Clear Sky Science · fr
Prédiction des vols urbains via un transformeur spatiotemporel renforcé par un grand modèle de langage
Pourquoi les citadins devraient s’en préoccuper
Pour toute personne qui vit, travaille ou fait des achats dans une grande ville, le vol n’est pas qu’une statistique ; il influence notre sentiment de sécurité dans la rue, les magasins et les transports en commun. Cette étude porte sur New York et pose une question pratique : peut‑on utiliser l’intelligence artificielle moderne pour dire, heure par heure et pâté de maisons par pâté de maisons, où un vol est le plus susceptible de se produire, sans simplement reproduire d’anciennes biais de police ? La réponse pourrait aider les villes à protéger les personnes et les biens tout en employant les ressources policières limitées de façon plus ciblée.
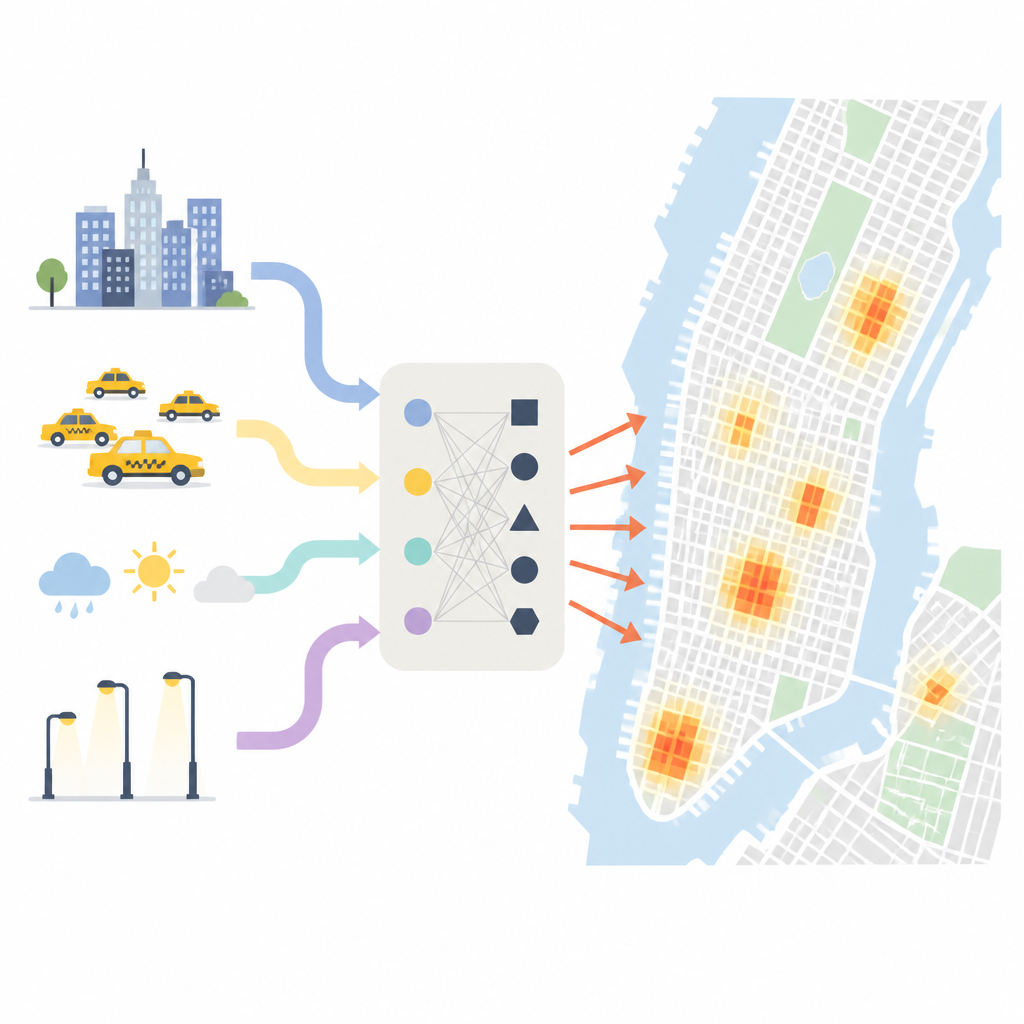
Où et quand les vols se concentrent vraiment
Les chercheurs commencent par montrer à quel point la répartition des vols est inégale à New York. En superposant une grille fine sur la ville, ils observent que certaines petites zones connaissent des volumes de vols des centaines de fois supérieurs à d’autres. Environ la moitié de tous les vols se concentrent dans une infime fraction des pâtés de maisons, notamment dans des zones commerciales denses comme Midtown Manhattan. La période de l’année et l’heure de la journée comptent aussi : les mois chauds, les périodes d’achats de fêtes et les heures de forte affluence créent davantage d’occasions de vol. La météo, l’éclairage et le type de quartier ajoutent d’autres variations, les nuits claires et sèches dans les quartiers d’affaires animés apparaissant comme des moments particulièrement à risque.
Transformer la vie urbaine en données
Pour saisir ce tableau complexe, l’équipe combine cinq types d’informations. Ils utilisent des fiches policières détaillées des vols passés, les prises et déposes de taxis horaires comme indicateur des mouvements et des rassemblements de personnes, des cartes des commerces, logements, parcs et stations, des images satellites des lumières nocturnes, et des données météorologiques et de recensement de base. À partir de cela, ils construisent des dizaines d’indicateurs : la fréquence des récidives dans chaque cellule de la grille, l’intensité d’affluence des zones commerciales en début de soirée, la manière dont le risque de vol dans un pâté de maisons se propage aux voisins, et comment les taux de criminalité montent ou descendent avec les variations de pluie ou de température. Ils mesurent aussi le temps écoulé depuis le dernier vol dans chaque lieu, ce qui s’avère être un indice fort sur la probabilité d’enregistrer un nouveau vol bientôt.
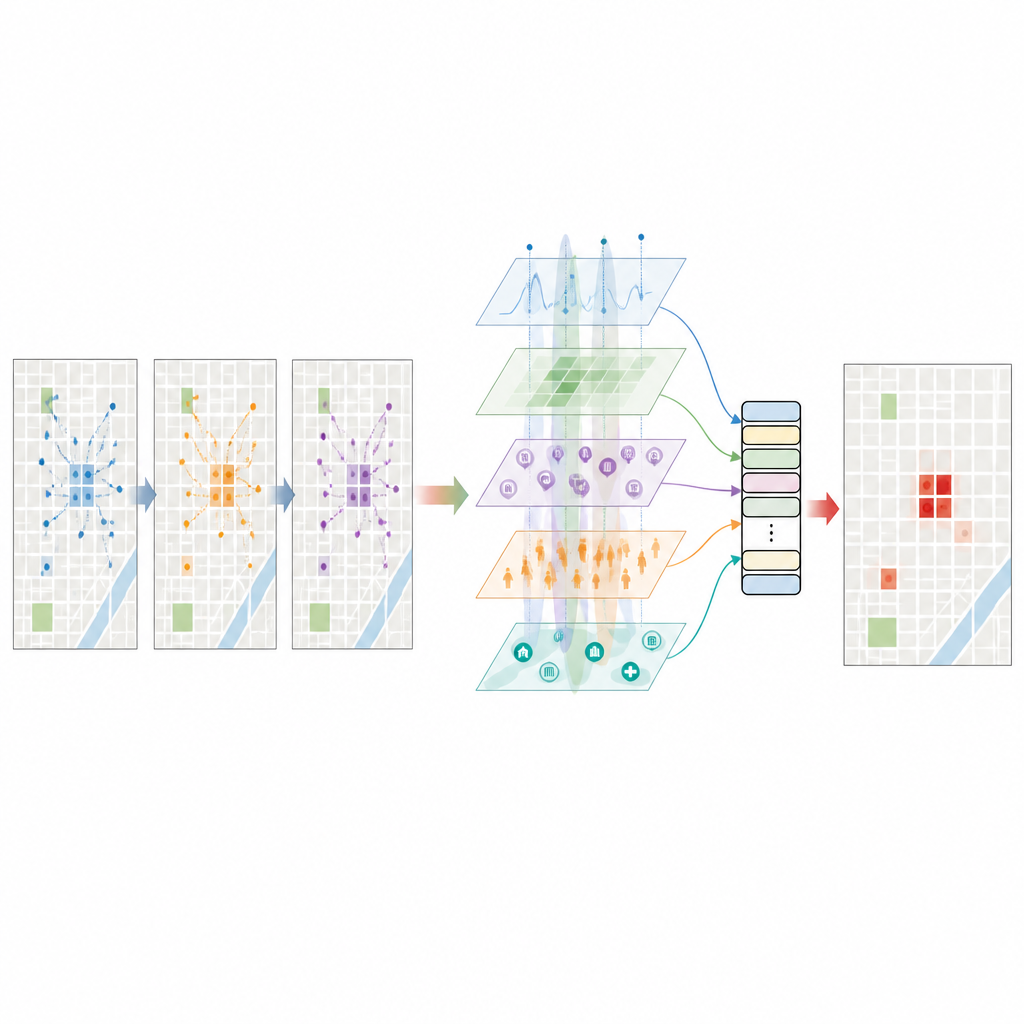
Donner au modèle de langage une perception de la ville
Une étape clé consiste à demander à un grand modèle de langage de lire de courtes descriptions structurées de chaque lieu et instant : où se situe le pâté de maisons, quels types d’établissements il contient, quelle est la luminosité nocturne, combien de passagers de taxi viennent d’arriver, quel temps il fait et à quelle fréquence des vols s’y sont produits auparavant. Le modèle répond ensuite par une estimation du risque de vol et d’autres indices sémantiques sur l’interaction entre fonction, affluence et temporalité. Ces riches informations textuelles sont transformées en vecteurs numériques et filtrées avec soin afin de ne pas simplement dupliquer les données structurées. Le résultat est un portrait haute‑dimension de chaque cellule de la grille qui reflète non seulement des comptes bruts, mais aussi des motifs que le modèle de langage a appris à partir d’un large éventail de textes sur les villes et la criminalité.
Comment fonctionne le moteur de prédiction
Toutes ces caractéristiques sont introduites dans un modèle transformeur spatiotemporel, un type de réseau neuronal conçu pour suivre des motifs à la fois dans l’espace et dans le temps. Le modèle homogénéise d’abord les différents types de caractéristiques, puis applique des mécanismes d’attention qui apprennent quels pâtés de maisons voisins et quelles heures récentes comptent le plus pour chaque prédiction. Il utilise aussi le score de risque fourni par le modèle de langage comme croyance a priori et l’ajuste légèrement à la lumière des données observées, de sorte qu’aucune des deux composantes ne domine l’autre. Entraîné sur plusieurs années de données new‑yorkaises, le système prédit, pour chaque cellule de la grille et chaque heure, la probabilité qu’au moins un vol ait lieu. Lors des tests, il atteint un niveau élevé de discrimination entre situations avec et sans vol et un score F1 reflétant un bon équilibre entre la détection des vrais points chauds et l’évitement des fausses alertes.
Ce que cela signifie pour la sécurité quotidienne
Pour un non‑spécialiste, l’essentiel est que le risque de vol n’est pas aléatoire ; il est étroitement lié à la façon dont les personnes circulent dans la ville, à l’usage des espaces et au déroulement des événements récents. En mariant les statistiques classiques de la criminalité à des signaux proches du temps réel, comme les flux de taxis et les lumières nocturnes, et à la puissance interprétative d’un modèle de langage, cette approche peut signaler une petite part de pâtés de maisons et d’heures où se produisent réellement une grande partie des vols de la ville. Bien que la méthode doive encore être testée dans d’autres villes et soumise à des contrôles rigoureux d’équité, elle ouvre la voie à des outils pouvant aider la police et les urbanistes à cibler des zones denses et à risque à des moments précis, plutôt que d’étendre une surveillance à l’ensemble d’un quartier.
Citation: Tang, M., Wang, J., Bu, X. et al. Urban theft prediction via LLM-empowered spatiotemporal transformer. Sci Rep 16, 15525 (2026). https://doi.org/10.1038/s41598-026-45681-0
Mots-clés: prédiction de la criminalité urbaine, points chauds de vols, modélisation spatiotemporelle, flux de population dynamique, grands modèles de langage