Clear Sky Science · es
Predicción de robos urbanos mediante un transformador espaciotemporal potenciado por un LLM
Por qué importa a los habitantes de la ciudad
Para quien vive, trabaja o compra en una gran ciudad, el robo es más que una estadística; influye en cómo nos sentimos de seguros en las calles, en las tiendas y en el transporte público. Este estudio se centra en la ciudad de Nueva York y plantea una pregunta práctica: ¿podemos usar la inteligencia artificial moderna para decir, hora por hora y bloque por bloque, dónde es más probable que ocurra un robo, sin reproducir mecánicamente sesgos policiales históricos? La respuesta podría ayudar a las ciudades a proteger a las personas y los bienes mientras usan con más criterio los limitados recursos policiales.
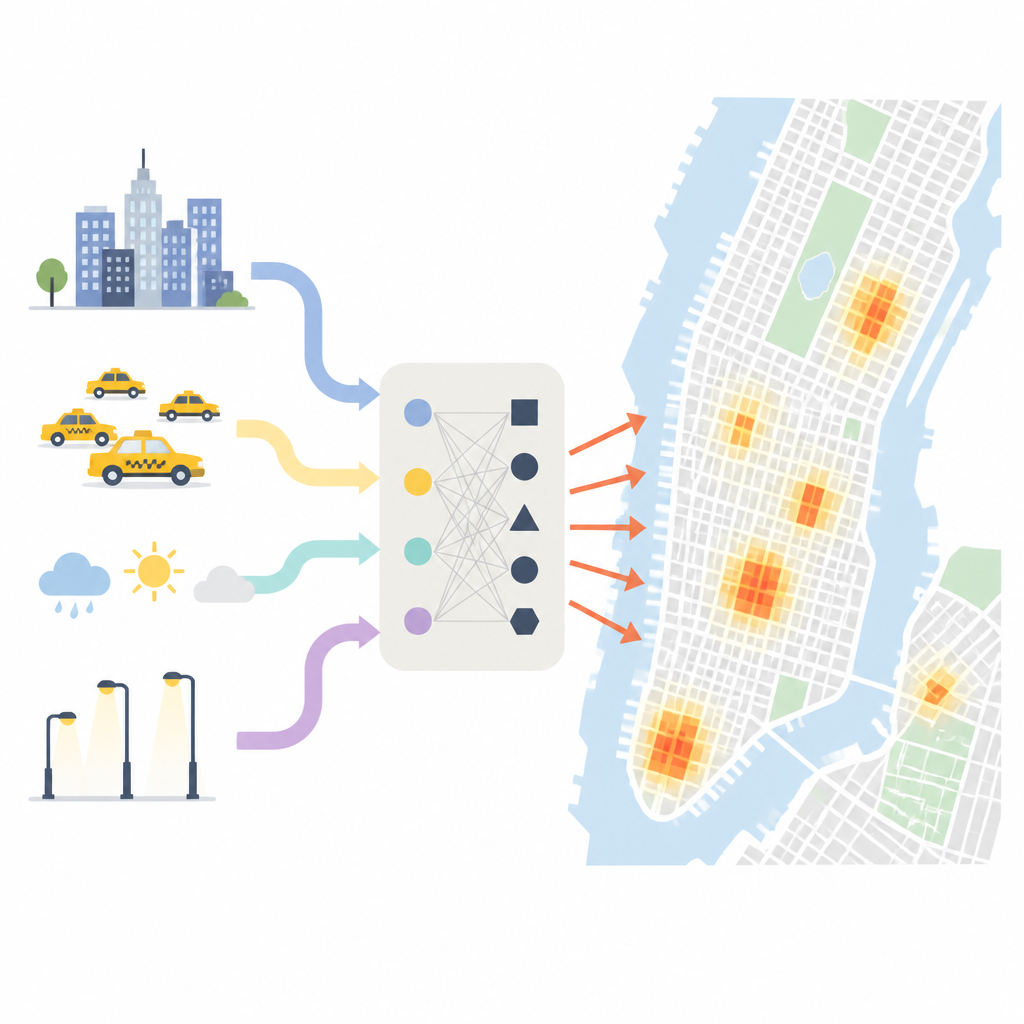
Dónde y cuándo se concentran realmente los robos
Los investigadores comienzan mostrando la distribución desigual de los robos en Nueva York. Usando una malla fina sobre la ciudad, encuentran que algunas áreas pequeñas registran cientos de veces más robos que otras. Alrededor de la mitad de todos los casos de robo se agrupan en una pequeña fracción de bloques, especialmente en zonas comerciales densas como Midtown Manhattan. La época del año y la hora del día también importan: los meses más cálidos, los periodos de compras navideñas y las horas punta de desplazamiento atraen a más personas a calles y comercios, creando más oportunidades para el robo. El clima, la iluminación y el tipo de vecindario introducen además matices: las noches despejadas y secas en distritos comerciales animados destacan como momentos especialmente riesgosos.
Convertir la vida urbana en datos
Para capturar este panorama complejo, el equipo combina cinco tipos de información. Usan registros policiales detallados de robos pasados; subidas y bajadas de taxis por hora como proxy del movimiento y la concentración de personas; mapas de tiendas, viviendas, parques y estaciones de transporte; imágenes satelitales de la iluminación nocturna; y datos básicos meteorológicos y del censo. A partir de esto construyen decenas de indicadores: con qué frecuencia se repiten los delitos en cada celda de la malla, cuán concurridas se ponen las zonas comerciales al anochecer, cómo el riesgo de robo en un bloque se contagia a los vecinos y cómo las tasas de delito suben o bajan con cambios en la lluvia o la temperatura. También miden cuánto tiempo ha pasado desde el último robo en cada lugar, un dato que resulta ser una pista potente sobre la probabilidad de que ocurra otro pronto.
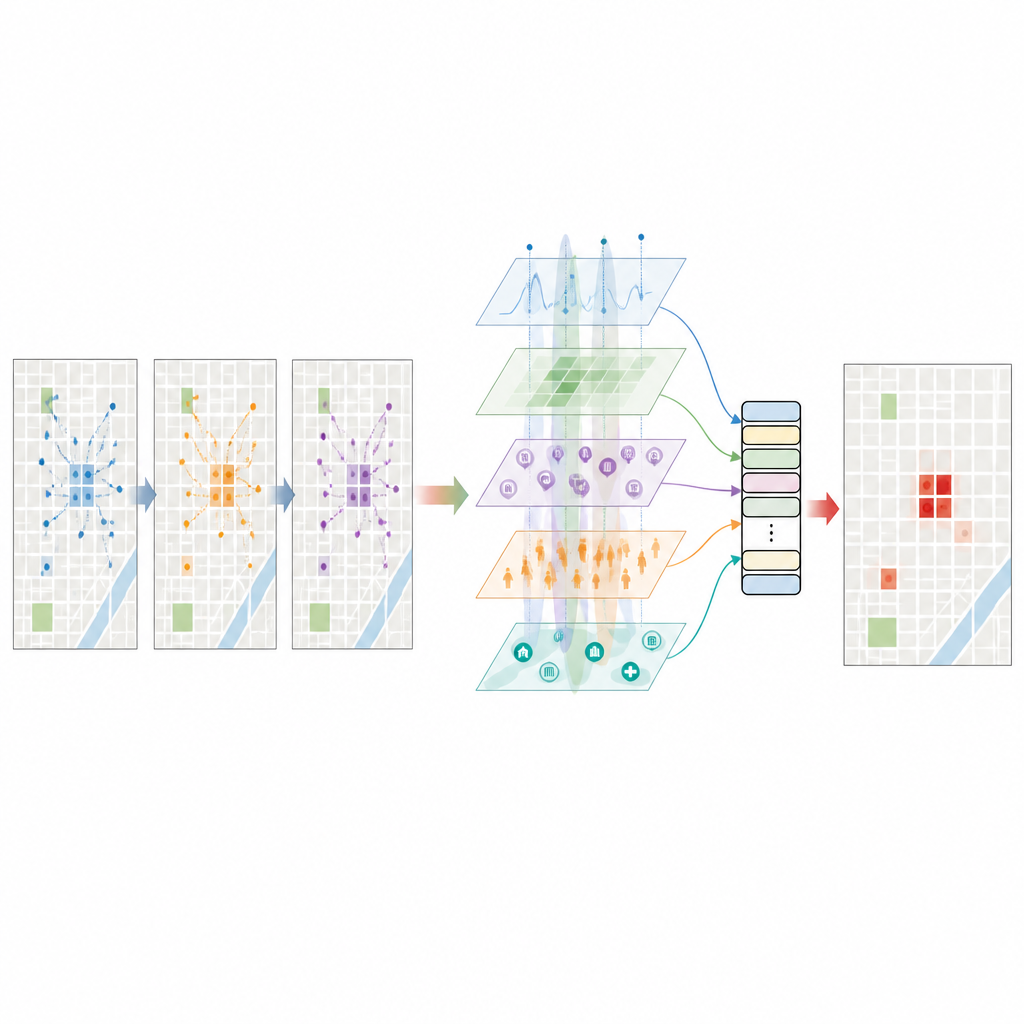
Darle al modelo de lenguaje una noción de la ciudad
Un paso clave consiste en pedir a un gran modelo de lenguaje que lea descripciones breves y estructuradas de cada lugar y momento: dónde está el bloque, qué tipos de locales contiene, cuán brillantes son las luces nocturnas, cuántos pasajeros de taxi acaban de llegar, cómo está el tiempo y con qué frecuencia han ocurrido robos allí antes. El modelo responde con una estimación del riesgo de robo y otras pistas semánticas sobre cómo interactúan la función, la aglomeración y el tiempo. Estos ricos insights en forma de texto se convierten en vectores numéricos y se filtran cuidadosamente para que no dupliquen simplemente los datos estructurados. El resultado es un retrato de alta dimensión de cada celda de la malla que refleja no solo conteos brutos, sino también patrones que el modelo de lenguaje ha aprendido a partir de una amplia gama de textos sobre ciudades y delincuencia.
Cómo funciona el motor de predicción
Todas estas características se alimentan a un modelo transformador espaciotemporal, un tipo de red neuronal diseñada para rastrear patrones a través del espacio y del tiempo. El modelo primero pone en igualdad de condiciones los distintos tipos de características y luego aplica mecanismos de atención que aprenden qué bloques cercanos y qué horas recientes importan más para cada predicción. También utiliza la puntuación de riesgo del modelo de lenguaje como una creencia a priori y la ajusta suavemente con los datos observados, de modo que ninguna de las dos fuentes domine por completo. Entrenado con varios años de datos de Nueva York, el sistema predice, para cada celda de la malla y cada hora, la probabilidad de que ocurra al menos un robo. En las pruebas alcanza un alto nivel de discriminación entre situaciones con y sin robo y una puntuación F1 que refleja un buen equilibrio entre detectar puntos calientes reales y evitar falsas alarmas.
Qué significa esto para la seguridad cotidiana
Para un público general, la conclusión es que el riesgo de robo no es aleatorio; está fuertemente ligado a cómo la gente se desplaza por la ciudad, a cómo se usan las distintas áreas y a cómo se han desarrollado los eventos recientes. Al combinar las estadísticas clásicas del delito con señales casi en tiempo real, como los flujos de taxis y la iluminación nocturna, además del poder interpretativo de un modelo de lenguaje, este enfoque puede señalar una pequeña porción de bloques y horas donde ocurre gran parte de los robos de la ciudad. Aunque el método aún necesita pruebas en otras ciudades y controles cuidadosos de equidad, apunta a herramientas que podrían ayudar a la policía y a los planificadores urbanos a concentrarse en zonas específicas, concurridas y de alto riesgo en momentos concretos, en lugar de lanzar una red amplia sobre barrios enteros.
Cita: Tang, M., Wang, J., Bu, X. et al. Urban theft prediction via LLM-empowered spatiotemporal transformer. Sci Rep 16, 15525 (2026). https://doi.org/10.1038/s41598-026-45681-0
Palabras clave: predicción delictiva urbana, puntos calientes de robos, modelado espaciotemporal, flujo poblacional dinámico, modelos de lenguaje grandes