemnie na siebie wpływają. Te bogate, tekstowe spostrzeżenia są przekształcane w wektory liczbowe i starannie filtrowane, by nie powielały po prostu ustrukturyzowanych danych. Efektem jest wielowymiarowy portret każdej komórki siatki, który odzwierciedla nie tylko surowe liczby, lecz także wzorce, jakie model językowy wyuczył się z szerokiego zakresu tekstów o miastach i przestępczości.
Jak działa silnik predykcyjny
Wszystkie te cechy są podawane na wejście przestrzenno‑czasowemu transformerowi — rodzajowi sieci neuronowej zaprojektowanej do śledzenia wzorców zarówno w przestrzeni, jak i w czasie. Model najpierw ujednolica różne typy cech, a potem stosuje mechanizmy uwagi, które uczą się, które pobliskie bloki i które niedawne godziny mają największe znaczenie dla każdej prognozy. Korzysta też ze wskaźnika ryzyka od modelu językowego jako uprzedniego przekonania i delikatnie koryguje go danymi obserwowanymi, tak by żadna ze stron nie dominowała. Trenowany na kilkuletnich danych z Nowego Jorku, system przewiduje dla każdej komórki siatki i każdej godziny prawdopodobieństwo, że wystąpi co najmniej jedna kradzież. W testach osiąga wysoki poziom dyskryminacji między sytuacjami z kradzieżą i bez niej oraz wynik F1, który odzwierciedla mocną równowagę między wykrywaniem rzeczywistych hotspotów a unikaniem fałszywych alarmów.
Co to oznacza dla codziennego bezpieczeństwa
Dla laika wniosek jest taki, że ryzyko kradzieży nie jest losowe; jest ściśle związane z tym, jak ludzie przemieszczają się po mieście, jak wykorzystywane są różne obszary i jak toczyły się ostatnie wydarzenia. Dzięki połączeniu klasycznych statystyk przestępczości z sygnałami przypominającymi dane na żywo, takimi jak przepływy taksówek i nocne światła, oraz z interpretacyjną siłą modelu językowego, podejście to może wskazać niewielką część bloków i godzin, w których faktycznie koncentruje się wiele kradzieży w mieście. Choć metoda wymaga jeszcze testów w innych miastach i starannej weryfikacji pod kątem równości, wskazuje na narzędzia, które mogłyby pomóc policji i planistom miejskim skupić się na konkretnych, zatłoczonych i wysokiego ryzyka strefach w konkretnych godzinach, zamiast stosować szeroką sieć obejmującą całe dzielnice.
Cytowanie: Tang, M., Wang, J., Bu, X. et al. Urban theft prediction via LLM-empowered spatiotemporal transformer. Sci Rep 16, 15525 (2026). https://doi.org/10.1038/s41598-026-45681-0
Słowa kluczowe: prognozowanie przestępczości miejskiej, hotspoty kradzieży, modelowanie przestrzenno‑czasowe, dynamiczny przepływ populacji, duże modele językowe