Clear Sky Science · nl
Voorspellen van stedelijke diefstal via LLM-ondersteunde ruimtetijdelijke transformer
Waarom stadsbewoners dit aangaat
Voor wie in een grote stad woont, werkt of winkelt, is diefstal meer dan een statistiek; het beïnvloedt hoe veilig we ons voelen op straat, in winkels en in het openbaar vervoer. Deze studie richt zich op New York City en stelt een praktische vraag: kunnen we moderne kunstmatige intelligentie gebruiken om uur voor uur en blok voor blok te voorspellen waar diefstal het meest waarschijnlijk is, zonder louter bestaande politievooroordelen te reproduceren? Het antwoord zou steden kunnen helpen mensen en eigendommen te beschermen en tegelijk schaarse politiebronnen zorgvuldiger in te zetten.
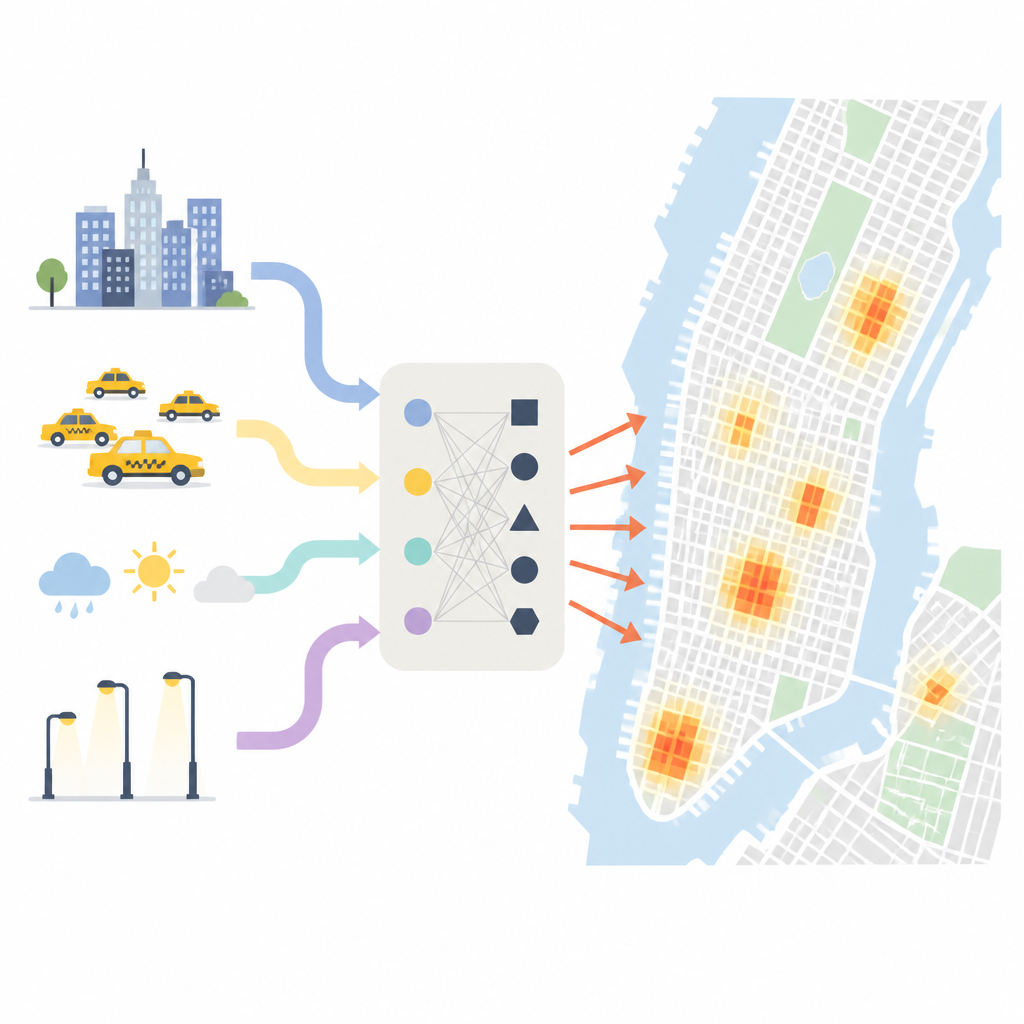
Waar en wanneer diefstal echt samenkomt
De onderzoekers beginnen met te laten zien hoe ongelijk verdeeld diefstal over New York is. Met een fijn raster over de stad vinden zij dat sommige kleine gebieden honderden malen meer diefstal zien dan andere. Ongeveer de helft van alle diefstallen is geconcentreerd in een piepklein deel van de stadsblokken, vooral in dichtbevolkte commerciële zones zoals Midtown Manhattan. Tijd van het jaar en tijdstip van de dag zijn ook van belang: warmere maanden, periodes met feestelijk winkelen en drukke spitsuren brengen meer mensen op straat en in winkels, en creëren meer kansen voor diefstal. Weer, verlichting en type buurt voegen extra variatie toe, waarbij heldere, droge nachten in levendige zakendistricten als bijzonder risicovolle momenten naar voren komen.
Het stadsleven omzetten in data
Om dit complexe beeld vast te leggen combineert het team vijf soorten informatie. Ze gebruiken gedetailleerde politierapporten van eerdere diefstallen, uur-tot-uur taxi-opstap- en uitstappunten als afspiegeling van hoe mensen zich verplaatsen en verzamelen, kaarten van winkels, woningen, parken en metrostations, satellietbeelden van nachtelijke verlichting, en basisweer- en volkstellingsgegevens. Hieruit bouwen ze tientallen indicatoren: hoe vaak misdrijven zich herhalen in elk rastervak, hoe druk commerciële zones worden aan het begin van de avond, hoe het diefstrisico in een blok doorvloeit naar de buren, en hoe misdaadcijfers stijgen of dalen met verschuivingen in neerslag of temperatuur. Ze meten ook hoe lang het geleden is sinds de laatste diefstal op elke plek, wat blijkt een sterke aanwijzing te zijn of er binnenkort weer een kan plaatsvinden.
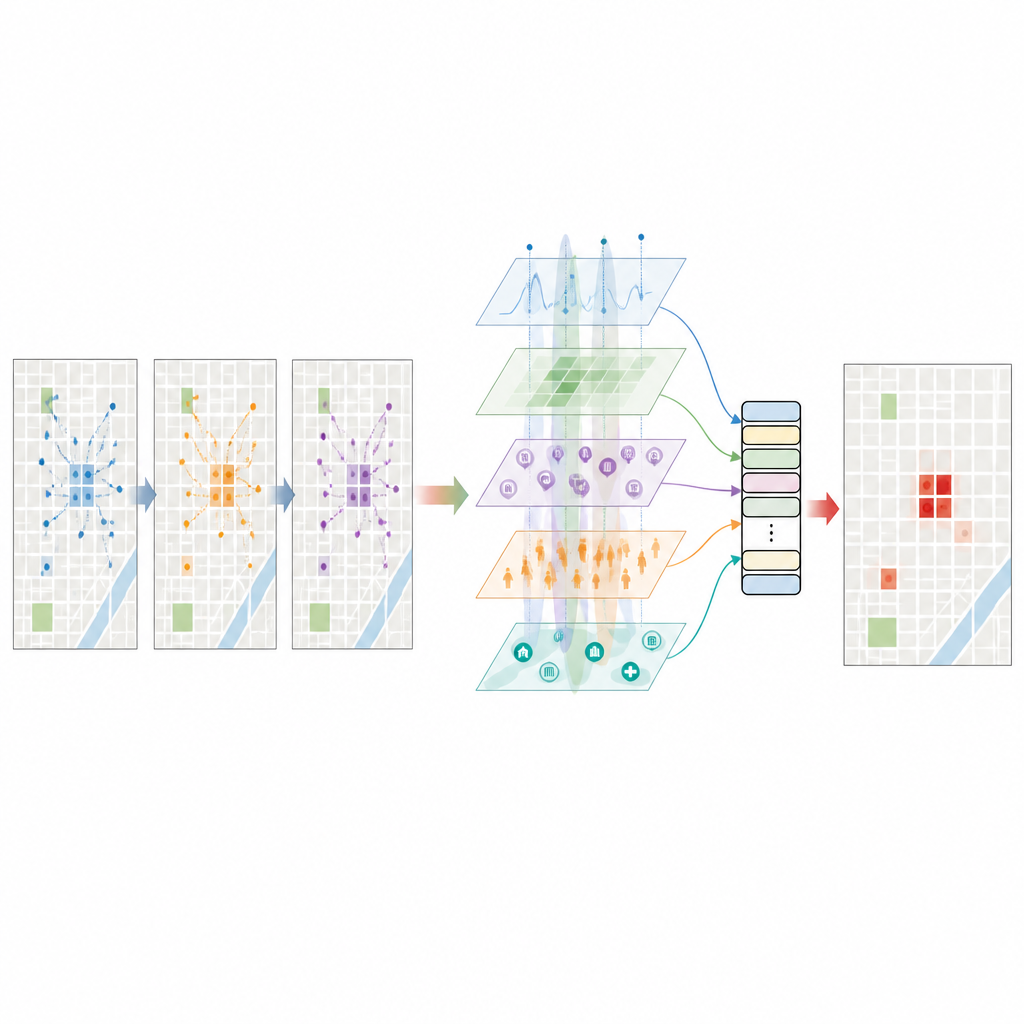
Het taalmodel een gevoel voor de stad geven
Een sleutelstap is het vragen aan een groot taalmodel om korte, gestructureerde beschrijvingen van elke plek en elk moment te lezen: waar het blok ligt, wat voor soorten voorzieningen het bevat, hoe helder de nachtverlichting is, hoeveel taxipassagiers zojuist zijn aangekomen, hoe het weer is, en hoe vaak daar eerder diefstallen zijn voorgevallen. Het model reageert vervolgens met een geschat diefstrisico en andere semantische aanwijzingen over hoe functie, drukte en tijd samenhangen. Deze rijke, tekstgebaseerde inzichten worden omgezet in numerieke vectoren en zorgvuldig gefilterd zodat ze niet simpelweg de gestructureerde data dupliceren. Het resultaat is een hoogdimensionaal portret van elk rastervak dat niet alleen ruwe tellingen weerspiegelt, maar ook patronen die het taalmodel heeft geleerd uit een breed scala aan teksten over steden en misdaad.
Hoe de voorspellingsmotor werkt
Al deze kenmerken worden ingevoerd in een ruimtetijdelijke transformer, een type neuraal netwerk dat is ontworpen om patronen over zowel ruimte als tijd te volgen. Het model brengt eerst verschillende featuretypes op één niveau, en past dan aandachtmechanismen toe die leren welke nabijgelegen blokken en welke recente uren het meest van belang zijn voor elke voorspelling. Het gebruikt ook de risicoscore van het taalmodel als een voorafgaande inschatting en past die voorzichtig aan met de waargenomen data, zodat noch het ene noch het andere domineert. Getraind op meerdere jaren aan New York-data voorspelt het systeem voor elk rastervak en elk uur de kans dat ten minste één diefstal zal plaatsvinden. In tests bereikt het een hoog niveau van discriminatie tussen diefstal- en niet-diefstalsituaties en een F1-score die een sterke balans weergeeft tussen het vangen van echte hotspots en het vermijden van valse alarmen.
Wat dit betekent voor alledaagse veiligheid
Voor leken is de kernboodschap dat diefstrisico niet willekeurig is; het is nauw verbonden met hoe mensen zich door de stad bewegen, hoe verschillende gebieden worden gebruikt en hoe recente gebeurtenissen zich hebben ontvouwd. Door klassieke misdaadstatistieken te mengen met live-achtige signalen zoals taxistromen en nachtverlichting, plus de interpreterende kracht van een taalmodel, kan deze aanpak een klein deel van de blokken en uren markeren waar een groot deel van de stedelijke diefstal zich echt voordoet. Hoewel de methode nog in andere steden getest moet worden en zorgvuldige controles op eerlijkheid vereist zijn, wijst het naar instrumenten die politie en stadsplanners zouden kunnen helpen zich te richten op specifieke drukke, hoogrisicozones op specifieke tijden, in plaats van een breed net uit te werpen over hele buurten.
Bronvermelding: Tang, M., Wang, J., Bu, X. et al. Urban theft prediction via LLM-empowered spatiotemporal transformer. Sci Rep 16, 15525 (2026). https://doi.org/10.1038/s41598-026-45681-0
Trefwoorden: voorspelling stedelijke misdaad, diefstal-hotspots, ruimtetijdelijke modellering, dynamische bevolkingsstromen, grote taalmodellen